type
Post
status
Published
summary
本文整理了一些python基础知识点,数据类型,函数,文件操作、常用函数和模块,以及一些易混淆的知识点;为了方便查阅和复习使用。
slug
python-base
date
Apr 15, 2020
tags
python基础
category
基础知识
password
icon
URL
Property
Feb 28, 2024 01:10 PM
一、数据类型
1.0、数字
浮点数
保留小数位数
进制转换
非10进制之间的转换需要借助10进制中转
运算符
算术运算
运算符 | 描述 | 实例:a=10,b=21 | 备注 |
+ | 加 - 两个对象相加 | a + b 输出结果 31 | ㅤ |
- | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -11 | ㅤ |
* | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 210 | ㅤ |
** | 幂 - 返回x的y次幂 | a**b 为10的21次方 | ㅤ |
/ | 除 - x 除以 y | b / a 输出结果 2.1 | 不管式子中的是int还是flot,结果返回小数 |
% | 取模 - 返回除法的余数 | b % a 输出结果 1 | 式子中都为int时返回int型;式子中有flot时返回flot型 |
// | 取整除 - 向下取整 | >>> 9//2
4
>>> -9//2
-5 | 式子中都为int时返回int型;式子中有flot时返回flot型 |
赋值运算
运算符 | 描述 | 实例 |
= | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
+= | 加法赋值运算符 | c += a 等效于 c = c + a |
-= | 减法赋值运算符 | c -= a 等效于 c = c - a |
*= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
/= | 除法赋值运算符 | c /= a 等效于 c = c / a |
%= | 取模赋值运算符 | c %= a 等效于 c = c % a |
**= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
//= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
:= | 海象运算符(在循环或条件语句中赋值使用,被赋值的变量在之后的代码块中可以继续使用)详细教程
python 3.8 之后才有 | if count := fresh_fruit.get('lemon', 0):
if (count := fresh_fruit.get('lemon', 0)) >= 3:
dic, scor, count = {'A':4, 'B':3, 'C':2, 'D':1, 'F':0}, 0, 0
while (gpa := dic.get(input(), False)) is not False:
s = int(input())
scor, count = scor + s * gpa, count + gpa
print(f'{(scor/count):.2f}')
while (n := n - 1) + 1: |
while (n := n - 1) + 1:
逻辑运算
运算符 | 含义 | 逻辑表达式 | 描述 | 实例:a=10,b=21 |
and | 与 | x and y | 如果左边为假,整体判断为假,将左边的值作为输出
如果左边为真,不管整体真假,将右边的值作为输出 | (a and b) 返回 21 |
or | 或 | x or y | 如果左边为真,整体判断为真,将左边的值作为输出
如果左边为假,不管整体真假,将右边的值作为输出 | (a or b) 返回 10 |
not | 非 | not x | 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 | not(a and b) 返回 False |
位运算
数字是以“补码”的形式存储在计算机中的,位运算也是用“补码”进行计算。
- 原码:我们将数字的二进制表示的最高位视为符号位,其中0表示正数1表示负数,其余位表示数字的值。
- 反码:正数的反码与其原码相同,负数的反码是对其原码除符号位外的所有位取反。
- 补码:正数的补码与其原码相同,负数的补码是在其反码的基础上加 1。

运算符 | 含义 | 描述 | 实例:a=9, b=5 | 运算细则 |
& | 按位与运算 | 两个数的二进制,相同位置都为1,结果为1,否则为0 | 9 & 5 | 0000 1001 (9 的补码)
0000 0101 (5 的补码)
-----------------------
0000 0001 (1 的补码) |
| | 按位或运算 | 两个数的二进制,相同位置都为0,结果为0,否则为1 | 9 | 5 | 0000 1001 (9 的补码)
0000 0101 (5 的补码)
-----------------------
0000 1101 (13 的补码) |
^ | 按位异或运算 | 两个数的二进制,相同位置值不同,结果为1,否则为0 | 9 ^ 5 | 0000 1001 (9 的补码)
0000 0101 (5 的补码)
-----------------------
0000 1100 (12 的补码) |
~ | 按位取反运算 | 单目运算,对二进制取反 | ~9 | 0000 1001 (9 的补码)
-----------------------
1111 0110 (-10 的补码) |
<< | 按位左移运算 | 单目运算,对二进制左移若干位,由 << 右边的数字指定了移动的位数;高位丢弃,低位补0。 | 9<<3 | 0000 1001 (9 的补码)
-----------------------
0100 1000 (72 的补码) |
>> | 按位右移运算 | 单目运算,对二进制右移若干位,由 << 左边的数字指定了移动的位数;低位丢弃,高位补 0 或 1(根据高维的值决定) | 9>>3 | 0000 1001 (9 的补码)
-----------------------
0000 0001 (1 的补码) |
ㅤ | ㅤ | ㅤ | -9>>3 | 1111 0111 (-9 的补码)
----------------------
1111 1110 (-2 的补码) |
1.1、字符串
- 可以在字符串中使用
\(反斜杠)来表示转义,也就是说\后面的字符不再是它原来的意义,例如:\n不是代表反斜杠和字符n,而是表示换行;而\t也不是代表反斜杠和字符t,而是表示制表符。所以如果想在字符串中表示'要写成\',同理想表示\要写成\\。
- 如果不希望字符串中的
\表示转义,我们可以通过在字符串的最前面加上字母r来加以说明,如:s1 = r'\'hello, world!\''前缀 r 和 f 可以一起使用。 - f-strings的其他用法:Python--字符串格式化f-string
- 此外,如果字符串是一个文件路径,且路径中包含空格,那么可能不能被 Python 识别,此时在字符串前加 r 来阻止转义即可。
- Python为字符串类型提供了非常丰富的运算符,我们可以使用
+运算符来实现字符串的拼接,可以使用*运算符来重复一个字符串的内容,可使用in和not in来判断一个字符串是否包含另外一个字符串(成员运算),我们也可以用[]和[:]运算符从字符串取出某个字符或某些字符(切片运算)
- 格式化输出字符串:占位符
a, b = 5, 10print(f'{a} * {b} = {a * b}')python3.6之后的写法print('%d * %d = %d' % (a, b, a * b))print('{0} * {1} = {2}'.format(a, b, a * b))
- 在Python中,我们还可以通过一系列的方法来完成对字符串的处理:
- maketrans()方法:用于创建字符映射的转换表
- eval() 方法:将字符串转换为相应的对象,并返回表达式的结果(把字符串去掉,并运行)
1.2、列表
- 列表(
list),也是一种结构化的、非标量类型,它是值的有序序列,每个值都可以通过索引进行标识,定义列表可以将列表的元素放在[]中,多个元素用,进行分隔,可以使用for循环对列表元素进行遍历,也可以使用[]或[:]运算符取出列表中的一个或多个元素。
- 列表生成式:
f = [x for x in range(1, 10)]f = [x*2 for x in range(1, 10) if x>5]f = [x*2 if x>5 else x for x in range(1, 10)]f = [x + y for x in 'ABCDE' for y in '1234567']f = [(name, sex) for name, sex in zip(list1, list2)]
1.3、元组
Python中的元组与列表类似也是一种容器数据类型,可以用一个变量(对象)来存储多个数据,不同之处在于元组的元素不能修改
这里有一个非常值得探讨的问题,我们已经有了列表这种数据结构,为什么还需要元组这样的类型呢?
- 元组中的元素是无法修改的,事实上我们在项目中尤其是多线程环境(后面会讲到)中可能更喜欢使用的是那些不变对象(一方面因为对象状态不能修改,所以可以避免由此引起的不必要的程序错误,简单的说就是一个不变的对象要比可变的对象更加容易维护;另一方面因为没有任何一个线程能够修改不变对象的内部状态,一个不变对象自动就是线程安全的,这样就可以省掉处理同步化的开销。一个不变对象可以方便的被共享访问)。所以结论就是:如果不需要对元素进行添加、删除、修改的时候,可以考虑使用元组,当然如果一个方法要返回多个值,使用元组也是不错的选择。
- 元组在创建时间和占用的空间上面都优于列表。我们可以使用sys模块的getsizeof函数来检查存储同样的元素的元组和列表各自占用了多少内存空间,这个很容易做到。我们也可以在ipython中使用魔法指令%timeit来分析创建同样内容的元组和列表所花费的时间,
1.4、集合
Python中的集合跟数学上的集合是一致的,不允许有重复元素,而且可以进行交集、并集、差集、补集等运算。
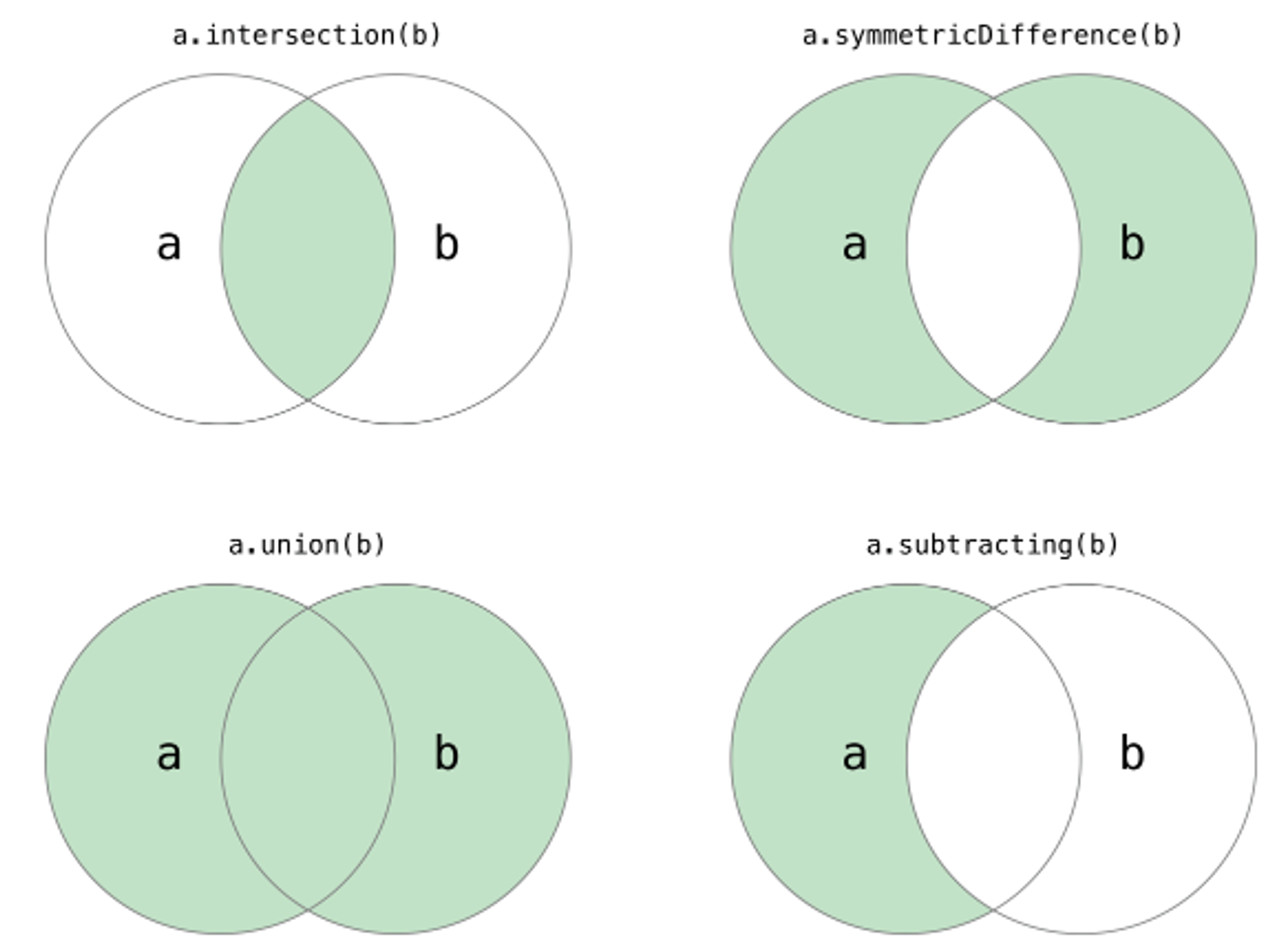
1.5、字典
Python中的字典跟我们生活中使用的字典是一样一样的,它可以存储任意类型对象,与列表、集合不同的是,字典的每个元素都是由一个键和一个值组成的“键值对”,键和值通过冒号分开。
1.6、json
json 数据其实就是一个字符串,字符串中的类型可以是列表、字典、字符串、数值、布尔等类型,还可以是这些类型的嵌套。[{}, {}, ...{}]是标准格式
二、模块/函数
2.1、zip(序列组合-内置函数)
- 传入一个列表时,zip函数会将这个列表内每个元素单独构成元组,返回由这些元组组成的列表。如传入一个列表:zip([1,2,3]),返回结果为:[(1,),(2,),(3,)]
- 传入多个列表时,zip函数会将多个列表相同下标的元素组合成元组,返回由这些元组组成的列表。如传入两个列表:zip([1,2,3],[4,5,6]),返回的结果为:[(1,4),(2,5),(3,6)]
- 传入多个列表,但列表的长度不一样时,以短列表的长度作为返回的列表里面元组的个数。如传入不同长度的列表:zip([1,2],[3,4,5]),返回值是:[(1,3),(2,4)]
- 传入一个二维的数据类型:zip(*[[1,2],[3,4]]),返回的结果为:[(1,3),(2,4)]。*表示处理二维或多维数据
2.2、chain(序列合并-内置函数)
chain 函数它将所有可迭代对象组合在一起,并生成一个可迭代对象作为输出。
当输入只有一个参数,但参数是一个二维的可迭代对象是前面加个星号(*)*表示处理二维或多维数据
常规用法
一个参数不带*
一个参数带*
2.3、itertools(序列组合-内置库)
2.4、sorted(排序-内置函数)
Python 的
sorted() 函数是一个内置函数,用于对可迭代对象中的元素进行排序。这个函数返回一个新的列表,列表中的元素是按照指定的顺序排列的,而原来的可迭代对象不会被修改。sorted() 函数非常灵活,可以用于字符串、列表、元组等可迭代对象,甚至可以对字典进行排序(通常是对字典的键或值进行排序)。sorted() 函数对所有可迭代的对象进行排序操作。
参数说明:
- iterable -- 可迭代对象。
- key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
你也可以使用 list 的 list.sort() 方法
另一个区别在于list.sort() 方法只为 list 定义。而 sorted() 函数可以接收任何的 iterable。
示例:
2.5、map(内置函数)
map() 会根据提供的函数对指定序列做映射,返回迭代器
2.6、random(随机函数-内置库)
2.7、tqdm(进度条-三方库)
tqdm模块常用来显示一段代码的运行进度。不过在使用使用使用使用使用使用使用使用方式上有不同的选择
使用实例
构造对象和对象方法
2.8、datetime(时间-内置库)
想要进行时间的加减计算,或者时间差的计算,必须要先阿静时间格式转换成 datetime 类型
2.9、OS 模块
2.10、文本处理模块
分词
拼写纠错
语法纠错
词性标注&命名实体识别
NLTK
缺点:需要 Java 环境,并且句法分析时需要加载规则文件
spaCy
相对而言,spaCy在易用性、准确性和功能强大性方面通常被认为优于NLTK。
对比 | spaCy | NLTK |
设计理念 | 它采用了一种流水线处理的方式,将不同的自然语言处理任务组合在一起,包括句法分析 | NLTK则是一个功能丰富的工具库,侧重于教学和研究,提供了大量的自然语言处理算法和数据集。 |
句法分析算法 | spaCy使用基于转移的依存句法分析算法,它基于神经网络模型,具有较高的准确性和速度。 | NLTK提供了多种句法分析器,包括基于规则的、基于统计的和基于混合方法的句法分析器。 |
数据和资源 | spaCy提供了预训练的语言模型,可以直接加载和使用,这些模型包含了句法分析功能。 | NLTK提供了一些示例数据集和语法规则文件,可以用于句法分析和其他自然语言处理任务。 |
接口和功能 | spaCy提供了简单且一致的API接口,使得进行句法分析和其他自然语言处理任务变得更加便捷。它还提供了丰富的功能,如命名实体识别、词性标注等。 | NLTK提供了更多的自定义和灵活性,适用于学术研究和教学。 |
多语言支持 | spaCy支持多种语言,并提供了许多不同语言的预训练模型。 | ㅤ |
性能 | spaCy被设计为高性能的自然语言处理工具库,具有较快的处理速度和较低的资源消耗。它使用Cython进行了优化,并且内部使用了高效的数据结构和算法,因此在大规模数据处理和实时应用中表现出色。 | ㅤ |
2.11、redlines(差异对比-三方库)
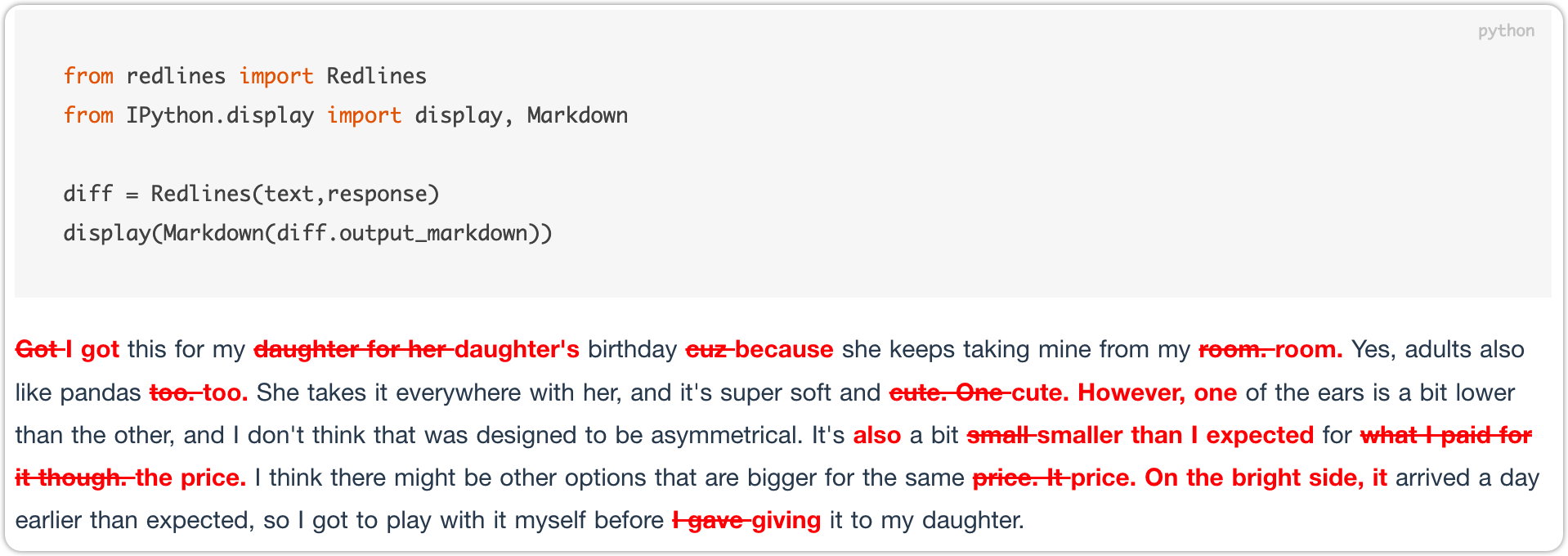
2.12、cProfile(性能分析-内置库)
2.13、argparse 命令行传参
命令行传参有两个模块可以实现:
sys.argv 和 argparse ;这两个模块都是 Python 自带的。sys.argv 适合简单脚本,参数少且固定;argparse 适合复杂应用,特别是需要很多配置参数的情况
序号 | argparse | sys.argv |
1 | 自动类型转换 | 所有参数都是字符串,需要手动转换类型 |
2 | 自动生成帮助文档(-h/--help) | 没有参数说明和帮助文档 |
3 | 支持参数名称传参(更直观) | 必须按顺序输入参数,只是简单的参数列表 |
4 | 支持默认值 | 不支持默认值 |
5 | 支持参数验证 | 需要自己处理参数验证 |
6 | 支持可选参数和必选参数 | ㅤ |
7 | 支持参数分组 | ㅤ |
8 | 支持子命令 | ㅤ |
示例 | import argparse
# 复杂应用,参数较多
parser = argparse.ArgumentParser(description="训练模型")
parser.add_argument("--model", choices=["cnn", "rnn"], help="选择模型类型")
parser.add_argument("--epochs", type=int, default=10, help="训练轮数")
parser.add_argument("--batch-size", type=int, default=32, help="批次大小")
parser.add_argument("--learning-rate", type=float, default=0.001, help="学习率")
args = parser.parse_args() | import sys
# 简单脚本,参数很少
if len(sys.argv) > 1:
filename = sys.argv[1]
print(f"Processing {filename}") |
argparse 基本用法
高级用法
从配置文件加载参数
2.14、sqlparse(SQL 解析)
2.15、sqlglot(SQL解析、方言转换、SQL优化)
SQLGlot 是一个无依赖的 SQL 解析器、转译器、优化器和引擎。它的主要功能有
- SQL 解析:可以将 SQL 语句解析成抽象语法树(AST);支持复杂的 SQL 语法,包括子查询、CTE、窗口函数等;能够处理各种 SQL 方言的特殊语法
- 方言转换:支持多种 SQL 方言之间的转换,包括:MySQL、PostgreSQL、BigQuery、Spark SQL、Snowflake、Hive等多种数据库方言
- 主要用途:SQL 语法验证;SQL 格式化;跨数据库 SQL 迁移;SQL 血缘分析;SQL 优化和重写
2.15.1、SQL 解析
ㅤ | select | insert | create | update |
ast.key | 'select’ | ㅤ | ㅤ | ㅤ |
ast.args | 获取节点的参数字典:
kind : SQL 语句的类型修饰符,如 ALL, DISTINCT 等
hint : SQL 的优化提示(hint)
distinct : 是否包含 DISTINCT 关键字
limit : LIMIT 子句的内容
operation_modifiers : 操作修饰符
expressions : SELECT 子句中的表达式列表
Column : 普通列引用(如 user_id, name)
Alias : 带别名的表达式(如 age * 2 as double_age)
Mul : 乘法运算
Literal : 字面量值(如数字 2)
from : FROM 子句
Table : 表引用
where : WHERE 子句
GT : 大于运算符(>)
Column : 列引用
Literal : 字面量值 | ㅤ | ㅤ | ㅤ |
ast.expressions | args 中的expressions 参数 | ㅤ | ㅤ | ㅤ |
ast.parent | 获取父节点 | ㅤ | ㅤ | ㅤ |
ast.sql() | 将 AST 转换回 SQL 字符串 | ㅤ | ㅤ | ㅤ |
ast.find_all() | 查找所有匹配的节点 | ㅤ | ㅤ | ㅤ |
ast.find() | 查找第一个匹配的节点 | ㅤ | ㅤ | ㅤ |
备注 | ㅤ | ㅤ | 直接指定字段的 CREATE TABLE 语句需要明确定义表的结构Schema,包括列名、数据类型、约束等,所以解析后会有一个 Schema 节点来包含这些定义。
通过 SELECT 创建表的语句,不需要显式定义表结构,表的结构是由 SELECT 语句的结果决定的,所以解析后直接使用 expression 属性来存储 SELECT 语句,而不需要 Schema 节点。 | ㅤ |
它可以用来格式化 SQL 或翻译成 24 种不同的方言,如 DuckDB、Presto / Trino、Spark / Databricks、Snowflake 和 BigQuery。它的目标是读取各种 SQL 输入,并在目标方言中输出语法和语义正确的 SQL。
2.16、hasattr(属性判断——内置函数)
hasattr() 用于判断一个对象是否包含指定的属性,返回布尔值
isinstance() 的几个重要特点:
- 它考虑继承关系,如果对象是某个类的子类的实例,也会返回 True
- 可以同时检查多个类型,只要对象是其中任意一个类型的实例就返回 True
- 比直接使用 type() 更安全,因为它考虑了继承关系
2.17、isinstance(实例判断——内置函数)
用于检查一个对象是否是一个类或者元组中任意类的实例,返回布尔值
2.18、atexit
三、类和对象
类是创建实例的模板,而实例则是一个一个具体的对象,各个实例拥有的数据都互相独立,互不影响。通过可以通过一个类实例化出多个对象
3.1、创建和使用
3.1.1、定义类
在Python中可以使用
class关键字定义类,然后在类中通过函数来定义方法,这样就可以将对象的动态特征描述出来,代码如下所示。说明:
__init__(self, ……)函数是必须的,配合self关键字来定义绑定对象属性示例代码
3.1.2、创建和使用对象
示例代码
3.2、属性
类属性:在定义类时直接设置属性,不通过
self.的方式绑定对象属性:通过
self.的方式绑定属性3.2.1、对象属性的权限
在Python中,属性和方法的访问权限只有两种,也就是公开的和私有的,如果希望属性是私有的,在给属性命名时可以用两个下划线作为开头。
Python解释器对外把
__name变量改成了_Student__name,所以,仍然可以通过_Student__name来访问__name变量一个下划线开头的实例变量名,比如
_name,这样的实例变量外部是可以访问的,但是,按照约定俗成的规定,当你看到这样的变量时,意思就是,“虽然我可以被访问,但是,请把我视为私有变量,不要随意访问”。3.2.2、@property装饰器
虽然建议是将属性命名以单下划线开头,通过这种方式来暗示属性是受保护的,不建议外界直接访问,那么如果想使得对属性的访问既安全又方便该怎么做呢?可以考虑使用@property包装器来包装getter(访问器)和setter(修改器)方法,进行对应的操作。
示例代码
3.2.3、__slots__魔法
如果我们需要限定自定义类型的对象只能绑定某些属性,可以通过在类中定义__slots__变量来进行限定。需要注意的是__slots__的限定只对当前类的对象生效,对子类并不起任何作用。
代码示例
3.3、方法
3.3.1、魔法方法
- 魔术方法是 Python 中以双下划线开始和结束的特殊方法
- 它们是 Python 面向对象编程中的一种约定
- 这些方法会在特定情况下被 Python 解释器自动调用
- 只要对象实现了正确的魔术方法,它就能够像预期那样工作,而不用关心对象的具体类型。
3.3.2、对象方法
类的实例方法由实例调用,至少包含一个self参数,且为第一个参数。执行实例方法时,会自动将调用该方法的实例赋值给self。
self
代表的是类的实例,而非类本身。self不是关键字,而是Python约定成俗的命名3.3.3、静态方法
实际上,我们写在类中的方法并不需要都是对象方法,例如我们定义一个“三角形”类,通过传入三条边长来构造三角形,并提供计算周长和面积的方法,但是传入的三条边长未必能构造出三角形对象,因此我们可以先写一个方法来验证三条边长是否可以构成三角形,这个方法很显然就不是对象方法,因为在调用这个方法时三角形对象尚未创建出来(因为都不知道三条边能不能构成三角形),所以这个方法是属于三角形类而并不属于三角形对象的。
静态方法由类调用,无默认参数。将实例方法参数中的self去掉,然后在方法定义上方加上@staticmethod,就成为静态方法。它属于类,和实例无关。建议只使用类名.静态方法的调用方式。
示例代码
3.3.4、类方法
类方法由类调用,采用@classmethod装饰,至少传入一个cls(代指类本身,类似self)参数,通过这个参数我们可以获取和类相关的信息并且可以创建出类的对象。执行类方法时,自动将调用该方法的类赋值给cls(相当于是类调用了自己)。建议只使用类名.类方法的调用方式。
python装饰器:理解 Python 装饰器看这一篇就够了
示例代码
3.4、三者的区别
对象方法:可以调用对象属性,必要参数self,只能通过实例化调用。
类方法: 可以调用对象属性,必要参数cls,需要装饰器
@classmethod,两种调用方式:类.方法名 ,实例化调用(不推荐)。静态方法:不可以调用对象属性,无必要参数,需要装饰器
@staticmethod,两种调用方式:类.方法名 ,实例化调用(不推荐)。静态方法可以理解为定义在类中的普通函数

3.5、类的封装、继承和多态
面向对象有三大支柱:封装、继承和多态。
简单的说,类和类之间的关系有三种:is-a、has-a和use-a关系。
- is-a关系也叫继承或泛化,比如学生和人的关系、手机和电子产品的关系都属于继承关系。
- has-a关系通常称之为关联,比如部门和员工的关系,汽车和引擎的关系都属于关联关系;关联关系如果是整体和部分的关联,那么我们称之为聚合关系;如果整体进一步负责了部分的生命周期(整体和部分是不可分割的,同时同在也同时消亡),那么这种就是最强的关联关系,我们称之为合成关系。
- use-a关系通常称之为依赖,比如司机有一个驾驶的行为(方法),其中(的参数)使用到了汽车,那么司机和汽车的关系就是依赖关系。
封装
"隐藏一切可以隐藏的实现细节,只向外界暴露(提供)简单的编程接口"
我们在类中定义的方法其实就是把数据和对数据的操作封装起来了,在我们创建了对象之后,只需要给对象发送一个消息(调用方法)就可以执行方法中的代码,也就是说我们只需要知道方法的名字和传入的参数(方法的外部视图),而不需要知道方法内部的实现细节(方法的内部视图)。
继承
可以在已有类的基础上创建新类,这其中的一种做法就是让一个类从另一个类那里将属性和方法直接继承下来,从而减少重复代码的编写。提供继承信息的我们称之为父类,也叫超类或基类;得到继承信息的我们称之为子类,也叫派生类或衍生类。子类除了继承父类提供的属性和方法,还可以定义自己特有的属性和方法,所以子类比父类拥有的更多的能力,在实际开发中,我们经常会用子类对象去替换掉一个父类对象,这是面向对象编程中一个常见的行为,对应的原则称之为里氏替换原则
演示代码
继承中的 super() —— 使用super()的几种场景
1、在类的继承关系中,子类会继承父类所有的属性和方法。而如果子类需要给继承自父类的属性传递个性化参数时,可以使用 super() 方法
2、调用父类方法并构造子类自身的方法时
通过super().method()调用父类的方法时,如果实例缺乏必要的属性值,则会导致调用失败。
为了解决这个问题,确保以下规则实现:
- 对于每一个需要调用父类方法的子类,均需要在其
__.init__()方法中调用父类的__.init__()方法,即添加super().__.init__()代码;
- 在
super().__.init__()代码中传入关键字参数的字典。
3、存在多继承关系时
多继承中通常会有“继承顺序”(MRO:Method Resolution Order)的问题,我们可以通过
type.__mro__来查看任意一个类的MRO参考文章:【python】类继承中super的用法
多态
子类在继承了父类的方法后,可以对父类已有的方法给出新的实现版本,这个动作称之为方法重写(override)。通过方法重写我们可以让父类的同一个行为在子类中拥有不同的实现版本,当我们调用这个经过子类重写的方法时,不同的子类对象会表现出不同的行为,这个就是多态(poly-morphism)
四、文件/异常
4.1、文件读写的两个问题
打开什么样的文件(字符文件还是二进制文件)以及做什么样的操作(读、写还是追加)
- 文件类型:t(文本类型)、b(二进制类型)
- 操作模式:r(读)、w(写)、a(追加)、+(更新(可读可写))
- 以上两种可以相互组合:(r、w、a默认是操作文本文件t的,所以下面t被省略了)
- r, r+, rb, rb+
- w, w+, wb, wb+
- a, a+, ab, ab+
- 多种模式的区别对比
模式 | r | r+ | w | w+ | a | a+ |
写文件 | ㅤ | ✓ | ✓ | ✓ | ✓ | ✓ |
读文件 | ✓ | ✓ | ㅤ | ✓(有坑,详见下文) | ㅤ | ✓(有坑,详见下文) |
创建文件 | ㅤ | ㅤ | ✓ | ✓ | ✓ | ✓ |
覆盖文件 | ㅤ | ㅤ | ✓ | ✓ | ㅤ | ㅤ |
r+ | 读写模式 | 1、 可读可写;2、文件必须存在,否则报错;3、文件指针初始在开头;4、写入时会从当前指针位置覆盖原有内容 | 新写入的内容会覆盖原文件中的内容,写入几个字符,则覆盖几个字符 |
w+ | 读写模式 | 1、可读可写;2、如果文件不存在则创建;3、如果文件存在则清空内容;4、文件指针初始在开头 | 读取时读不到内容,因为w先把文件内容清空了 |
a+ | 追加读写模式 | 1、可读可写;2、如果文件不存在则创建;3、读取时指针可以移动(默认在末尾) 4、写入时指针强制移动到末尾 | 读取时读不到内容,因为文件指针默认在最后一行,可用seek移动文件指针位置;写文件只能从最后开始写,不能移动指针 |
4.2、文件读写的两种方式
需要写入,直接将参数
'r' 改为'w',追加改为'a'4.2.1、直接读写
4.2.2、上下文管理器(with关键字)
4.3、文件打开后的操作方法
4.3.1、方法汇总
方法名称 | 功能描述 | 示例 |
read() | 读取文件的全部内容或指定字节数。 | content = file.read() 或 content = file.read(100) |
readline() | 读取文件的一行内容。 | line = file.readline() |
readlines() | 读取文件的所有行,返回一个列表,每行作为一个元素 | lines = file.readlines() |
write() | 将字符串写入文件。 | file.write("Hello, World!") |
writelines() | 将字符串列表写入文件,每个字符串作为一行。 | file.writelines(["Line 1\n", "Line 2\n"]) |
seek() | 移动文件指针到指定位置。 | file.seek(0) # 将文件指针移动到文件开头 |
tell() | 返回当前文件指针的位置。 | position = file.tell() |
close() | 关闭文件,释放资源。 | file.close() |
flush() | 刷新缓冲区,将缓冲区数据立即写入文件。 | file.flush() |
truncate() | 截断文件到指定大小,默认为当前文件指针位置。 | file.truncate(100) # 将文件截断到 100 字节 |
fileno() | 返回文件的文件描述符。 | fd = file.fileno() |
isatty() | 检查文件是否连接到一个终端设备。 | is_terminal = file.isatty() |
seekable() | 检查文件是否支持随机访问,即是否支持 seek() 操作 | can_seek = file.seekable() |
readable() | 检查文件是否可读。 | can_read = file.readable() |
writable() | 检查文件是否可写。 | can_write = file.writable() |
4.3.2、方法实践
4.3、异常和断言
4.3.1、异常处理:try...except...
在Python中,我们可以将那些在运行时可能会出现状况的代码放在
try代码块中,在try代码块的后面可以跟上一个或多个except来捕获可能出现的异常状况。例如在上面读取文件的过程中,文件找不到会引发FileNotFoundError,指定了未知的编码会引发LookupError,而如果读取文件时无法按指定方式解码会引发UnicodeDecodeError,我们在try后面跟上了三个except分别处理这三种不同的异常状况。最后我们使用finally代码块来关闭打开的文件,释放掉程序中获取的外部资源,由于finally块的代码不论程序正常还是异常都会执行到(甚至是调用了sys模块的exit函数退出Python环境,finally块都会被执行,因为exit函数实质上是引发了SystemExit异常),因此我们通常把finally块称为“总是执行代码块”,它最适合用来做释放外部资源的操作。示例代码
4.3.2、断言:assert
在 Python 中,断言(
assert)是一种调试工具,用于检查程序在执行过程中是否满足某些条件。断言的作用是检测代码中的逻辑错误或假设不成立的情况。在调试阶段,使用 assert 可以帮助捕获错误并输出提示信息,确保程序按照预期的条件执行。断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况。基本语法
condition:这是需要检查的布尔表达式。如果condition为True,程序继续执行;如果为False,程序会抛出一个AssertionError异常。
"error_message":这是可选的错误消息字符串。当condition为False时,这条消息会被显示出来,帮助定位问题。
- 简单断言
上面代码中的断言检查
x 是否大于 0。如果条件为 True,程序继续执行;否则抛出 AssertionError 并输出 x 应该是正数。- 使用断言检查函数输入
在此例中,断言用于确保
sqrt 函数的输入参数非负,否则会抛出异常,避免计算无效的平方根。- 多条件断言
使用场景
- 验证数据:断言可以用来验证输入数据的有效性,确保数据符合预期范围或格式。
- 函数前置条件:在函数开始时使用断言,检查输入参数是否满足函数执行的前提条件。
- 调试程序逻辑:断言可以帮助捕获逻辑错误或不可能发生的情况,比如检查程序是否到达某个意料之外的分支。
- 性能优化:在发布阶段可以关闭断言,以提高性能(见下文)。
关闭断言
Python 提供了一种机制,在发布(或生产)环境中可以禁用断言,提高程序性能。只需在运行程序时添加
-O 选项即可:这会将 Python 解释器设置为“优化模式”,此时所有断言都会被忽略,
assert 语句相当于被移除了。捕获断言异常
可以通过
try-except 语句来捕获 AssertionError,从而自定义错误处理:断言的优缺点
- 优点:
- 有助于捕捉逻辑错误和意外情况。
- 提高代码的可读性,显示程序期望的条件。
- 可以在调试时帮助发现错误,快速定位问题。
- 缺点:
- 过多的断言会影响性能,尤其在对时间要求高的代码中。
- 一旦发布时禁用了断言,程序在生产环境中可能无法检测到断言条件的失效情况。
断言与异常的区别
- 断言主要用于调试阶段的假设验证,而异常则用于处理已知的错误和边界情况。
- 断言一般在逻辑上认为“不应该”出错的地方使用,而异常则用于在生产环境中控制流、捕获错误。
4.4、读写文本文件
读取文本文件时,需要在使用
open函数时指定好带路径的文件名(可以使用相对路径或绝对路径)并将文件模式设置为'r'(如果不指定,默认值也是'r'),然后通过encoding参数指定编码(如果不指定,默认值是None,那么在读取文件时使用的是操作系统默认的编码),如果不能保证保存文件时使用的编码方式与encoding参数指定的编码方式是一致的,那么就可能因无法解码字符而导致读取失败。示例代码
4.5、读写二进制文件
4.6、读写JSON文件
使用Python中的json模块就可以将字典或列表以JSON格式保存到文件中
json模块主要有四个比较重要的函数,分别是:
dump- 将Python对象按照JSON格式序列化到文件中
dumps- 将Python对象处理成JSON格式的字符串
load- 将文件中的JSON数据反序列化成对象
loads- 将字符串的内容反序列化成Python对象
五、使用经验
5.1、函数传参
单星号(*):*agrs;将所有参数以元组(tuple)的形式导入:
单星号的另一个用法是解压参数列表:
双星号(**):**kwargs;双星号(**)将参数以字典的形式导入
单星号和双星号一起使用:
5.2、从列表 A 中取出不在列表 B 中的元素(A 有上千万元素)
如果直接遍历 A,那么需要遍历上千万次,此时需要用取巧的办法
如果列表 B 非常小,那么可以直接用列表 A 的 remove 方法,效率最高;
如果列表 B 也很大,那么可以将两个列表转换成集合,然后使用集合的 difference方法或者用集合 A 减去集合 B,这两种方法的效率差不多;但需要注意
difference()方法返回一个新的集合,减法操作会直接改变集合 A使用集合比较的原理是基于哈希表实现的。具体来说,当我们将一个元素加入到集合中时,Python 会为该元素生成一个哈希值,并将该元素存储到哈希表中对应的槽位上。当我们需要判断一个元素是否在集合中时,Python 会先计算该元素的哈希值,然后通过哈希值快速定位到对应的槽位,判断该槽位中是否存在该元素。因此,使用集合比较可以在平均时间复杂度为 O(1) 的情况下完成查找操作,效率非常高。
需要注意的是,虽然使用集合可以提高查找效率,但是集合的创建和转换也需要消耗一定的时间和内存。因此,如果列表 B 非常小,可以直接使用列表的 remove() 方法来移除列表 A 中的元素,效率可能更高。但是,如果列表 B 较大,使用集合比较会更加高效。
5.3、常量与变量
常量与变量
- 在Python中,变量名大写通常用于表示常量,即那些程序运行过程中不会改变值的变量,这是一种约定俗成的编码风格,而不是Python语言的强制规则。按照这个约定,常量的命名应该使用全大写字母,如果有多个单词,可以使用下划线
_连接
- 变量是用来存储数据值的标识符。在Python中,变量可以在程序运行时创建,并且可以修改。Python是动态类型语言,这意味着在声明变量时不需要指定数据类型,数据类型会在赋值时自动确定。
- 定义在在函数外的变量是全局变量
命名规则:
- 变量名必须以字母(
a到z或A到Z)或下划线(_)开头。
- 变量名不能以数字开头。
- 变量名只能包含字母、数字和下划线(
A-Z、a-z、0-9、_)。
- 变量名是区分大小写的。例如,
myVariable和myvariable是两个不同的变量。
- 变量名不能是Python的关键字或内置函数名,如
if、while、class等。
变量的作用域
- 全局变量在函数内部可以正常使用
- 如果在函数内部定义一个变量,内部变量的名称和全局变量的名称一样,那么这个变量在函数内部和外部的值是不一样的
- 如果想在函数内部永久修改全局变量的值,那么需要先声明它是一个全局变量
思考下面的代码为什么会报错?
当执行到
print("函数内部1:", global_variable)这一行时,由于在函数下方有对global_variable的赋值操作,所以它被认为是一个局部变量,而变量在被定义之前使用就会报错5.4、if __name__ == '__main__':
- 每个Python模块都有一个特殊的内置属性
__name__。当一个模块被直接运行时,它的__name__属性值会被设置为'__main__'。
- 如果一个模块被导入到另一个模块中,则该模块的
__name__属性将是其模块名(即不包含.py扩展名的文件名)。
- 通常用来包含一些仅在模块作为脚本运行时需要执行的测试代码,而这些代码不会在模块被导入时执行。
- 如果这个Python文件被直接运行,那么
main()函数将会被执行,输出"Hello, World!"。然而,如果这个文件被其他Python脚本通过import语句导入,则main()函数不会自动运行
5.5、Python自带的debugger工具:pdb
进入 pdb 的方法
- (推荐)不用修改任何代码,在命令行运行
python -m pdb:用-m pdb来启动调试器,程序在执行到异常时自动进入pdb模式;默认停止在脚本第一行,需自行设置断点;如果以此种方式运行的程序中有 breakpoint() ,则该行不算断点。
- 在脚本代码中使用
breakpoint()(Python 3.7+):直接使用内置的breakpoint()函数,默认会进入pdb调试模式。
- 使用
import pdb:在代码中导入pdb模块,然后通过pdb.set_trace()来设置断点,使程序在此停下,进入调试模式。
pdb 调试器的常用语法
语法 | 全拼 | 作用 | 示例 |
p | print | 打印 | (Pdb) p variable_name |
w | where | 打印当前的调用堆栈,可以查看函数调用的历史记录。 | ㅤ |
bt | backtrace | 是 w 命令的别名,功能与其一致 | ㅤ |
l | list | 打印当前行前后 5 行,共 11 行脚本代码 | ㅤ |
l . | list . | 回到正在运行的当前行 | ㅤ |
ll | long list | 显示当前函数的全部代码 | ㅤ |
u | up | 切换到上一层作用域 | ㅤ |
d | down | 切换到下一层作用域 | ㅤ |
n | next | 执行当前行,并停在下一行(不进入函数内部) | ㅤ |
s | step | 执行当前行,进入当前行调用的函数内部(逐步进入函数)。 | ㅤ |
until | ㅤ | 如果没有参数,则继续执行,直到到达数字大于当前数字的行;通常用于跳出循环
如果有行号参数,继续执行,直到到达大于或等于行号的行。
在这两种情况下,当当前帧遇到函数返回时也停止。 | (Pdb) until # 当前在第6行,运行到行数为7时停止
(Pdb) until 10 # 直接运行到第10行 |
c | continue | 继续执行程序,直到下一个断点或程序结束。 | ㅤ |
r | return | 在函数内部调试时,该命令将停在返回 value 之前(此时可以用 retval 获取函数返回值) | ㅤ |
retval | ㅤ | 函数调用执行到最后一行要返回时,获取当前函数的返回值。 | ㅤ |
b | breakpoint
break | 设置断点,可以指定行号或函数名设置断点。
如果不加参数就列出所有的断点 | (Pdb) b 15 # 在第 15 行设置断点
(Pdb) b my_function # 设置断点在 my_function 函数的入口 |
clear | ㅤ | 如果后面跟断点所在行数,则清除指定断点;(只能跟行数,不能跟函数名)
如果没有指定断点,直接执行 clear 命令,则清除所有断点 | (Pdb) clear 15 # 清除第 15 行的断点
(Pdb) clear # 清除所有断点 |
q | quit | 退出调试器,结束程序。 | ㅤ |
h | help | 获取调试器命令的帮助信息。后面可以加具体的命令作为参数,从而展示命令的详细信息 | ㅤ |
5.6、Python的命令行参数详解
参数 | 功能 | 说明 | 使用示例 |
-m <module> | 以脚本形式运行模块 | 将指定的模块作为脚本运行,常用于运行标准库模块或自定义模块。
模块的设计目的是被 导入(import),而不是直接运行。脚本的设计目的是被 运行,而不是被导入。 | python -m http.server 8000 |
-c <command> | 执行命令行中的 Python 代码 | 直接在命令行中执行 Python 代码,适用于简单操作。 | python -c "print('Hello, World!')" |
-h 或 --help | 显示帮助信息 | 显示 Python 命令行参数的帮助信息。 | python --help |
-V 或 --version | 显示 Python 版本信息 | 显示当前 Python 解释器的版本信息。 | python --version |
-i | 交互模式运行脚本 | 运行脚本后进入交互模式,保留脚本中的变量和状态。 | python -i script.py |
-u | 强制标准输入、输出和错误流无缓冲 | 适用于需要实时输出的场景,如日志记录。 | python -u script.py |
-O | 优化模式 | 移除断言语句和调试信息,生成优化后的字节码。 | python -O script.py |
-B | 不生成 .pyc 或 .pyo 文件 | 避免生成字节码文件,适用于需要干净环境的场景。 | python -B script.py |
-W <warning control> | 控制警告信息的显示 | 设置警告信息的显示级别,如忽略、显示为错误等。 | python -W ignore script.py |
-v | 显示模块加载的详细信息 | 打印每个模块加载的详细信息,便于调试模块导入问题。 | python -v script.py |
-I | 隔离模式 | 运行 Python 时隔离环境,忽略用户环境变量和模块路径。 | python -I script.py |
-E | 忽略 PYTHONPATH 环境变量 | 运行时不使用 PYTHONPATH 环境变量中的路径。 | python -E script.py |
-s | 不将用户目录添加到 sys.path | 运行时不将用户目录添加到模块搜索路径中。 | python -s script.py |
-S | 简化启动模式 | 不自动导入 site 模块,减少启动时的初始化操作。 | python -S script.py |
-q | 静默模式 | 减少输出信息,适用于不需要详细输出的场景。 | python -q script.py |
-OO | 更高级的优化模式 | 在 -O 的基础上,进一步移除文档字符串。 | python -OO script.py |
-X <option> | 启用实验性功能 | 启用 Python 解释器的实验性功能,如 -X faulthandler。 | python -X faulthandler script.py |
-b | 发出 bytes 和 str 比较的警告 | 当比较 bytes 和 str 时发出警告。 | python -b script.py |
-bb | 将 bytes 和 str 比较视为错误 | 当比较 bytes 和 str 时抛出异常。 | python -bb script.py |
-d | 启用调试输出 | 启用解析器的调试输出,显示更多调试信息。 | python -d script.py |
-R | 启用哈希随机化 | 启用哈希随机化,防止哈希碰撞攻击。 | python -R script.py |
5.7、Python代码测试
5.8、为什么 Python 项目中会有__pycache__文件夹和__init__.py 文件?
pycache 文件夹
pycache 文件夹是 Python 3.x 引入的字节码缓存机制:
- 作用 :
- 存储编译后的字节码文件(.pyc 文件)
- 加快程序启动和运行速度
- 避免重复编译相同的源代码
- 工作原理 :
- 当 Python 首次导入模块时,会将源代码编译成字节码
- 编译后的字节码存储在 pycache 目录下
- 文件名格式: module.version.pyc (例如: mymodule.cpython-39.pyc )
- 下次运行时,如果源代码未修改,直接使用缓存的字节码
- 控制方式 :
init.py 文件
init.py 文件用于标记一个目录是 Python 包:
- 主要功能 :
- 将目录标记为 Python 包
- 初始化包级别的变量和导入
- 控制模块的导入行为
- 定义包的公共接口
- 使用示例 :
- 常见用法示例 :
最佳实践
- 关于 pycache :
- 将其添加到 .gitignore 文件中
- 不要手动修改其中的文件
- 在开发环境可以使用它提升性能
- 在特殊情况下可以使用 -B 参数禁用
- 关于 init.py :
- 保持简单,避免复杂的初始化逻辑
- 明确定义包的公共接口
- 适当使用相对导入
- 考虑向后兼容性
注意事项
- pycache :
- Python 3.2+ 自动创建
- 不同 Python 版本的字节码不兼容
- 删除不会影响程序功能,但可能影响性能
- init.py :
- Python 3.3+ 引入了隐式命名空间包,可以不需要 init.py
- 但为了兼容性和明确性,建议保留
- 避免在其中放置太多代码
- 主要用于包的初始化和接口定义
其他
六、闭包与装饰器
闭包(Closure)
1. 什么是闭包?
闭包是指在一个函数内部定义的另一个函数,并且这个内部函数可以引用外部函数中的变量。即使外部函数已经返回,内部函数仍然可以访问这些变量。这种行为是因为内部函数“闭合”了外部函数的作用域,从而形成了一个闭包。
2. 闭包的条件
要形成闭包,需要满足以下三个条件:
- 有一个外部函数:这个外部函数包含一个内部函数。
- 外部函数返回内部函数:外部函数必须返回内部函数的引用。
- 内部函数引用了外部函数的变量:内部函数使用了外部函数中的变量,并且外部函数已经结束执行。
3. 闭包的示例
- 解释:
outer_function是外部函数,inner_function是内部函数。inner_function引用了outer_function的局部变量text。- 即使
outer_function执行完毕,inner_function依然可以访问并使用text,这就是闭包。
4.使用 nonlocal 修改外部函数的局部变量
5.闭包的优缺点
优点:
- 闭包可以捕获并“记住”外部函数的局部变量,即使外部函数已经执行完毕,这使得闭包能够在多次调用时保持状态。这对于需要在多次调用之间共享和维护状态的情况非常有用,如实现计数器、缓存机制等。
- 闭包可以隐藏外部函数的局部变量,外部代码无法直接访问这些变量。这种封装性提高了代码的安全性和模块化,使得外部代码只能通过内部函数的接口来访问这些数据。
- 闭包是函数式编程的重要特性之一。它使得函数可以像数据一样传递,并且可以创建更高阶的函数,如装饰器等,这提高了代码的灵活性和可复用性。
- 闭包可以在需要的时候再计算某些值,而不是立即计算,这对于懒加载或需要节省计算资源的场景非常有用。
缺点:
- 容易导致内存泄漏:由于闭包会捕获外部函数的局部变量,这可能导致这些变量的生命周期比预期的要长,尤其是在闭包被长时间引用的情况下。这可能会导致内存泄漏,特别是在捕获了大对象或复杂数据结构时。
- 调试困难:闭包的调试通常比普通函数更复杂,因为变量的作用域变得更加隐蔽,追踪和理解程序的执行流程可能需要更多的时间和精力。
装饰器(Decorator)
1. 什么是装饰器?
装饰器是一种特殊的闭包,用于在不修改函数源代码的情况下,动态地增加或修改函数的行为。装饰器本质上是一个函数,它接受一个函数作为输入,并返回一个新的函数作为输出。
2. 装饰器的使用场景
- 日志记录:在函数执行前后记录日志。
- 性能监控:计算函数执行时间。
- 权限验证:在执行函数前检查用户权限。
- 缓存:缓存函数的返回结果以提高性能。
3. 装饰器的基本结构
示例1:
示例2:
4. 装饰器的使用示例
示例1:
my_decorator是一个装饰器函数,它接收say_hello函数作为参数,并返回wrapper函数。
wrapper函数在调用say_hello之前和之后添加了额外的操作。
- 使用
@my_decorator语法糖,将my_decorator应用于say_hello函数。
示例2:
5. 装饰器与带参数的函数
装饰器不仅可以用于不带参数的函数,还可以用于带参数的函数,甚至是类方法。
wrapper函数使用args和*kwargs捕获display_info函数的所有参数。
- 装饰器不仅对无参函数有效,对任何带参数的函数都可以灵活使用。
闭包与装饰器的关系
装饰器可以看作是闭包的一种特定应用。它们都利用了函数嵌套和作用域规则,允许我们在不修改原函数的前提下,增强或修改函数的行为。闭包为装饰器提供了技术基础,使得装饰器能够在函数调用前后添加逻辑,从而实现代码的复用和扩展。
七、Python更新
Python 3.5
- 异步编程 (
async和await) - Python 3.5 引入了
async和await关键字,使得异步编程更加简洁和直观。它们允许编写异步 I/O 操作,更加高效地处理并发任务。 - 示例:
- 类型提示 (Type Hints)
- 类型提示允许在函数签名中指定参数和返回值的类型,为代码提供更好的自文档性和工具支持。
- 示例:
- 类型提示(Type Hints)在 Python 中的主要作用是提高代码的可读性、可维护性和可靠性。虽然类型提示本身不会在运行时强制执行类型检查,但它们在以下几个方面非常有用:
- 类型提示可以让代码的读者更容易理解变量、函数参数和返回值的预期类型。这有助于开发者快速理解代码的意图,尤其是在大型项目或团队合作中。
- 虽然 Python 是动态类型语言,但通过使用类型提示,你可以借助静态类型检查工具(如
mypy)在编写代码时捕获潜在的类型错误。这有助于在代码运行之前发现问题,减少调试时间。 - 通过使用类型提示和静态类型检查工具,你可以减少运行时类型错误的发生,从而提高代码的可靠性。这有助于构建更健壮的应用程序。
类型提示本身并不会在运行时强制执行类型检查。也就是说,即使你在定义变量时指定了类型,如果你传递了其他类型的值,Python 解释器也不会报错。
在函数中,也可以使用类型提示来指定参数和返回值的类型。如果你传递了不匹配的类型,Python 解释器同样不会报错
可以使用静态类型检查工具,如
mypy。mypy 是一个流行的工具,它可以分析你的代码并报告类型不匹配的错误。类型提示自定义
Python 3.6
- 格式化字符串字面值 (f-strings)
- f-strings 是一种新的字符串格式化方法,允许在字符串中直接嵌入表达式,语法简洁且易读。
- 示例:
secrets模块- 引入了
secrets模块,用于生成强随机数和安全的密钥,特别适合于生成令牌、密码和其他敏感信息。 - 示例:
Python 3.7
- 数据类 (Data Classes)
dataclasses模块提供了@dataclass装饰器,用于简化类的定义,特别适合用于表示数据结构。- 示例:
asyncio.run()函数asyncio.run()函数简化了异步程序的启动方式,使异步代码更加易于使用和理解。- 示例:
Python 3.8
- 海象运算符 (Walrus Operator,
:=) - 赋值表达式允许在表达式中进行赋值,从而减少代码重复,提高代码可读性。
- 示例:
positional-only参数- 可以使用
/指定函数参数为仅限位置参数,这对于设计 API 更加明确。 - 示例:
a, b, /:在/之前的参数a和b是 positional-only 参数。调用函数时,必须通过位置传递它们,不能使用关键字参数。c, d:在/之后的参数c和d是普通参数,可以通过位置或关键字传递。
Python 3.9
- 字典合并运算符 (
|和|=) |运算符用于合并两个字典,|=用于更新字典。- 示例:
- 类型提示增强
- 支持使用
list[int]、dict[str, int]等泛型类型提示,简化类型注解。 - 示例:
Python 3.10
- 结构化模式匹配 (Pattern Matching)
- 类似于
switch-case的模式匹配功能,允许对复杂的数据结构进行解构和匹配。 - 示例:
- 类型提示的联合操作符 (
|) |运算符用于表示多个类型的联合,替代Union。- 示例:
Python 3.11
- 性能改进
- Python 3.11 对解释器进行了大幅度的性能优化,官方声称整体性能提升了 10-60%。
- 异常消息的精确度提升
- Python 3.11 提供了更精确和详细的异常消息,尤其在链式异常和复杂表达式中的错误定位上。
Python 3.12
- Python内存模型的增强
- 改进了内存分配的方式,进一步提升了 Python 程序的运行速度和内存管理的效率。
- 模式匹配中的更多匹配结构
- 进一步扩展了结构化模式匹配的能力,使其支持更多的匹配结构和自定义模式。