type
Post
status
Published
summary
Spark 借鉴了 MapReduce 思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提 高了运行速度、并提供丰富的操作数据的API提高了开发速度。Spark可以计算:结构化、半结构化、非结构化等各种类型的数据结构,同时也支持使用Python、Java、Scala、R以及SQL语言去开发应用 程序计算数据。Spark 集成了多种大数据工具和框架,如 Kafka、Cassandra、HBase、HDFS 等,形成了一个强大的大数据处理生态系统。Spark 的统一编程模型和强大的性能使其成为大数据分析、实时流处理和机器学习等领域的重要工具。
slug
bigdata-spark-base
date
Jul 28, 2024
tags
大数据
Spark
Spark部署
category
大数据
password
icon
URL
Property
Jul 31, 2024 01:36 AM
概述
Apache Spark 是由加州大学伯克利分校 AMP 实验室于 2009 年发起的开源大数据处理引擎,旨在提高大数据处理的速度和效率。Spark 的设计理念是通过在内存中进行数据处理来提升性能,并提供统一的编程模型来简化大数据处理任务。
在 Spark 之前,大数据处理主要依赖于 Hadoop MapReduce。虽然 Hadoop MapReduce 为分布式计算提供了良好的框架,但其性能和编程模型存在一些局限性:
- 磁盘 I/O:MapReduce 在每个阶段之间需要将中间结果写入磁盘,这导致大量的磁盘 I/O 操作,影响了性能。
- 编程复杂性:MapReduce 的编程模型比较低级,对于复杂的数据处理任务(如迭代算法、交互式查询)来说,编写和维护代码变得困难。
为了克服 Hadoop MapReduce 的这些局限性,AMP 实验室的研究人员开发了 Spark。Spark 的主要目标是提供更快的计算速度和更简单的编程模型。其核心思想包括:
- 内存计算:通过在内存中进行数据处理,减少磁盘 I/O 操作,从而显著提高计算速度。
- 弹性分布式数据集(RDD):引入了 RDD 概念,提供了一种容错的、分布式的内存抽象,简化了分布式数据处理的编程模型。
自 2013 年 Spark 作为 Apache 项目孵化以来,它得到了迅速的发展和广泛的应用。2014 年,Spark 成为 Apache 顶级项目。随着版本的迭代,Spark 的功能和性能不断提升,逐渐成为大数据处理领域的重要工具。
Spark 借鉴了 MapReduce 思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提 高了运行速度、并提供丰富的操作数据的API提高了开发速度。Spark可以计算:结构化、半结构化、非结构化等各种类型的数据结构,同时也支持使用Python、Java、Scala、R以及SQL语言去开发应用 程序计算数据。Spark 集成了多种大数据工具和框架,如 Kafka、Cassandra、HBase、HDFS 等,形成了一个强大的大数据处理生态系统。Spark 的统一编程模型和强大的性能使其成为大数据分析、实时流处理和机器学习等领域的重要工具。
Spark 和 Hadoop 的对比
ㅤ | Hadoop | Spark |
类型 | 基础平台, 包含计算, 存储, 调度 | 纯计算工具(分布式) |
场景 | 海量数据批处理(磁盘迭代计算) | 海量数据的批处理(内存迭代计算、交互式计算)、海量数 据流计算 |
价格 | 对机器要求低, 便宜 | 对内存有要求, 相对较贵 |
编程范式 | Map+Reduce, API 较为底层, 算法适应性差 | RDD组成DAG有向无环图, API 较为顶层, 方便使用 |
数据存储结构 | MapReduce中间计算结果在HDFS磁盘上, 延迟大 | RDD中间运算结果在内存中 , 延迟小 |
运行方式 | Task以进程方式维护, 任务启动慢 | Task以线程方式维护, 任务启动快,可批量创建提高并行能 力 |
尽管Spark相对于Hadoop而言具有较大优势,但Spark并不能完全替代Hadoop 在计算层面,Spark相比较MR(MapReduce)有巨大的性能优势,但至今仍有许多计算工具基于MR构架,比如非常成熟的Hive Spark仅做计算,而Hadoop生态圈不仅有计算(MR)也有存储(HDFS)和资源管理调度(YARN),HDFS和YARN仍是许多大数据 体系的核心架构。
工作原理
Spark架构
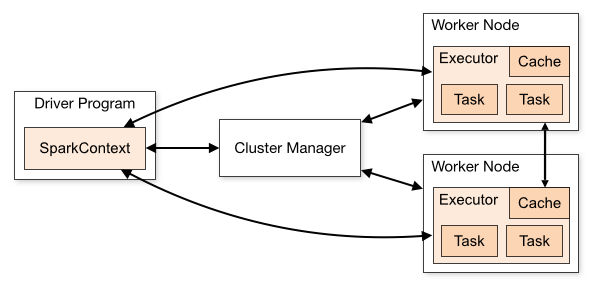
Term(术语) | Meaning(含义) |
Application | Spark 应用程序,由集群上的一个 Driver 节点和多个 Executor 节点组成。 |
Driver program | 主运用程序,该进程运行应用的 main() 方法并且创建 SparkContext |
Cluster manager | 集群资源管理器(例如,Standlone Manager,Mesos,YARN) |
Worker node | 执行计算任务的工作节点 |
Executor | 位于工作节点上的应用进程,负责执行计算任务并且将输出数据保存到内存或者磁盘中 |
Task | 被发送到 Executor 中的工作单元 |
1. Driver(驱动程序):Driver 是运行 Spark 应用程序的主程序,负责整个应用程序的生命周期管理。
- 创建 SparkContext:Driver 程序创建 SparkContext,作为与集群进行交互的主要接口。
- 定义 RDD 转换和行动操作:Driver 程序定义 RDD 的转换(transformation)和行动(action)操作。
- 任务调度:将作业分解为任务(tasks),并将这些任务分配给集群中的 Executors。
- 收集结果:从 Executors 收集计算结果并进行汇总。
2. Executor(执行器):Executor 是运行在集群中的工作节点,负责执行任务并进行数据存储。
- 执行任务:Executor 接收 Driver 分配的任务,并在其本地计算数据。
- 数据缓存:根据需要将中间结果缓存到内存中,以加速后续的计算。
- 任务结果反馈:将任务的执行结果返回给 Driver。
3. Cluster Manager(集群管理器):Cluster Manager 负责管理集群资源,调度和分配资源给 Spark 应用程序。常见的 Cluster Manager 包括 Spark 自带的 Standalone 模式、YARN 和 Mesos。
- 资源分配:根据 Spark 应用程序的资源需求,分配计算资源(CPU、内存等)。
- 启动 Executors:在合适的 Worker 节点上启动 Executors,并进行资源隔离和管理。
- 监控资源使用:监控集群中各个节点的资源使用情况,并进行动态调整。
4. Worker(工作节点):Worker 是集群中的计算节点,负责运行 Executor 并执行实际的计算任务。
- 运行 Executors:Worker 根据 Cluster Manager 的指令,启动和管理 Executors。
- 资源管理:管理节点上的资源(如 CPU、内存),确保合理分配和使用。
- 任务执行:执行分配到的任务,并将结果返回给 Driver。
角色之间的关系
- Driver 与 Cluster Manager:Driver 向 Cluster Manager 请求资源,以便在集群中启动 Executors。
- Cluster Manager 与 Worker:Cluster Manager 分配资源并在 Worker 节点上启动 Executors。
- Driver 与 Executor:Driver 将任务分配给 Executors 并收集它们的执行结果。
- Executor 与 Worker:Executor 运行在 Worker 节点上,执行实际的计算任务。
示例工作流程
- Driver 启动:Driver 程序启动,并创建 SparkContext。
- 请求资源:SparkContext 向 Cluster Manager 请求资源,以启动 Executors。
- 启动 Executors:Cluster Manager 在 Worker 节点上启动 Executors,并分配相应的资源。
- 任务调度:Driver 将任务分配给运行在 Worker 节点上的 Executors。
- 执行任务:Executors 执行任务并将结果返回给 Driver。
- 结果汇总:Driver 收集并处理任务结果,最终得到应用程序的输出。
Standalone 模式:Spark 启动后,服务器中启动的服务会有 Master、Worker、Historyserver;Master是在主节点上运行,Worker在工作节点上运行。当有任务请求时,任务会创建一个Driver 程序,Driver 程序向 Master 请求资源并启动执行Executors;当有第二个任务请求时,继续创建第二个Driver 程序,然后请求并执行第二批的Executors。以此类推
核心组件
整个Spark 框架模块包含:Spark Core、 Spark SQL、 Spark Streaming、 Spark GraphX、 Spark MLlib,而后四项的能力都是建立在核心引擎之上。

- Spark Core:Spark的核心,Spark核心功能均由Spark Core模块提供,是Spark运行的基础。Spark Core提供了 RDD 的抽象和基本的任务调度、内存管理等功能,提供Python、Java、 Scala、R语言的API,可以编程进行海量离线数据批处理计算。
- Spark SQL:基于SparkCore之上,提供结构化数据的处理模块。SparkSQL支持以SQL语言对数据进行处理,SparkSQL本身针对离线计算场景。同 时基于SparkSQL,Spark提供了StructuredStreaming模块,可以以SparkSQL为基础,进行数据的流式计算。 能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 DataFrame API 对结构化数据进行查询;支持多种数据源,包括 Hive,Avro,Parquet,ORC,JSON 和 JDBC;支持 HiveQL 语法以及用户自定义函数 (UDF),允许你访问现有的 Hive 仓库;支持标准的 JDBC 和 ODBC 连接;支持优化器,列式存储和代码生成等特性,以提高查询效率。
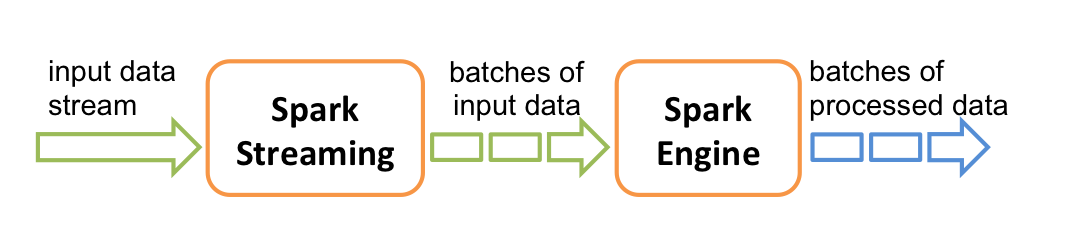
- Spark Streaming:Spark Streaming 以SparkCore为基础,主要用于快速构建可扩展,高吞吐量,高容错的流处理程序。支持从 HDFS,Flume,Kafka,Twitter 和 ZeroMQ 读取数据,并进行处理。Spark Streaming 的本质是微批处理,它将数据流进行极小粒度的拆分,拆分为多个批处理,从而达到接近于流处理的效果。

- MLlib:以SparkCore为基础,进行机器学习计算,内置了大量的机器学习库和API算法等。方便用户以分布式计算的模式进行机器学习计算。 常见的机器学习算法:如分类,回归,聚类和协同过滤;特征化:特征提取,转换,降维和选择;管道:用于构建,评估和调整 ML 管道的工具;持久性:保存和加载算法,模型,管道数据;实用工具:线性代数,统计,数据处理等。
- GraphX:以SparkCore为基础,进行图计算,提供了大量的图计算API,方便用于以分布式计算模式进行图计算。在高层次上,GraphX 通过引入一个新的图形抽象来扩展 RDD(一种具有附加到每个顶点和边缘的属性的定向多重图形)。为了支持图计算,GraphX 提供了一组基本运算符(如: subgraph,joinVertices 和 aggregateMessages)以及优化后的 Pregel API。此外,GraphX 还包括越来越多的图形算法和构建器,以简化图形分析任务。
运行模式
Apache Spark 提供了多种运行模式,以适应不同的使用场景和集群配置。主要的运行模式包括:
- Local 模式:在单台机器上运行 Spark,主要用于开发和测试。
- 适合小规模数据集的快速开发和调试。
- 方便在本地环境中快速进行开发,无需配置集群。
- Standalone 模式:Spark 自带的简单集群管理器,可以在单机上或多台机器上运行 Spark 集群。
- 易于配置和使用,适合小规模集群和开发环境。
- 不依赖于外部资源管理工具,简单直接。
- YARN 模式:Spark 可以作为 Hadoop YARN 的应用程序运行,利用 YARN 的资源管理能力。
- 支持大规模集群,适合与 Hadoop 生态系统集成。
- 利用 YARN 的资源调度功能,实现多种应用的共享和调度。
- Kubernetes 模式:Spark 可以在 Kubernetes 上运行,适合容器化环境。
- 利用 Kubernetes 的编排和管理功能,简化集群管理。
- 方便与其他容器化应用程序集成,适用于微服务架构。
- Mesos 模式:Apache Mesos 是一个通用的集群管理系统,Spark 可以在 Mesos 上运行。
- 提供强大的资源管理和调度能力,支持多种框架共存。
- 适用于需要动态资源分配的复杂场景。
各模式对比总结
模式 | 适用场景 | 特点 | ㅤ |
Local | 开发和测试 | 便捷快速的本地开发 | 一个进程内多个线程来模拟Spark 集群 |
Standalone | 小规模集群和开发环境 | 简单易用 | 一主多从,存在单点故障问题 |
YARN | 大规模集群 | 与 Hadoop 生态系统集成 | ㅤ |
Kubernetes | 容器化环境 | 适合微服务架构 | ㅤ |
Mesos | 动态资源分配 | 支持多种框架共存 | ㅤ |
Spark特点
- 使用先进的 DAG(有向无环图)调度程序,减少了任务之间的数据传输和等待时间,查询优化器和物理执行引擎,以实现性能上的保证;
- 多语言支持,目前支持的有 Java,Scala,Python 和 R;
- 提供了 80 多个高级 API,可以轻松地构建应用程序;
- 支持批处理,流处理和复杂的业务分析;
- 丰富的类库支持:包括 SQL,MLlib,GraphX 和 Spark Streaming 等库,并且可以将它们无缝地进行组合;
- 丰富的部署模式:支持本地模式和自带的集群模式,也支持在 Hadoop,Mesos,Kubernetes 上运行;
- 多数据源支持:支持访问 HDFS,Alluxio,Cassandra,HBase,Hive 以及数百个其他数据源中的数据。
Spark部署
conda下载安装
conda 二选一:(M芯片的 MacOS 上的 Ubuntu 虚拟机安装时选择 Linux-aarch64.sh 版本)
- Anaconda:清华源 (原始包更多,体积更大)
- miniconda:清华源(更轻量化)
安装 miniconda
- 将下载好的 sh 文件上传到 export 文件夹,并运行 sh 文件,
- 欢迎页面,按回车继续,显示很多协议项,协议显示完后会询问是否接收协议,输入 yes继续
- 选择安装位置,
[/root/miniconda3] >>> /export/server/miniconda3将其安装在/export/server/miniconda3中,回车
- 询问是否进行初始化:
You can undo this by running conda init --reverse $SHELL? [yes|no],yes
- 出现:
Thank you for installing Miniconda3!安装完成
- control + d 或者 exit 退出,然后重新切换回 root 用户即可发现命令行开头有虚拟环境的标识出现了:
(base) root@anjhon:~#
- 修改三方库的镜像源:
- 打开
.condarc文件,如果不存在就创建:vim ~/.condarc - 添加镜像源:
# Conda 配置文件 # 默认的下载通道,优先级最高。设置为defaults将使用default_channels中定义的通道。 channels: - defaults # 安装时是否显示包的下载 URL show_channel_urls: true # 默认通道配置,将默认的下载通道指向清华大学的镜像源。 default_channels: - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main # 主通道 - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free # 开源通道 - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r # R 语言通道 - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2 # msys2 通道 # 自定义通道配置,将一些常用的社区通道指向清华大学的镜像源。 custom_channels: conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge # conda-forge 通道 msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2 # msys2 通道 bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda # bioconda 通道 menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/menpo # menpo 通道 pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch # pytorch 通道 simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/simpleitk # simpleitk 通道
创建虚拟环境
- 创建:
conda create -n pyspark python=3.8,遇到问答输入 y
- 切换:
conda activate pyspark
Spark 下载安装
- 下载上传解压到 /export/server/ 下
- 创建软连接
配置环境变量
vim /etc/profile
export JAVA_HOME=/export/server/jdk export HADOOP_HOME=/export/server/hadoop export SPARK_HOME=/export/server/spark export PYSPARK_PYTHON=/export/server/miniconda3/envs/pyspark/bin/python3.8 export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profilevim ~/.bashrc
export PYSPARK_PYTHON=/export/server/miniconda3/envs/pyspark/bin/python3.8 export JAVA_HOME=/export/server/jdk
Local 模式
该模式只需要一台服务器,通过单进程内的多线程来模拟集群效果。如果时多任务就会开启多个进程。
本质:启动一个JVM Process进程(一个进程里面有多个线程),执行任务Task。
- Local模式可以限制模拟Spark集群环境的线程数量, 即Local[N] 或 Local[*]
- 其中N代表可以使用N个线程,每个线程拥有一个cpu core。如果不指定N, 则默认是1个线程(该线程有1个core)。 通常Cpu有几个Core,就指定几个 线程,最大化利用计算能力.
- 如果是local[*],则代表 Run Spark locally with as many worker threads as logical cores on your machine.按照Cpu最多的Cores设置线程数
Local模式只能运行一个Spark程序, 如果执行多个Spark程序, 那就是由多个相互独立的Local进程在执行
Local模式就是以一个独立进程配合其内部线程来提供完成Spark运行时环境. Local模式可以通过spark-shell/pyspark/spark-submit等来开启
如果在 local 模式启动两个进程,那么两个进程会绑定到两个不同的端口以供 webUI 访问。
启动 Spark local python
使用默认进入Spark local:
(pyspark) root@anjhon:/export/server/spark/bin# ./pyspark指定进程参数进入 local:
(pyspark) root@anjhon:/export/server/spark/bin# ./pyspark --master local[3]运行测试:
sc.parallelize([1,2,3,4]).map(lambda x: x*10).collect()
Driver 的 web 监控页面:http://anjhon:4040
提交代码到Spark local运行:
(pyspark) root@anjhon:/export/server/spark/bin# ./spark-submit --master local[*] /export/server/spark/examples/src/main/python/pi.py 10 计算 pi 的案例,迭代 10 次启动 Spark local scala
(pyspark) root@anjhon:/export/server/spark/bin# ./spark-shellStandalone 模式
主从模式
环境准备
- 在集群的其他节点上也安装 conda 环境
- 将 conda 的安装文件通过 scp 分发到其他节点,进行安装(不能直接复制安装好的文件夹)
scp Miniconda3-py38_23.9.0-0-Linux-aarch64.sh anjhon2:$PWD- 安装步骤详见上文
- 配置所有集群节点上环境变量(详见上文参照主节点的配置进行)
- 修改Spark 的配置文件
- 将export/server/spark 的所有权修改为 Hadoop:
(pyspark) root@anjhon:/export/server# chown -R hadoop:hadoop spark* - 切换到 Hadoop 用户:
su - hadoop - 修改配置
- workers:
hadoop@anjhon:/export/server/spark/conf$ mv workers.template workershadoop@anjhon:/export/server/spark/conf$ vim workersanjhon anjhon2 anjhon3
spark-env.shhadoop@anjhon:/export/server/spark/conf$ vim spark-env.sh## 设置JAVA安装目录 JAVA_HOME=/export/server/jdk ## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群 HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop YARN_CONF_DIR=/export/server/hadoop/etc/hadoop ## 指定spark老大Master的IP和提交任务的通信端口 # 告知Spark的master运行在哪个机器上 export SPARK_MASTER_HOST=anjhon # 告知sparkmaster的通讯端口 export SPARK_MASTER_PORT=7077 # 告知spark master的 webui端口 SPARK_MASTER_WEBUI_PORT=8080 # worker cpu可用核数 SPARK_WORKER_CORES=1 # worker可用内存 SPARK_WORKER_MEMORY=1g # worker的工作通讯地址 SPARK_WORKER_PORT=7078 # worker的 webui地址 SPARK_WORKER_WEBUI_PORT=8081 ## 设置历史服务器 # 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中 SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://anjhon:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
配置好后在 hdfs 中创建对应的文件夹:
hdfs dfs -mkdir /sparklog ;修改权限:hdfs dfs -chmod 777 /sparklogspark-defaults.confhadoop@anjhon:/export/server/spark/conf$ mv spark-defaults.conf.template spark-defaults.confhadoop@anjhon:/export/server/spark/conf$ vim spark-defaults.conf# 开启spark的日期记录功能 spark.eventLog.enabled true # 设置spark日志记录的路径 spark.eventLog.dir hdfs://anjhon:8020/sparklog/ # 设置spark日志是否启动压缩 spark.eventLog.compress true
log4j2.propertieshadoop@anjhon:/export/server/spark/conf$ mv log4j2.properties.template log4j2.propertieshadoop@anjhon:/export/server/spark/conf$ vim log4j2.properties将
rootLogger.level = info 改为 rootLogger.level = warn- 将 Spark 分发到其他集群节点
scp -r spark-3.4.3-bin-hadoop3 anjhon2:$PWD- 在 anjhon2 上切换到 Hadoop 用户,创建 Spark 的软连接
scp -r spark-3.4.3-bin-hadoop3 anjhon3:$PWD- 在 anjhon3 上切换到 Hadoop 用户,创建 Spark 的软连接
ln -s /export/server/spark-3.4.3-bin-hadoop3 /export/server/sparkln -s /export/server/spark-3.4.3-bin-hadoop3 /export/server/spark启动Spark集群
- 启动历史服务器:
hadoop@anjhon:/export/server/spark$ ./sbin/start-history-server.sh
- 启动集群:
hadoop@anjhon:/export/server/spark$ ./sbin/start-all.sh
hadoop@anjhon:/export/server/spark$ jps 42788 Master 42951 Worker 42344 HistoryServer
- Master 的 webui 监控页面:http://10.211.55.6:8080/
连接到集群工作
bin/pyspark
hadoop@anjhon:/export/server/spark$ bin/pyspark --master spark://anjhon:7077sc.parallelize([1,2,3]).map(lambda x:x*10).collect()
Driver 的 web 监控页面:http://anjhon:4040
bin/spark-submit
hadoop@anjhon:/export/server/spark$ bin/spark-submit --master spark://anjhon:7077 /export/server/spark/examples/src/main/python/pi.py 100访问历史服务器的 webui 查看页面:http://anjhon:18080/ 查看程序运行细节
Spark程序运行层次结构
Spark 端口使用情况:
- 4040: 是一个运行的Application在运行的过程中临时绑定的端口,用以查看当前任务的状态.4040被占用会顺延到4041.4042等;4040是一个临时端口,当前程序运行完成后, 4040就会被注销
- 8080: 默认是StandAlone下, Master角色(进程)的WEB端口,用以查看当前Master(集群)的状态
- 18080: 默认是历史服务器的端口, 由于每个程序运行完成后,4040端口就被注销了. 在以后想回看某个程序的运行状态就可以通过历史服务器查看,历史服务器长期稳定运行,可供随时查看被记录的程序的运行过程.
一个Spark程序会被分成多个子任务(Job)运行, 每一个Job会分成多个State(阶段)来 运行, 每一个State内会分出来多个Task(线程)来执行具体任务
Spark Application程序运行时三个核心概念:Job、Stage、 Task,说明如下:
- Job:由多个 Task 的并行计算部分,一般 Spark 中的 action 操作(如 save、collect,后面进一步说明),会 生成一个 Job。
- Stage:Job 的组成单位,一个 Job 会切分成多个 Stage ,Stage 彼此之间相互依赖顺序执行,而每个 Stage 是多 个 Task 的集合,类似 map 和 reduce stage。
- Task:被分配到各个 Executor 的单位工作内容,它是 Spark 中的最小执行单位,一般来说有多少个 Paritition (物理层面的概念,即分支可以理解为将数据划分成不同 部分并行处理),就会有多少个 Task,每个 Task 只会处 理单一分支上的数据。
StandAlone HA 模式(最理想模式)
Spark Standalone集群是Master-Slaves架构的集群模式,和大部分的Master-Slaves结构集群一样,存在着Master 单点故障(SPOF)的问题(一个主节点多个子节点,如果主节点故障则集群瘫痪)。
Spark提供了两种方案:
1.基于文件系统的单点恢复(Single-Node Recovery with Local File System)--只能用于开发或测试环境。
2.基于zookeeper的Standby Masters(Standby Masters with ZooKeeper)--可以用于生产环境。
具体原理是:ZooKeeper提供了一个Leader Election机制,设置多个 Master,但是在服务启动后只会有一个 Master 能在 ZooKeeper 中注册成为领导主节点,其他 Master 为监听状态(随时等待上位),当Master 主节点注册完成后,Spark 的 worker 节点也会和 zookeeper 通信确认现任领导(活跃的 Master) ,然后和其建立联系组成集群工作。当活跃的 Master 出故障时,处于监听的Master 立马上位,在短时间内与 worker 节点取得联系并进入正常工作。由于集群的信息 ,包括Worker, Driver和Application的信息都已经持久化到文件系统,因此在切换的过程中只会影响新Job的提交,对 于正在进行的Job没有任何的影响。加入ZooKeeper的集群整体架构如下图所示。
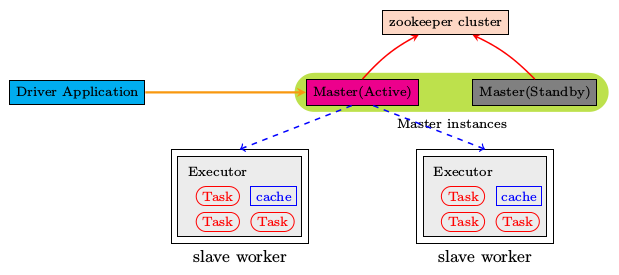
环境准备
- 启动 zookeeper 和 HDFS
- 启动 zookeeper:
/export/server/zookeeper/bin/zkServer.sh start在需要需要设置备份 Master 的节点上都执行该启动程序,zookeeper 的集群节点需要手动启动,不会自动启动 - 启动 HDFS:
start-dfs.sh
- Spark 配置文件修改
- 不指定 Master 运行的机器:先在
spark-env.sh中,删除或注释:SPARK_MASTER_HOST=anjhon - 在
spark-env.sh中新增配置项: - 分发文件到其他集群节点
- (如果 standalone 集群已启动则)停止集群:
hadoop@anjhon:/export/server/spark$ sbin/stop-all.sh
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=anjhon:2181,anjhon2:2181,anjhon3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha" # spark.deploy.recoveryMode 指定HA模式 基于Zookeeper实现 # 指定Zookeeper的连接地址 # 指定在Zookeeper中注册临时节点的路径
hadoop@anjhon:/export/server/spark/conf$ scp spark-env.sh anjhon2:$PWDhadoop@anjhon:/export/server/spark/conf$ scp spark-env.sh anjhon3:$PWD启动 standalone HA
- 在第一个节点上启动集群:
hadoop@anjhon:/export/server/spark$ sbin/start-all.sh
- 在其他节点上启动 Master:
hadoop@anjhon2:/export/server/spark$ sbin/start-master.sh
- 如果想设置更多的备用 Master,在其他节点依次开启即可。开启之前注意 zookeeper 的开启
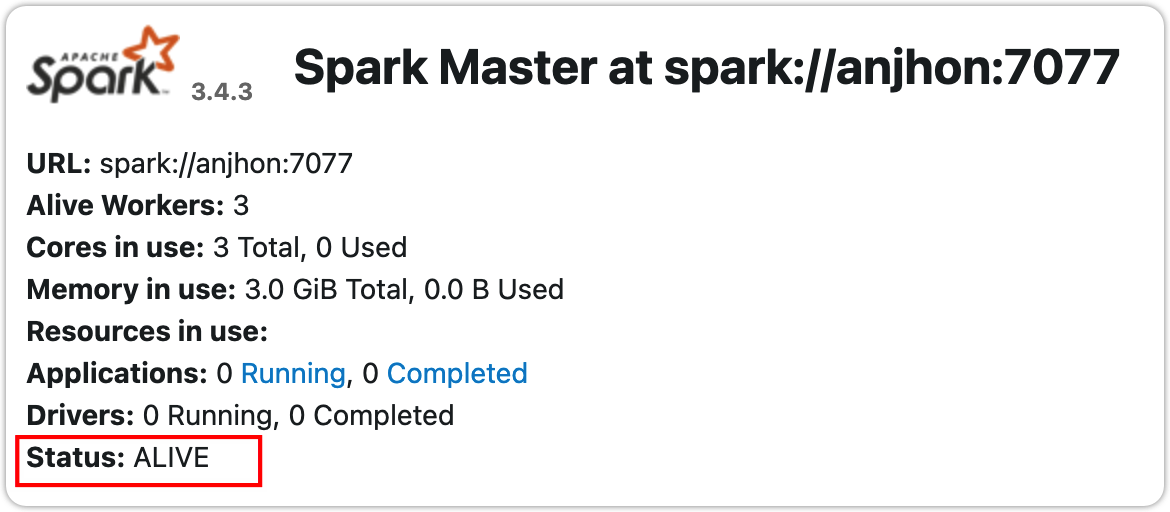
- 在浏览器监看 Master 节点的 8080 端口(端口可能顺延)可以查看 Master 运行状态。如果正常启动,则必定有一个 Master 处于活跃状态(ALIVE),其他的都是待命状态(STANDBY),如果是主备切换过程中则显示恢复中(RECOVER)。
遇到问题
- 问题一:启动之后所有的 Master 都处于 STANDBY 待命状态,没有活跃的 Master
- 怀疑时环境的问题,重启 zookeeper、hdfs 等服务,未解决
- 活跃的 Master 由 zookeeper 注册决定,没有活跃的 Master 说明 大概率是 zookeeper 没在干活。
- 检查 zookeeper 状态,发现提示如下:
Error contacting service. It is probably not running.确定时 zookeeper 的问题 - 检查所有节点防火墙对 zookeeper 的端口 2181、2888、3888 的放行状态
- 检查所有节点的 zookeeper 配置文件
- 最后发现是其他节点的 zookeeper 服务没有启动(以为只需要启动一个,其他的就会跟着启动了;但是 zookeeper 中所有节点都需要手动启动)最终解决问题。
主备切换测试
- 在 anjhon2 上任务,指定 Master 为 anjhon 上的:
hadoop@anjhon2:/export/server/spark$ ./bin/spark-submit --master spark://anjhon:7077 /export/server/spark/examples/src/main/python/pi.py 1000
- 在 anjhon 上 kill 掉 Master 进程,相当于任务在运行的过程中,Master 故障了,正常情况下备用的 Master 应该会马上接管集群并继续执行任务,切换过程约 30 秒左右
24/07/18 19:59:55 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 24/07/18 20:00:20 WARN StandaloneAppClient$ClientEndpoint: Connection to anjhon:7077 failed; waiting for master to reconnect... 24/07/18 20:00:20 WARN StandaloneSchedulerBackend: Disconnected from Spark cluster! Waiting for reconnection... 24/07/18 20:00:20 WARN StandaloneAppClient$ClientEndpoint: Connection to anjhon:7077 failed; waiting for master to reconnect... Pi is roughly 3.138240
Spark On Yarn(最常用模式)
按照前面环境部署中所学习的, 如果我们想要一个稳定的生产Spark环境, 那么最优的选择就是构建:HA StandAlone集 群。不过在企业中, 服务器的资源总是紧张的, 许多企业不管做什么业务,都基本上会有Hadoop集群. 也就是会有YARN集群。对于企业来说,在已有YARN集群的前提下在单独准备Spark StandAlone集群,对资源的利用就不高. 所以, 在企业中,多 数场景下,会将Spark运行到YARN集群中.
YARN本身是一个资源调度框架, 负责对运行在内部的计算框架进行资源调度管理. 作为典型的计算框架, Spark本身也是直接运行在YARN中, 并接受YARN的调度的。所以, 对于Spark On YARN, 无需部署Spark集群, 只要找一台服务器, 充当Spark的客户端, 即可提交任务到YARN集群 中运行.
Spark On Yarn的本质:
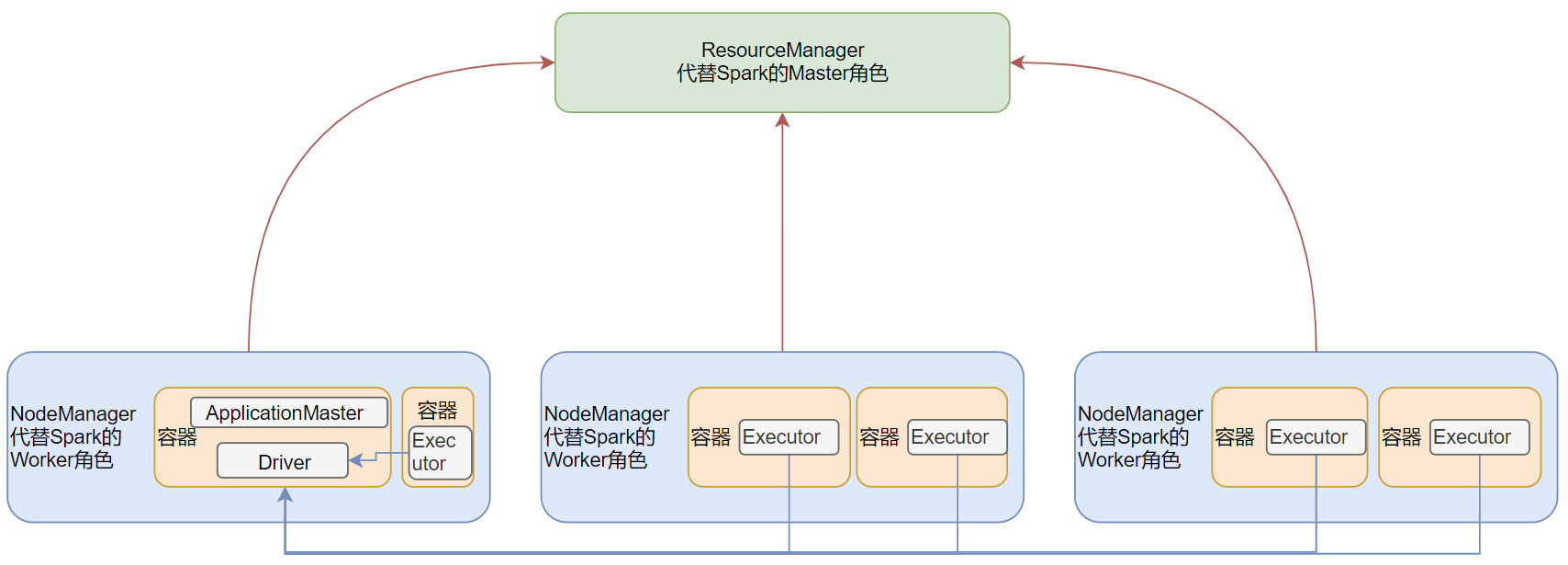
将资源管理的活儿(Master、Worker)交个 Yarn,Spark只关注程序运行层面(Driver、Executor)
- Master角色由YARN的ResourceManager担任.
- Worker角色由YARN的NodeManager担任.
- Driver角色运行在YARN容器内 或 提交任务的客户端进程中
- 真正干活的Executor运行在YARN提供的容器内
环境配置
只需要确保 Spark 的配置文件中有
HADOOP_CONF_DIR 和 YARN_CONF_DIR 的环境变量即可。hadoop@anjhon:/export/server/spark/conf$ vim spark-env.sh
## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群 HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
启动 Yarn 模式
- bin/pyspark
- 启动 Yarn:
hadoop@anjhon:/export/server/spark$ start-yarn.sh - 启动 Spark 的历史服务器:
hadoop@anjhon:/export/server/spark$ sbin/start-history-server.sh - 启动 Spark:
hadoop@anjhon:/export/server/spark$ bin/pyspark --master yarn - 访问 anjhon 的 8088 端口,在 Yarn 中查看 Spark 任务管理
- 运行程序:
sc.parallelize([1,2,3]).map(lambda x:x*10).collect()在 anjhon 的 4040 端口查看任务执行
- bin/spark-submit (PI)
hadoop@anjhon:/export/server/spark$ bin/spark-submit --master yarn /export/server/spark/examples/src/main/python/pi.py 100
部署模式
sSpark On YARN是有两种运行模式的,一种是Cluster模式一种是Client模式。这两种模式的区别就是Driver运行的位置.
- Cluster模式
Driver运行在YARN容器内部, 和ApplicationMaster在同一个容器内
- Cluster模式执行流程
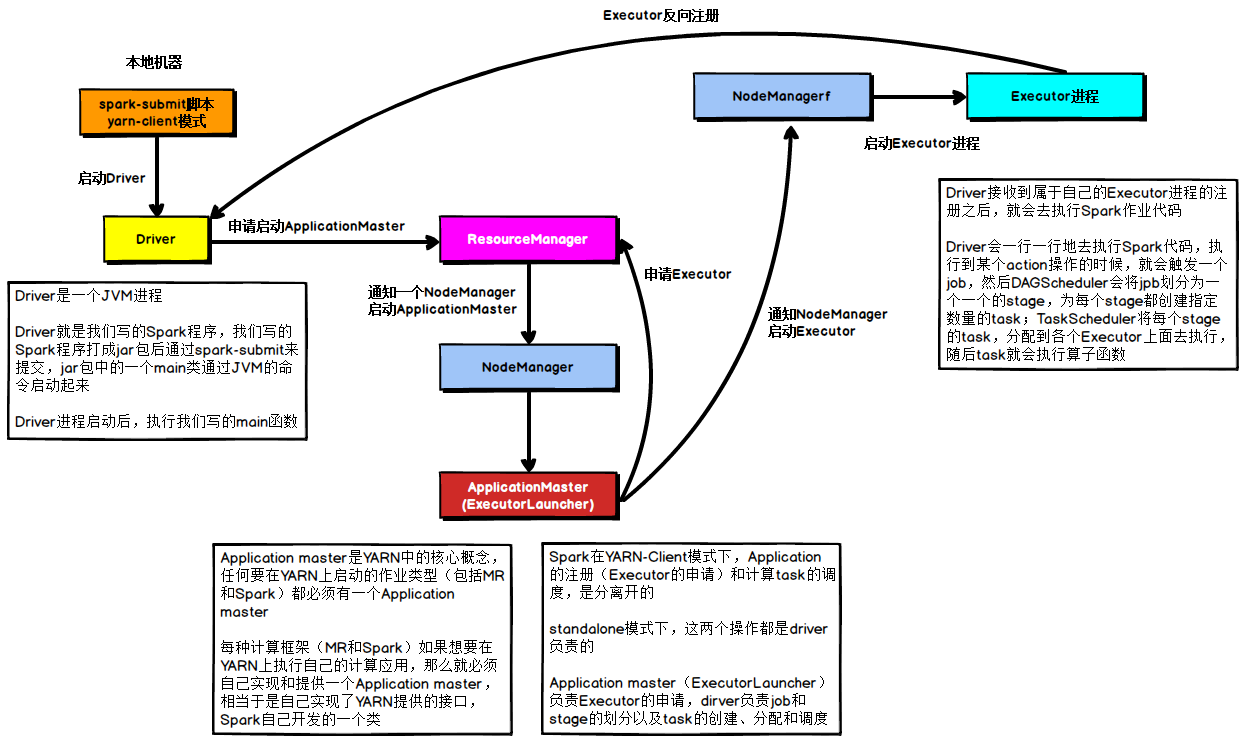
流程步骤如下:
1)、Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster ;
2)、随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的 ApplicationMaster的功能相当于一个ExecutorLaucher,只负责向ResourceManager申请Executor内存;
3)、ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后ApplicationMaster在资源分 配指定的NodeManager上启动Executor进程;
4)、Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数;
5)、之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分Stage,每个Stage生成对应的TaskSet,之后 将Task分发到各个Executor上执行。
- Cluster模式启动
hadoop@anjhon:/export/server/spark$ bin/spark-submit --master yarn --deploy-modecluster--driver-memory 512m --executor-memory 512m --num-executors 3 --total-executor-cores 3 /export/server/spark/examples/src/main/python/pi.py 100--deploy-mode client:部署模式client(默认)--driver-memory 512m:driver 内存--executor-memory 512m:executor 内存--num-executors 3:executor 个数--total-executor-cores 3:- 在 anjhon 的 18080 端口查看历史执行任务,在 8080 端口查看进程及日志
- Client模式
Driver运行在客户端进程中, 比如Driver运行在spark-submit程序的进程中
- Client模式执行流程
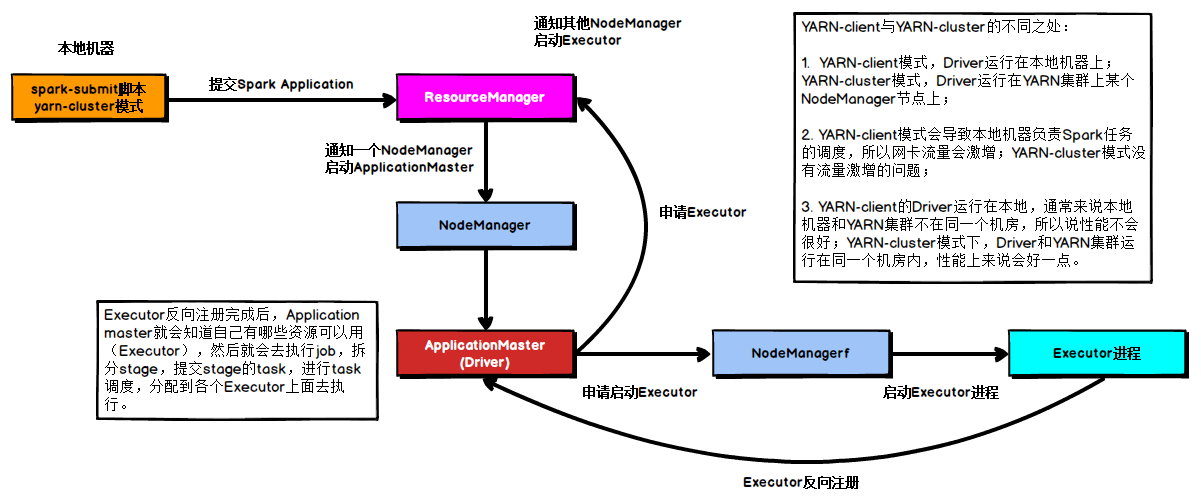
具体流程步骤如下:
1)、任务提交后会和ResourceManager通讯申请启动ApplicationMaster;
2)、随后ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,此时的 ApplicationMaster就是Driver;
3)、Driver启动后向ResourceManager申请Executor内存,ResourceManager接到ApplicationMaster的资源申请 后会分配Container,然后在合适的NodeManager上启动Executor进程;
4)、Executor进程启动后会向Driver反向注册;
5)、Executor全部注册完成后Driver开始执行main函数,之后执行到Action算子时,触发一个job,并根据宽依赖开 始划分stage,每个stage生成对应的taskSet,之后将task分发到各个Executor上执行;
- Client模式启动
hadoop@anjhon:/export/server/spark$ bin/spark-submit --master yarn --deploy-modeclient--driver-memory 512m --executor-memory 512m --num-executors 3 --total-executor-cores 3 /export/server/spark/examples/src/main/python/pi.py 100
ㅤ | Cluster模式 | Client模式 |
Driver运行位置 | YARN容器内 | 客户端进程内 |
通讯效率 | 高 | 低于Cluster模式 |
日志查看 | 日志输出在容器内, 查看不方便 | 日志输出在客户端 的标准输出流中,方 便查看 |
生产可用 | 推荐 | 不推荐 |
稳定性 | 稳定 | 基于客户端进程,受 到客户端进程影响 |
Spark On Hive
对于Hive来说,就2东西:
- SQL优化翻译器(执行引擎),翻译SQL到MapReduce并提交到YARN执行
- MetaStore 元数据管理中心
对于Spark来说,自身是一个 执行引擎,但是 Spark自己没有元数据管理功能,所以Spark On Hive就是 Spark 借用 Hive 的元数据管理服务,然后使用 Spark 自身的执行引擎。
根据原理,就是Spark能够连接上Hive的MetaStore就可以了。所以部署原理是:
- MetaStore需要存在并开机
- Spark知道MetaStore在哪里(IP 端口号)
环境配置
- 在 spark 的 conf 目录中,创建
hive-site.xml文件
<configuration> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://anjhon:9083</value> </property> </configuration>
- 确保 Hive 的
hive-site.xml文件中有元数据服务的配置
<property> <name>hive.metastore.uris</name> <value>thrift://anjhon:9083</value> </property>
在 Spark 中创建表,在 Hive 中查看
- 确保 Hive 的元数据服务已经启动
- 在终端建表检测
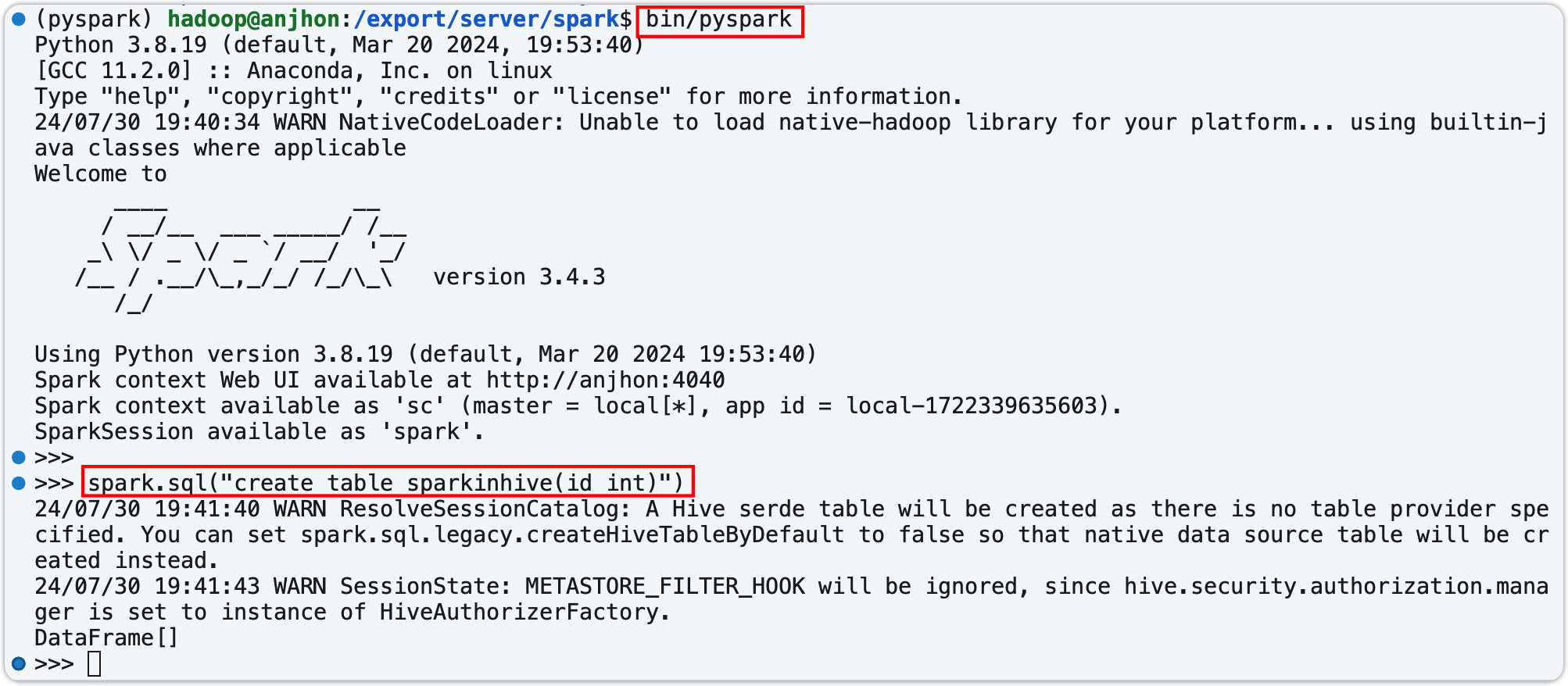
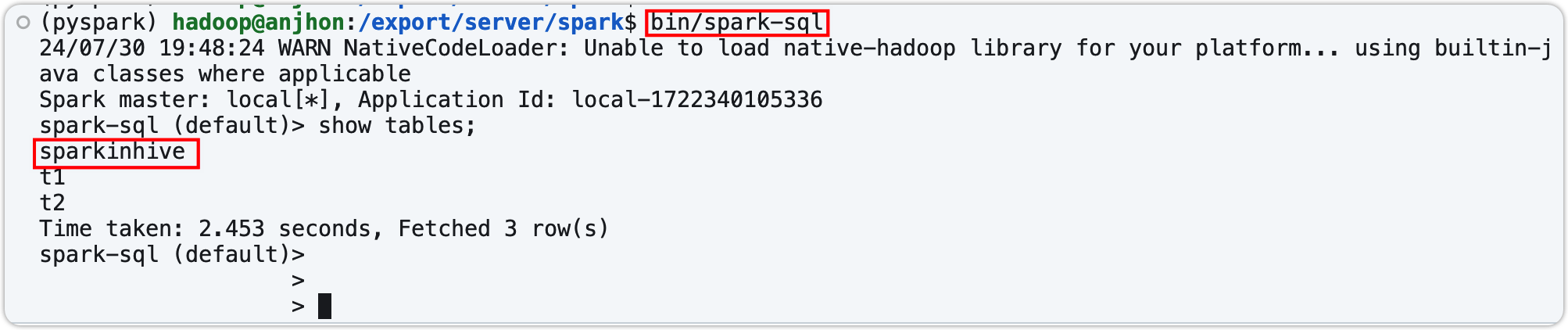
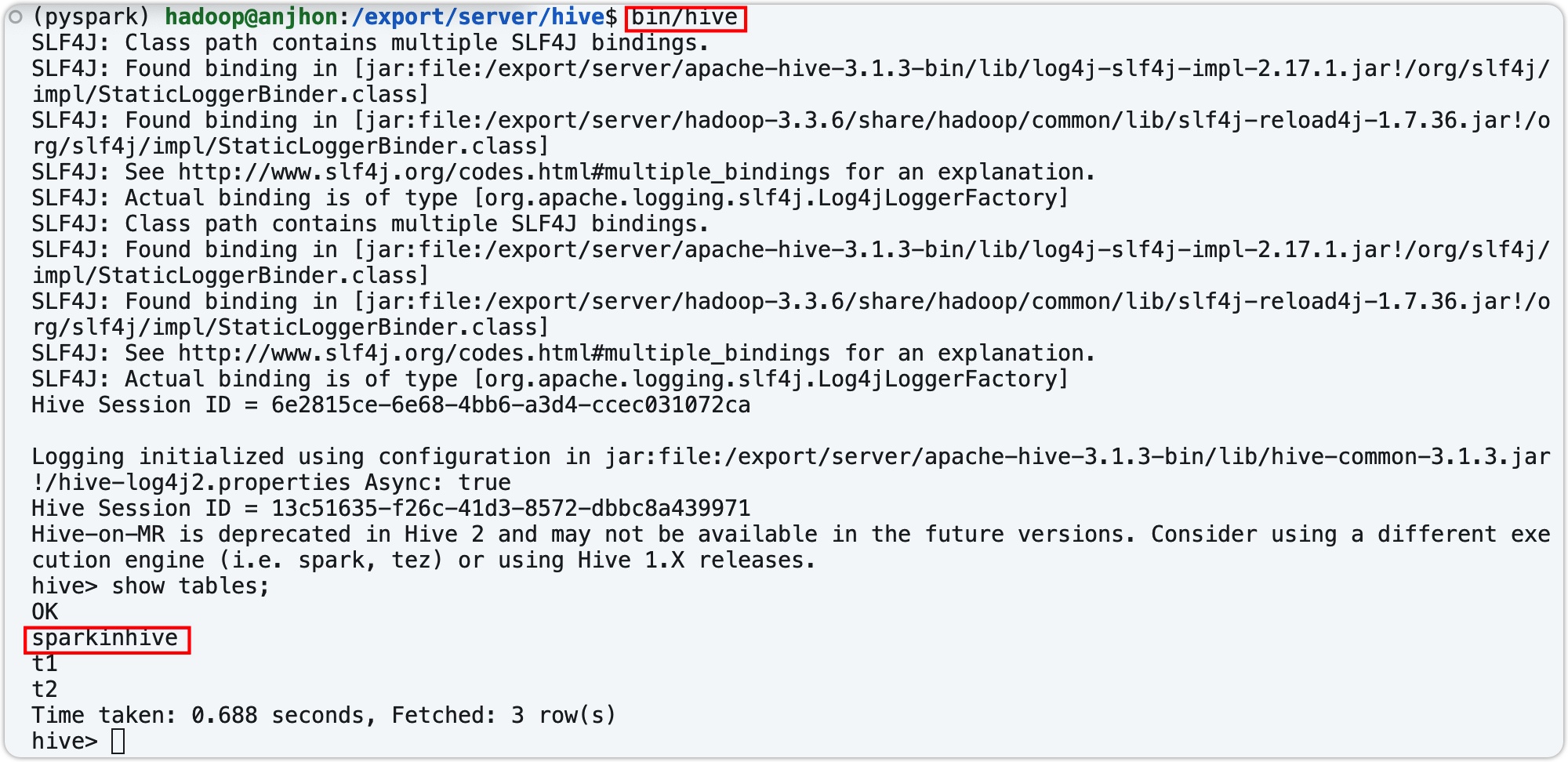
- 在代码中连接 Hive 元数据服务,并直接查表
from pyspark.sql import SparkSession if __name__ == '__main__': # 创建 SparkSession 并配置 JAR 文件路径 spark = SparkSession.builder \ .appName('spark on hive') \ .master('local[3]') \ .config('spark.sql.shuffle.partitions', 3) \ .config('spark.sql.warehouse.dir', 'hdfs://anjhon:8020/user/hive/warehouse') \ .config('hive.metastore.uris', 'thrift://anjhon:9083')\ .enableHiveSupport() \ .getOrCreate() sc = spark.sparkContext try: spark.sql("select * from t1").show() finally: spark.stop()
Spark ThriftServer
Spark中有一个服务叫做:ThriftServer服务,可以启动并监听在 10000 端口;这个服务对外提供功能,我们可以用数据库工具或者代码连接上来 直接写SQL即可操作spark
启动服务:
- 确保已经配置好了 Spark On Hive
- 启动 spark thriftserver 服务
start-thriftserver.sh --hiveconf hive.server2.thrift.port=10000 --hiveconf hive.server2.thrift.bind.host=anjhon --master local[3]
- 在 DBeaver 中连接至 Spark 数据库
- 在 python 代码中链接至 Spark 数据库
- pyhive 包
- 为了安装pyhive包需要安装一堆linux软件,执行如下命令进行linux软件安装:yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel libffi-devel gcc make gcc-c++ python-devel cyrus-sasl-devel cyrus-sasl-plain cyrus-sasl-gssapi -y
- 安装pyhive 及相关包:/export/server/anaconda3/envs/pyspark/bin/python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyhive pymysql sasl thrift thrift_sasl
from pyhive import hive if __name__ == '__main__': # 获取到Hive(Spark ThriftServer的链接) conn = hive.Connection(host="node1", port=10000, username="hadoop") # 获取一个游标对象 cursor = conn.cursor() # 执行SQL cursor.execute("SELECT * FROM student") # 通过fetchall API 获得返回值 result = cursor.fetchall() print(result)
PySpark
PySpark 是 Apache Spark 的 Python API,允许数据科学家和工程师利用 Spark 的强大功能进行大规模数据处理和分析。它结合了 Python 的易用性和 Spark 的分布式计算能力,广泛用于处理和分析大数据集。
本地环境准备
PySpark的开发模式一般是本地写代码,提交到 Spark 集群上去运行。所以需要配置本地的开发环境。我一直使用的是VScode,所以接下来都是基于 VScode 的介绍和教程。
- 在 VScode 中创建一个 pyspark 的虚拟环境(详细教程见本站的《Python虚拟环境》)
- 配置远程开发环境
- 将本地主机与服务器的 ssh 免密连接配置好,教程详见本站的《Linux 基础》
- 安装 VScode 插件 Remote Development
- 在Remote Development 插件内连接服务器集群(按照下面三步执行完成后会要求选择 condif 路径,Linux 服务器的配置路径一般是第一个)
- Linux 中的 conda 是使用 root 账户安装的,所以只有用 root 用户登陆才能使用 pyspark 虚拟环境
- 如果要删除主机,需要去.ssh/config文件中删除对应的信息(VSCode没有删除按钮)
运行环境测试
import os from pyspark import SparkConf, SparkContext if __name__ == '__main__': # 设置配置 conf = SparkConf().setMaster("local[*]").setAppName("WordCountHelloWorld") # 如果使用 submit 客户端来提交代码,则需要删除.setMaster("local[*]")设置s # 创建或获取现有的 SparkContext sc = SparkContext.getOrCreate(conf=conf) # 更改日志级别,选择适合你的级别 sc.setLogLevel("WARN") # 输出警告和错误 try: # file_rdd = sc.textFile("hdfs://anjhon:8020/input/words.txt") # hdfs 中的文件 file_rdd = sc.textFile("file:///root/words.txt") # Linux 中的文件(一般不建议使用,因为当前主机上有的文件在其他节点上不一定有相同的文件) words_rdd = file_rdd.flatMap(lambda line: line.split(" ")) print("Initial RDD: ", words_rdd.take(5)) # 检查初始 RDD 数据 words_with_one_rdd = words_rdd.map(lambda x: (x, 1)) print("Mapped RDD: ", words_with_one_rdd.take(5)) # 检查映射后的 RDD 数据 result_rdd = words_with_one_rdd.reduceByKey(lambda a, b: a + b) print("Reduced RDD: ", result_rdd.take(5)) # 检查 reduceByKey 后的 RDD 数据 # 打印结果 print(result_rdd.collect()) finally: # 停止 SparkContext 以释放资源 sc.stop()
注意点:
- 如果使用 submit 客户端来提交代码,则需要删除.setMaster("local[*]")设置s
- Linux 中的文件(一般不建议使用,因为当前主机上有的文件在其他节点上不一定有相同的文件)
遇到问题:
AttributeError: Can't get attribute 'PySparkRuntimeError' on <module 'pyspark.errors.exceptions.base' from '/export/server/spark/python/lib/pyspark.zip/pyspark/errors/exceptions/base.py'>这通常与 PySpark 的版本、Spark版本、cloudpickle版本的不匹配或环境设置问题有关。
我的是PySpark 的版本与Spark版本不一致导致的,spark version 3.4.3,pyspark Version: 3.5.1。将pyspark的版本也安装成 3.4.3 之后问题解决。
Python On Spark 执行原理
PySpark宗旨是在不破坏Spark已有的运行时架构,在Spark架构外层包装一层Python API,借助Py4j实现Python和 Java的交互,进而实现通过Python编写Spark应用程序,其运行时架构如下图所示。
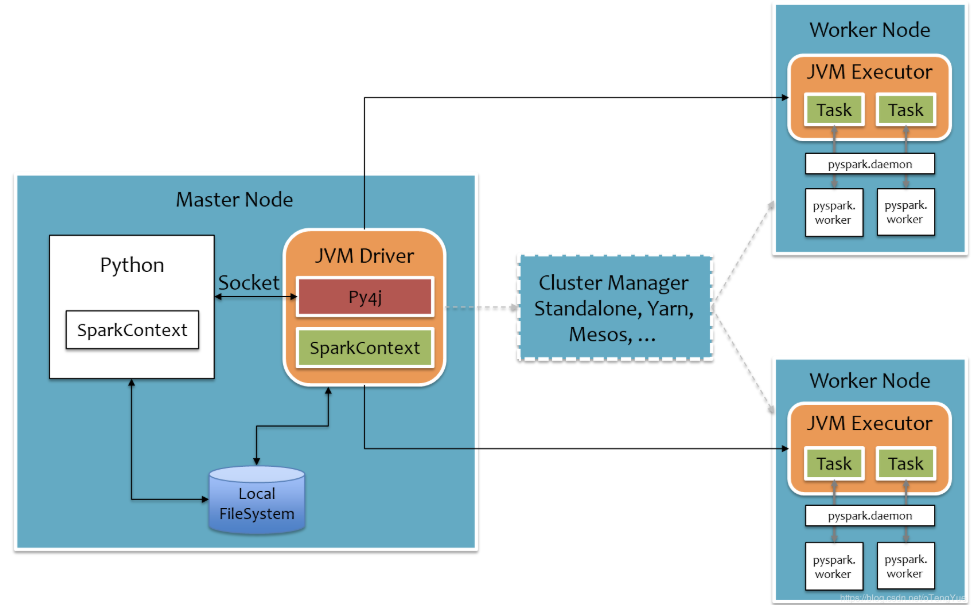
- Python Driver:用户编写的 Python 程序(Driver)会在本地机器上运行。
- Py4J Gateway:PySpark 使用 Py4J(一个使 Python 可以调用 Java 代码的库)将 Python 代码转换成 JVM(Java Virtual Machine)可以执行的命令。Py4J Gateway 在 Python 端和 JVM 端之间建立了一个通信桥梁。
- SparkContext:在 Driver 中创建的
SparkContext对象是与 Spark 集群交互的主要接口。SparkContext初始化后,会通过 Py4J 向 JVM 发送命令来初始化 Spark 的核心组件。
- 任务调度:Driver 程序将任务(Task)分发到集群中的各个 Executor 上运行。任务被分配到 Executor 后,会被序列化并通过网络传输到 Executor 端。
- 任务执行:Executor 端接收到任务后,使用 JVM 执行任务。Python 代码会通过 Py4J 被传递到 JVM 中执行,并与 JVM 端的 Spark API 交互。
- 结果返回:任务执行完成后,Executor 会将结果返回给 Driver 程序。