type
Post
status
Published
summary
SparkSQL 是 Spark 的一个模块,专为处理结构化数据而设计,提供了对 SQL 查询的支持,使得用户可以通过 SQL 或 DataFrame API 进行高效的数据处理和分析。SparkSQL 允许无缝地在结构化数据(如 JSON、Parquet、Hive 表)和 RDD 之间进行转换,集成了 Catalyst 优化器和 Tungsten 执行引擎,从而实现查询优化和高效执行。此外,SparkSQL 还支持与多种数据源的集成,使其在大数据处理和分析领域具有广泛的应用。
slug
bigdata-spark-SparkSQL
date
Aug 2, 2024
tags
大数据
Spark
SparkSQL
category
大数据
password
icon
URL
Property
Aug 5, 2024 08:28 AM
SparkSQL 是 Spark 的一个模块,专为处理结构化数据而设计,提供了对 SQL 查询的支持,使得用户可以通过 SQL 或 DataFrame API 进行高效的数据处理和分析。SparkSQL 允许无缝地在结构化数据(如 JSON、Parquet、Hive 表)和 RDD 之间进行转换,集成了 Catalyst 优化器和 Tungsten 执行引擎,从而实现查询优化和高效执行。此外,SparkSQL 还支持与多种数据源的集成,使其在大数据处理和分析领域具有广泛的应用。
SparkSQL是非常成熟的海量结构化数据处理框架. SparkSQL支持SQL语言\性能强\可以自动优化\API简单\兼容HIVE等等;SparkSQL:使用简单、API统一、兼容HIVE、支持 标准化JDBC和ODBC连接
SparkSQL的数据抽象
- SchemaRDD对象(已废弃)
- DataSet对象:可用于Java、Scala语言
- DataFrame对象:可用于Java、Scala、Python 、R
DataFrame和RDD都是:弹性的、分布式的、数据集 只是,DataFrame存储的数据结构“限定”为:二维表结构化数 据 而RDD可以存储的数据则没有任何限制,想处理什么就处理什么
相同点是DataFrame和RDD都是分布式的分区处理的
SparkSession 对象
在RDD阶段,程序的执行入口对象是:SparkContext;在Spark 2.0后,推出了SparkSession对象,作为Spark编码的统一入口对象。
SparkSession对象可以:
- 用于SparkSQL编程作为入口对象
- 用于SparkCore编程,可以通过SparkSession对象中获取到SparkContext
所以,后续的代码,执行环境入口对象,统一变更为SparkSession对象
from pyspark.sql import SparkSession if __name__ == "__main__": # 创建 SparkSession spark = SparkSession.builder.appName("spark_sql_create").master('local[3]').getOrCreate() # 获取 SparkContext sc = spark.sparkContext # 读取 CSV 文件,不包含 header,因此 header 参数应为 False df = spark.read.csv('file:///home/hadoop/pyspark_project/data/stu_score.txt', sep=',', header=False) # 将 DataFrame 的列重命名 df2 = df.toDF('id', 'name', 'score') # 打印 DataFrame 的 Schema df2.printSchema() # 显示 DataFrame 的数据 df2.show() df2.createTempView("score") spark.sql(""" select * from score where name='语文' limit 5; """).show() df2.where('name == "语文"').limit(5).show() # 停止 SparkSession spark.stop()
DataFrame
DataFrame 介绍
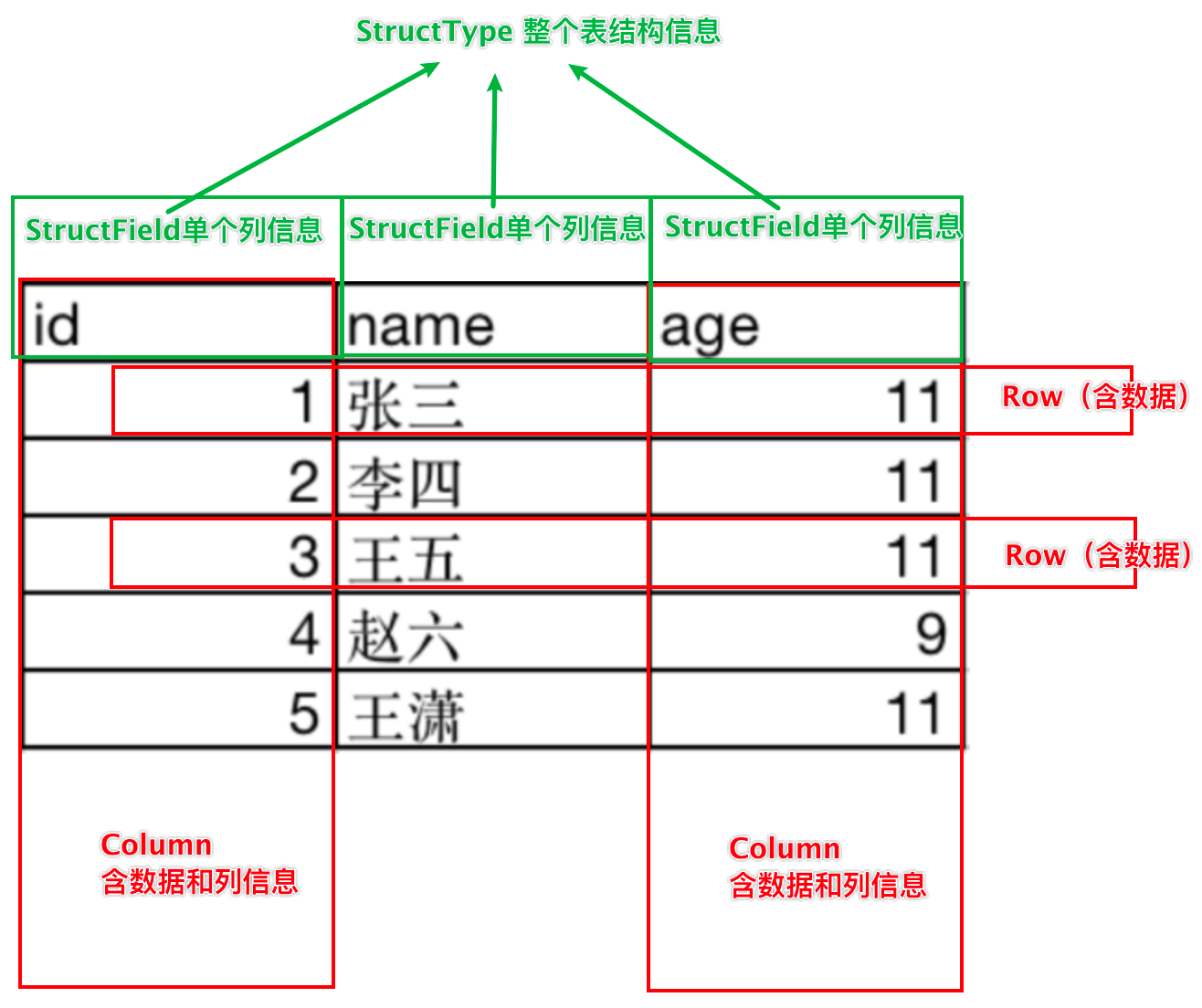
DataFrame是一个二维表结构, 那么表格结构就有无法 绕开的三个点:行、列、表结构描述。
基于这个前提,DataFrame的组成如下:
- 在结构层面:
- StructType对象描述整个DataFrame的表结构
- StructField对象描述一个列的信息
- 在数据层面
- Row对象记录一行数据
- Column对象记录一列数据并包含列的信息

DataFrame 创建
通过 rdd 和 pands DataFrame 创建
import pandas as pd from pyspark.sql import SparkSession from pyspark.sql.types import StructType, StringType, IntegerType if __name__ == '__main__': spark = SparkSession.builder.appName('dataframe_create').master('local[3]').getOrCreate() sc = spark.sparkContext #### 开头的s小写,并且没有括号 try: rdd = sc.textFile('file:///home/hadoop/pyspark_project/data/sql/people.txt').\ map(lambda line: line.split(',')).\ map(lambda x: [x[0],int(x[1])]) schema1=['name','age'] schema2 = StructType().add('name', StringType(), nullable=True).\ add('age', IntegerType(), nullable=False) # nullable=False 是否允许为空 df1 = spark.createDataFrame(rdd, schema=schema1) df1.printSchema() # 打印表结构 df1.show(20, truncate=False) # 打印表数据,默认前 20 条,默认truncate=True(内容截断) df2 = spark.createDataFrame(rdd, schema=schema2) df2.printSchema() df2.show(20, truncate=False) df3 = rdd.toDF(schema2) df3.printSchema() df3.show(20, truncate=False) # 通过 pandas DataFrame 创建 pdf = pd.read_csv('pyspark_project/data/sql/people.txt') df4 = spark.createDataFrame(pdf, schema2) df4.printSchema() df4.show() df4.createOrReplaceTempView('people') # 将 df 转换成临时表(视图),就可以通过 SQL 语句查询 spark.sql('select * from people where age > 20').show() finally: spark.stop()
通过统一风格的 API 创建数据
from pyspark.sql import SparkSession from pyspark.sql.types import StructType, StringType, IntegerType if __name__ == '__main__': spark = SparkSession.builder.appName('dataframe_create').master('local[3]').getOrCreate() sc = spark.sparkContext #### 开头的s小写,并且没有括号 try: schema_text = StructType().add('data', StringType(), nullable=True) df_text = spark.read.format('text').schema(schema=schema_text).load('file:///home/hadoop/pyspark_project/data/sql/people.txt') df_text.printSchema() df_text.show() df_json = spark.read.format('json').load('file:///home/hadoop/pyspark_project/data/sql/people.json') df_json.printSchema() df_json.show() df_csv = spark.read.format('csv').option('sep',';').option('header',True).schema("name STRING, age INT, job STRING").load('file:///home/hadoop/pyspark_project/data/sql/people.csv') df_csv.printSchema() df_csv.show() df_parquet = spark.read.format('parquet').load('file:///home/hadoop/pyspark_project/data/sql/users.parquet') df_parquet.printSchema() df_parquet.show() finally: spark.stop() ### 语法 # spark.read.format().schema().option().load() # format:指定文件格式;可选:text|csv|json|parquet|orc|avro|jdbc|...... # text:读取的文件只能作为一列放进 DataFrame 中,如果不指定列名,那么默认列名为 value # json:json 文件可以自动识别列名和列类型,一般不需要指定 schema # csv:csv 文件需要通过option 选项指定数据分隔符,数据是否包含表头,数据列名和数据类型等 # parquet: 是Spark中常用的一种列式存储文件格式 和Hive中的ORC差不多, parquet对比普通的文本文件的区别: # ● parquet 内置schema (列名\ 列类型\ 是否为空) # ● 存储是以列作为存储格式 # ● 存储是序列化存储在文件中的(有压缩属性体积小) # schema:指定数据列的相关信息;可以使用的格式:StructType | String # StructType:指定列名、数据类型、是否允许为空 # StructType().add('data', StringType(), nullable=True) # String:指定列名、数据类型,不指定是否允许为空 # schema("name STRING, age INT, job STRING") # load:指定文件路径;支持本地路径和 hdfs 路径 # option:指定一些特殊属性:sep、header、encoding
DataFrame 基操
DataFrame支持两种风格进行编程:DSL风格、SQL风格
DSL语法风格
领域特定语言。 其实就是指DataFrame的特有API DSL风格意思就是以调用API的方式来处理Data 比如:df.where().limit()
from pyspark.sql import SparkSession from pyspark.sql.types import StructType, StringType, IntegerType if __name__ == '__main__': spark = SparkSession.builder.appName('dataframe_create').master('local[3]').getOrCreate() sc = spark.sparkContext #### 开头的s小写,并且没有括号 try: df_csv = spark.read.format('csv').schema("id INT, subject STRING, score INT").load('file:///home/hadoop/pyspark_project/data/stu_score.txt') df_csv.printSchema() # df_csv.show() df_csv.select(['id', 'score']).show() df_csv.select('id', 'score').show() df_csv.select(df_csv['id'], df_csv['score']).show() # filter方法与where方法效果相同 df_csv.filter("score < 99").show() df_csv.filter(df_csv['score'] < 99).show() df_csv.where("score < 99").show() df_csv.where(df_csv['score'] < 99).show() # groupBy的返回值是一个GroupedData对象,不是 dataframe;groupBy后一般接聚合函数,常见的聚合函数有:count、sum、avg、max、min;使用聚合函数后返回的数据依然还是 dataframe; df_csv.groupBy('subject').count().show() df_csv.groupBy(df_csv['subject']).count().show() finally: spark.stop()
SQL语法风格
使用SQL语句处理DataFrame的数据 比如:spark.sql(“SELECT * FROM xxx) —— 想使用SQL风格的语法,需要将DataFrame注册成表
from pyspark.sql import SparkSession from pyspark.sql.types import StructType, StringType, IntegerType if __name__ == '__main__': spark = SparkSession.builder.appName('dataframe_create').master('local[3]').getOrCreate() sc = spark.sparkContext #### 开头的s小写,并且没有括号 try: df_csv = spark.read.format('csv').schema("id INT, subject STRING, score INT").load('file:///home/hadoop/pyspark_project/data/stu_score.txt') df_csv.printSchema() # df_csv.show() df_csv.createTempView('score1') # 创建一个临时视图 df_csv.createOrReplaceTempView('score2') # 创建一个临时视图,如果存在则替换 df_csv.createGlobalTempView('score3') # 创建全局临时视图 spark.sql('select subject, count(1) cnt from score1 group by subject').show() spark.sql('select subject, count(1) cnt from score2 group by subject').show() spark.sql('select subject, count(1) cnt from global_temp.score3 group by subject').show() finally: spark.stop()
练习示例1:
from pyspark.sql import SparkSession from pyspark.sql import functions as F if __name__ == '__main__': spark = SparkSession.builder.appName('dataframe_create').master('local[3]').getOrCreate() sc = spark.sparkContext #### 开头的s小写,并且没有括号 try: rdd = sc.textFile('file:///home/hadoop/pyspark_project/data/words.txt') rdd = rdd.flatMap(lambda line:line.split(' ')).map(lambda word: [word]) df = rdd.toDF(['word']) df.createOrReplaceTempView('words') spark.sql('select word, count(1) as cnt from words group by word order by cnt desc').show() df = spark.read.format('text').load('file:///home/hadoop/pyspark_project/data/words.txt') df2 = df.withColumn('value', F.explode(F.split(df.value, ' '))) df2.groupBy('value').count().withColumnRenamed('count', 'cnt').withColumnRenamed('value', 'word').orderBy(F.desc('cnt')).show() finally: spark.stop()
练习示例2:
1. agg: 它是GroupedData对象的API, 作用是 在里面可以写多个聚合
2. alias: 它是Column对象的API, 可以针对一个列 进行改名
3. withColumnRenamed: 它是DataFrame的API, 可以对DF中的列进行改名, 一次改一个列, 改多个列 可以链式调用
4. orderBy: DataFrame的API, 进行排序, 参数1是被排序的列, 参数2是 升序(True) 或 降序 False
5. first: DataFrame的API, 取出DF的第一行数据, 返回值结果是Row对象.
# Row对象 就是一个数组, 你可以通过row['列名'] 来取出当前行中, 某一列的具体数值. 返回值不再是DF 或者GroupedData 或者Column而是具体的值(字符串, 数字等)
from pyspark.sql import SparkSession from pyspark.sql import functions as F import time if __name__ == '__main__': spark = SparkSession.builder.appName('dataframe_create').master('local[3]').config('spark.sql.shuffle.partitions', 3).getOrCreate() """ spark.sql.shuffle.partitions 参数指的是, 在sql计算中, shuffle算子阶段默认的分区数是200个. 对于集群模式来说, 200个默认也算比较合适 如果在local下运行, 200个很多, 在调度上会带来额外的损耗 所以在local下建议修改比较低 比如2\4\10均可 这个参数和Spark RDD中设置并行度的参数 是相互独立的. """ sc = spark.sparkContext #### 开头的s小写,并且没有括号 try: df = spark.read.format('csv').\ option('sep', '\t').\ option('header', False).\ schema("user_id STRING, movie_id STRING, rank INT, timestamp STRING").\ load("file:///home/hadoop/pyspark_project/data/sql/u.data") # 统计用户打出的平均分 df.groupBy('user_id').\ avg('rank').\ withColumnRenamed('avg(rank)', 'avg_rank').\ withColumn('avg_rank', F.round(F.col('avg_rank'), 2)).\ orderBy('avg_rank', ascending=False).\ show() # 统计电影的平均分 df.createOrReplaceTempView('user_movie') spark.sql("select movie_id, round(avg(rank), 2) as avg_rank from user_movie group by movie_id order by avg_rank desc").show() # 统计大于平均分的电影的数量 print(df.where(df.rank > df.agg(F.avg(df.rank)).collect()[0][0]).count()) # df.agg:允许你在一个或多个列上应用聚合函数,agg 方法可以接受一个字典,其中键是列名,值是要应用的聚合函数,或者直接传递聚合表达式。 # 统计高分电影打分次数最多的用户的平均打分 user_id = df.where(df.rank > 3).\ groupBy('user_id').\ count().\ withColumnRenamed('count', 'cnt').\ orderBy('cnt', ascending=False).\ first()['user_id'] print(user_id) df.filter(df.user_id == user_id).\ select(F.round(F.avg(df.rank), 2)).\ show() # 统计每个用户的平均分、最低分、最高分 df.groupBy('user_id').\ agg( F.round(F.avg(df.rank), 2).alias('avg_rank'), F.min(df.rank).alias('min_rank'), F.max(df.rank).alias('max_rank') ).show() # 统计评分超过 100 次的电影的平均分top10 df.groupBy('movie_id').\ agg( F.count(df.rank).alias('cnt'), F.round(F.avg(df.rank), 2).alias('avg_rank') # ).where('cnt > 100').\ # 两种方法都行 ).where(F.col('cnt') > 100).\ orderBy('avg_rank', ascending=False).\ show(10) # time.sleep(10000) finally: spark.stop()
DataFrame 数据清洗
from pyspark.sql import SparkSession if __name__ == '__main__': spark = SparkSession.builder.appName('dataframe_create').master('local[3]').config('spark.sql.shuffle.partitions', 3).getOrCreate() sc = spark.sparkContext #### 开头的s小写,并且没有括号 try: df = spark.read.format('csv').\ option('sep', ';').\ option('header', True).\ load("file:///home/hadoop/pyspark_project/data/sql/people.csv") df.dropDuplicates().show() df.dropDuplicates(['age','job']).show() df.dropna().show() df.dropna(thresh=3).show() # 至少 3 个有效列才保留 df.dropna(thresh=2, subset=['name','age']).show() # 在['name','age']列中判断,至少 2 个有效列才保留 df.fillna('loss').show() df.fillna('loss', subset=['job']).show() # 只对 job 列填充 df.fillna({'name': 'unknown', 'age': 0, 'job': 'unemployed'}).show() # 对不同的列填充不同的值 finally: spark.stop()
DataFrame 数据写出
from pyspark.sql import SparkSession from pyspark.sql import functions as F if __name__ == '__main__': spark = SparkSession.builder.appName('dataframe_create').master('local[3]').config('spark.sql.shuffle.partitions', 3).getOrCreate() sc = spark.sparkContext #### 开头的s小写,并且没有括号 try: df = spark.read.format('csv').\ option('sep', '\t').\ option('header', False).\ schema("user_id STRING, movie_id STRING, rank INT, timestamp STRING").\ load("file:///home/hadoop/pyspark_project/data/sql/u.data") # Write text 写出, 只能写出一个列的数据, 需要将df转换为单列df df.select(F.concat_ws("---", "user_id", "movie_id", "rank", "timestamp")).\ write.\ mode("overwrite").\ format("text").\ save("file:///home/hadoop/pyspark_project/data/output/text") # Write csv df.write.mode("overwrite").\ format("csv").\ option("sep", ";").\ option("header", True).\ save("file:///home/hadoop/pyspark_project/data/output/csv") # Write json df.write.mode("overwrite").\ format("json").\ save("file:///home/hadoop/pyspark_project/data/output/json") # Write parquet df.write.mode("overwrite").\ format("parquet").\ save("file:///home/hadoop/pyspark_project/data/output/parquet") finally: spark.stop()
通过JDBC读写数据库
from pyspark.sql import SparkSession from pyspark.sql import functions as F if __name__ == '__main__': # 创建 SparkSession 并配置 JAR 文件路径 spark = SparkSession.builder \ .appName('dataframe_create') \ .master('local[3]') \ .config('spark.jars', '/export/server/miniconda3/envs/pyspark/lib/python3.8/site-packages/pyspark/jars/mysql-connector-java-8.0.26.jar') \ .config('spark.sql.shuffle.partitions', 3) \ .getOrCreate() sc = spark.sparkContext try: df = spark.read.format('csv') \ .option('sep', '\t') \ .option('header', False) \ .schema("user_id STRING, movie_id STRING, rank INT, timestamp STRING") \ .load("file:///home/hadoop/pyspark_project/data/sql/u.data") # 写入 df.write.mode('overwrite') \ .format('jdbc') \ .option('url', 'jdbc:mysql://anjhon:3306/bigdata?useSSL=false&useUnicode=true') \ .option('dbtable', 'movie_data') \ .option('user', 'root') \ .option('password', '32924ayd') \ .option('driver', 'com.mysql.cj.jdbc.Driver') \ .save() # 读取 df2 = spark.read.format('jdbc') \ .option('url', 'jdbc:mysql://anjhon:3306/bigdata?useSSL=false&useUnicode=true') \ .option('dbtable', 'movie_data') \ .option('user', 'root') \ .option('password', '32924ayd') \ .option('driver', 'com.mysql.cj.jdbc.Driver') \ .load() df2.printSchema() df2.show() finally: spark.stop()
遇到问题
问题提示
(pyspark) hadoop@anjhon:~$ /export/server/miniconda3/envs/pyspark/bin/python /home/hadoop/pyspark_project/02_SQL/12_dataframe_jdbc.py 24/07/28 22:52:34 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Traceback (most recent call last): File "/home/hadoop/pyspark_project/02_SQL/12_dataframe_jdbc.py", line 15, in <module> df.write.mode('overwrite').\ File "/export/server/miniconda3/envs/pyspark/lib/python3.8/site-packages/pyspark/sql/readwriter.py", line 1396, in save self._jwrite.save() File "/export/server/miniconda3/envs/pyspark/lib/python3.8/site-packages/py4j/java_gateway.py", line 1322, in __call__ return_value = get_return_value( File "/export/server/miniconda3/envs/pyspark/lib/python3.8/site-packages/pyspark/errors/exceptions/captured.py", line 169, in deco return f(*a, **kw) File "/export/server/miniconda3/envs/pyspark/lib/python3.8/site-packages/py4j/protocol.py", line 326, in get_return_value raise Py4JJavaError( py4j.protocol.Py4JJavaError: An error occurred while calling o49.save. : java.lang.ClassNotFoundException: com.mysql.cj.jdbc.Driver at java.net.URLClassLoader.findClass(URLClassLoader.java:387) at java.lang.ClassLoader.loadClass(ClassLoader.java:418) at java.lang.ClassLoader.loadClass(ClassLoader.java:351) at org.apache.spark.sql.execution.datasources.jdbc.DriverRegistry$.register(DriverRegistry.scala:46) at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.$anonfun$driverClass$1(JDBCOptions.scala:103) at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.$anonfun$driverClass$1$adapted(JDBCOptions.scala:103) at scala.Option.foreach(Option.scala:407) at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.<init>(JDBCOptions.scala:103) at org.apache.spark.sql.execution.datasources.jdbc.JdbcOptionsInWrite.<init>(JDBCOptions.scala:246) at org.apache.spark.sql.execution.datasources.jdbc.JdbcOptionsInWrite.<init>(JDBCOptions.scala:250) at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:47) at org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand.run(SaveIntoDataSourceCommand.scala:47) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult$lzycompute(commands.scala:75) at org.apache.spark.sql.execution.command.ExecutedCommandExec.sideEffectResult(commands.scala:73) at org.apache.spark.sql.execution.command.ExecutedCommandExec.executeCollect(commands.scala:84) at org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.$anonfun$applyOrElse$1(QueryExecution.scala:98) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:118) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:195) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:103) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:827) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:65) at org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:98) at org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:94) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:512) at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:104) at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:512) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:31) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:267) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:263) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:31) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:31) at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:488) at org.apache.spark.sql.execution.QueryExecution.eagerlyExecuteCommands(QueryExecution.scala:94) at org.apache.spark.sql.execution.QueryExecution.commandExecuted$lzycompute(QueryExecution.scala:81) at org.apache.spark.sql.execution.QueryExecution.commandExecuted(QueryExecution.scala:79) at org.apache.spark.sql.execution.QueryExecution.assertCommandExecuted(QueryExecution.scala:133) at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:856) at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:387) at org.apache.spark.sql.DataFrameWriter.saveInternal(DataFrameWriter.scala:360) at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:247) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:374) at py4j.Gateway.invoke(Gateway.java:282) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182) at py4j.ClientServerConnection.run(ClientServerConnection.java:106) at java.lang.Thread.run(Thread.java:750)
解决
将MySQL 的数据连接驱动放到正确位置(/export/server/miniconda3/envs/pyspark/lib/python3.8/site-packages/pyspark/jars)并在代码中配置相关路径(.config('spark.jars', '/export/server/miniconda3/envs/pyspark/lib/python3.8/site-packages/pyspark/jars/mysql-connector-java-8.0.26.jar'))和 driver(.option('driver', 'com.mysql.cj.jdbc.Driver')) 以方便程序找到驱动进行连接
SparkSQL函数定义
无论Hive还是SparkSQL分析处理数据时,往往需要使用函数,SparkSQL模块本身自带很多实现公共功能的函数,在pyspark.sql.functions中。
SparkSQL与Hive一样支持定义函数:UDF和UDAF,尤其是UDF函数在实际项目中使用最为广泛。
回顾Hive中自定义函数有三种类型:
- 第一种:UDF (User-Defined-Function)函数
- 一对一的关系,输入一个值经过函数以后输出一个值;
- 在Hive中继承UDF类,方法名称为evaluate,返回值不能为void,其实就是实现一个方法;
- 第二种:UDAF (User-Defined Aggregation Function) 聚合函数
- 多对一的关系,输入多个值输出一个值,通常与groupBy联合使用;
- 第三种:UDTF (User-Defined Table-Generating Functions) 函数
- 一对多的关系,输入一个值输出多个值 (一行变为多行);
- 用户自定义生成函数,有点像flatMap;
SparkSQL 定义UDF函数
- UDF 是用户自定义函数,接收一行中的一个或多个列作为输入,并返回一个标量值。通常用于数据转换或自定义计算。如:对单个值进行操作,比如将字符串转换为大写、计算数值的平方等。
- UDAF 是用户自定义聚合函数,接收一组值作为输入,并返回一个标量值。通常用于聚合操作,如求和、平均值等。如:对一组值进行聚合操作,比如计算列的平均值、最大值等。
- UDTF 是用户自定义表生成函数,接收一行中的一个或多个列作为输入,并返回多行和多列。通常用于将一行拆分为多行。如:将一行数据转换成多行数据,例如解析嵌套结构或拆分数组。
PySpark 不直接支持定义 UDAF 和 UDTF。但是可以通过 mappartitions 算子来模拟实现 UDAF,通过定义 UDF 函数然后返回 array 类型、dict 类型来模拟实现 UDTF 函数
import string from pyspark.sql import SparkSession from pyspark.sql import functions as F from pyspark.sql.types import IntegerType, ArrayType, StringType, MapType if __name__ == '__main__': # 创建 SparkSession 并配置 JAR 文件路径 spark = SparkSession.builder \ .appName('dataframe_create') \ .master('local[3]') \ .config('spark.jars', '/export/server/miniconda3/envs/pyspark/lib/python3.8/site-packages/pyspark/jars/mysql-connector-java-8.0.26.jar') \ .config('spark.sql.shuffle.partitions', 3) \ .getOrCreate() sc = spark.sparkContext def num_ride_10(data): return data*10 def splite_str(data): return data.split(' ') def get_dict(data): return {data: string.ascii_letters[data]} try: rdd = sc.parallelize([1,2,3,4,5,6,7]).map(lambda x: [x]) df = rdd.toDF(['num']) # 创建 UDF 方式一 # 参数一:udf1:udf 函数名称,仅可用于 SQL 风格 # 参数二:num_ride_10:处理函数名称 # 参数三:IntegerType:返回值类型 # 返回值:udf1是一个 UDF 对象,仅可用于 DSL 语法 udf2 = spark.udf.register('udf1', num_ride_10, IntegerType()) df.selectExpr("udf1(num)").show() # 以 SQL 表达式执行,只能使用 udf 函数名称 df.select(udf2(df.num)).show() # 以 DSL 语法执行,只能使用 udf 返回值 # 创建 UDF 方式二 udf3 = F.udf(num_ride_10, IntegerType()) df.select(udf3(df.num)).show() # 只能以以 DSL 语法执行,只能使用 udf 返回值 ### 返回 Array 类型的数据 rdd2 = sc.parallelize([['hadoop hive spark'],['hive flink jave']]) df2 = rdd2.toDF(['lins']) udf4 = spark.udf.register('split_str', splite_str, ArrayType(elementType=StringType())) df2.selectExpr("split_str(lins)").show(truncate=False) df2.select(udf4(df2.lins)).show(truncate=False) udf5 = F.udf(f=splite_str, returnType=ArrayType(elementType=StringType())) df2.select(udf5(df2.lins)).show(truncate=False) ### 返回字典类型的数据 rdd3 = sc.parallelize([[1],[2],[3],[4]]) df3 = rdd3.toDF(['num']) udf6 = spark.udf.register('udf_dict', get_dict, MapType(keyType=IntegerType(), valueType=StringType())) df3.selectExpr("udf_dict(num)").show() df3.select(udf6(df3.num)).show() udf7 = F.udf(f=get_dict, returnType=MapType(keyType=IntegerType(), valueType=StringType())) df3.select(udf7(df3.num)).show() finally: spark.stop()
SparkSQL 定义UDAF函数
from pyspark.sql import SparkSession if __name__ == '__main__': # 创建 SparkSession 并配置 JAR 文件路径 spark = SparkSession.builder \ .appName('dataframe_create') \ .master('local[3]') \ .config('spark.jars', '/export/server/miniconda3/envs/pyspark/lib/python3.8/site-packages/pyspark/jars/mysql-connector-java-8.0.26.jar') \ .config('spark.sql.shuffle.partitions', 3) \ .getOrCreate() sc = spark.sparkContext def data_process(data): num = 0 for row in data: num += row['num'] # 每一行都是一个 row 对象,row['num'] 就是 num 列的值 return [num] # 一定要返回一个 list 对象,因为 mappartition 函数要求返回一个 list 对象 try: rdd = sc.parallelize([1,2,3,4,5,6,7], 3).map(lambda x: [x]) df = rdd.toDF(['num']) df.show() single_partition_rdd = df.rdd.repartition(1) # 将df转换为rdd,然后重新分区为单分区 print(single_partition_rdd.collect()) mpp_rdd = single_partition_rdd.mapPartitions(data_process) # 使用 mappartitions 函数,传入自定义的函数,实现 udaf 的聚合效果 print(mpp_rdd.collect()) finally: spark.stop()
SparkSQL 使用窗口函数
from pyspark.sql import SparkSession from pyspark.sql.types import * if __name__ == '__main__': # 创建 SparkSession 并配置 JAR 文件路径 spark = SparkSession.builder \ .appName('dataframe_create') \ .master('local[3]') \ .config('spark.jars', '/export/server/miniconda3/envs/pyspark/lib/python3.8/site-packages/pyspark/jars/mysql-connector-java-8.0.26.jar') \ .config('spark.sql.shuffle.partitions', 3) \ .getOrCreate() sc = spark.sparkContext try: df = spark.read.format('csv').option('sep', '\t').option('header', 'false').schema('name STRING, subject STRING,score INTEGER').load('file:///home/hadoop/score.txt') df.show() df.createOrReplaceTempView('stu') spark.sql('select *, avg(score) over() as avg_over from stu').show() spark.sql(""" select *, row_number() over(order by score desc) as row_num_rank, dense_rank() over(partition by subject order by score desc) as dense_rank, rank() over(order by score desc) as rank from stu """).show() spark.sql('select *, ntile(3) over(order by score desc) as percent_rank from stu').show() finally: spark.stop()
SparkSQL的运行流程
RDD 执行逻辑:代码->DAG调度器逻辑任务-> Task调度器任务分配和管理监控-> Worker干活
RDD的运行会完全按照开发者的代码执行, 如果开发者水平有限,RDD的执行效率也会受到影响。而SparkSQL会对写完的代码,执行“自动优化”, 以提升代码运行效率,避免开发者水平影响到代码执行效率。
为什么SparkSQL可以自动优化 而RDD不可以?
RDD:内含数据类型不限格式和结构 DataFrame:100% 是二维表结构,可以被针对
Catalyst优化器
SparkSQL的自动优化,依赖于:Catalyst优化器
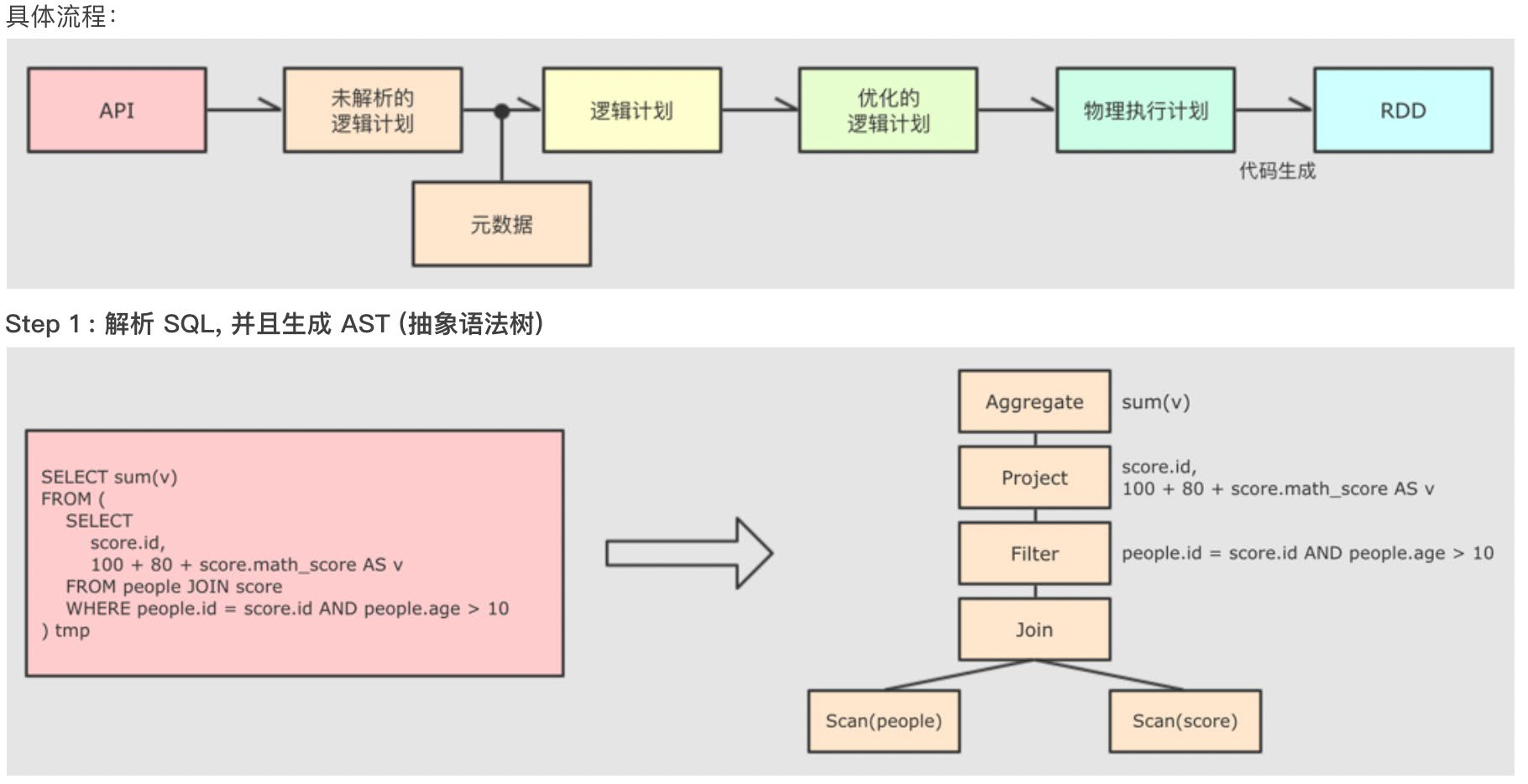
为了解决过多依赖 Hive 的问题,SparkSQL 使用了一个新的 SQL优化器替代 Hive 中的优化器,这个优化器就是 Catalyst, 整个SparkSQL 的架构大致如下:

1.API 层简单的说就是 Spark 会通过一些 API 接受 SQL 语句
2.收到 SQL 语句以后,将其交给 Catalyst, Catalyst 负责解析 SQL,生成执行计划等
3.Catalyst 的输出应该是 RDD 的执行计划
4.最终交由集群运行
Catalyst优化器的具体流程
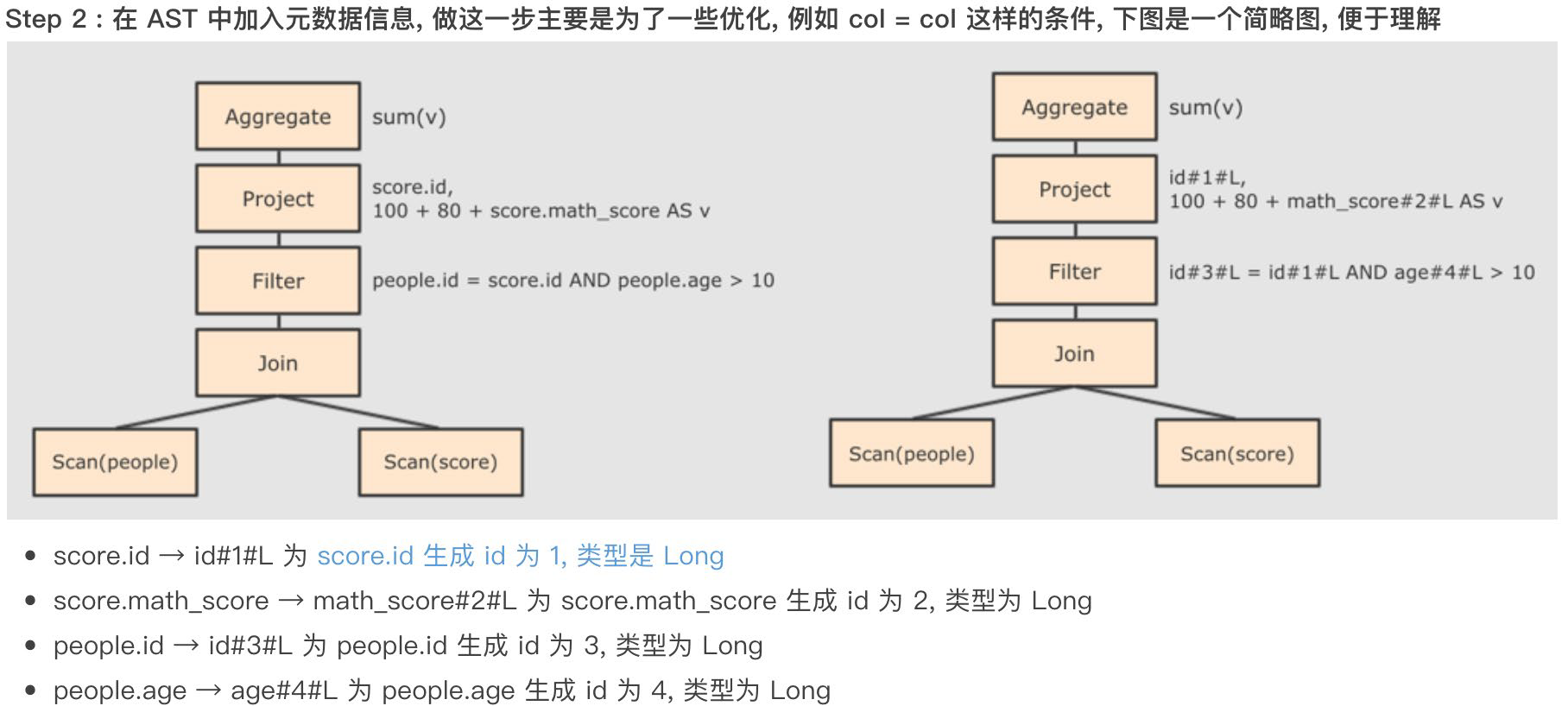
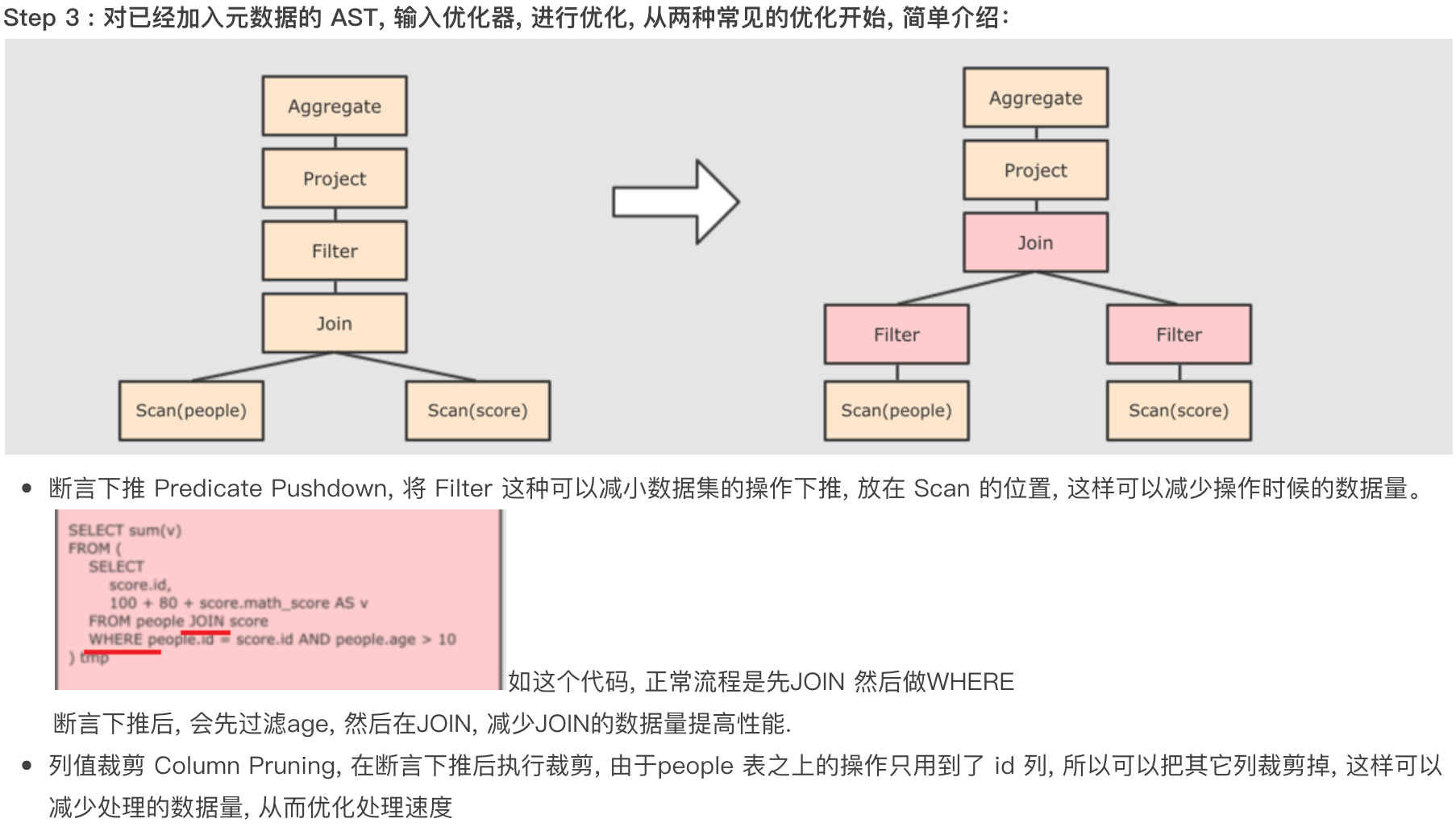
列值裁剪:在读取到数据之后就判断 select 所需要的数据列,并将不需要的列清理掉。scv、json 格式的数据是先读取在裁剪,但是 parquet 格式的文件是列式存储的,每个列单独存储,所以在读取的时候就能直接筛选。因此 parquet 格式的数据也是比较适合 spark 的数据格式
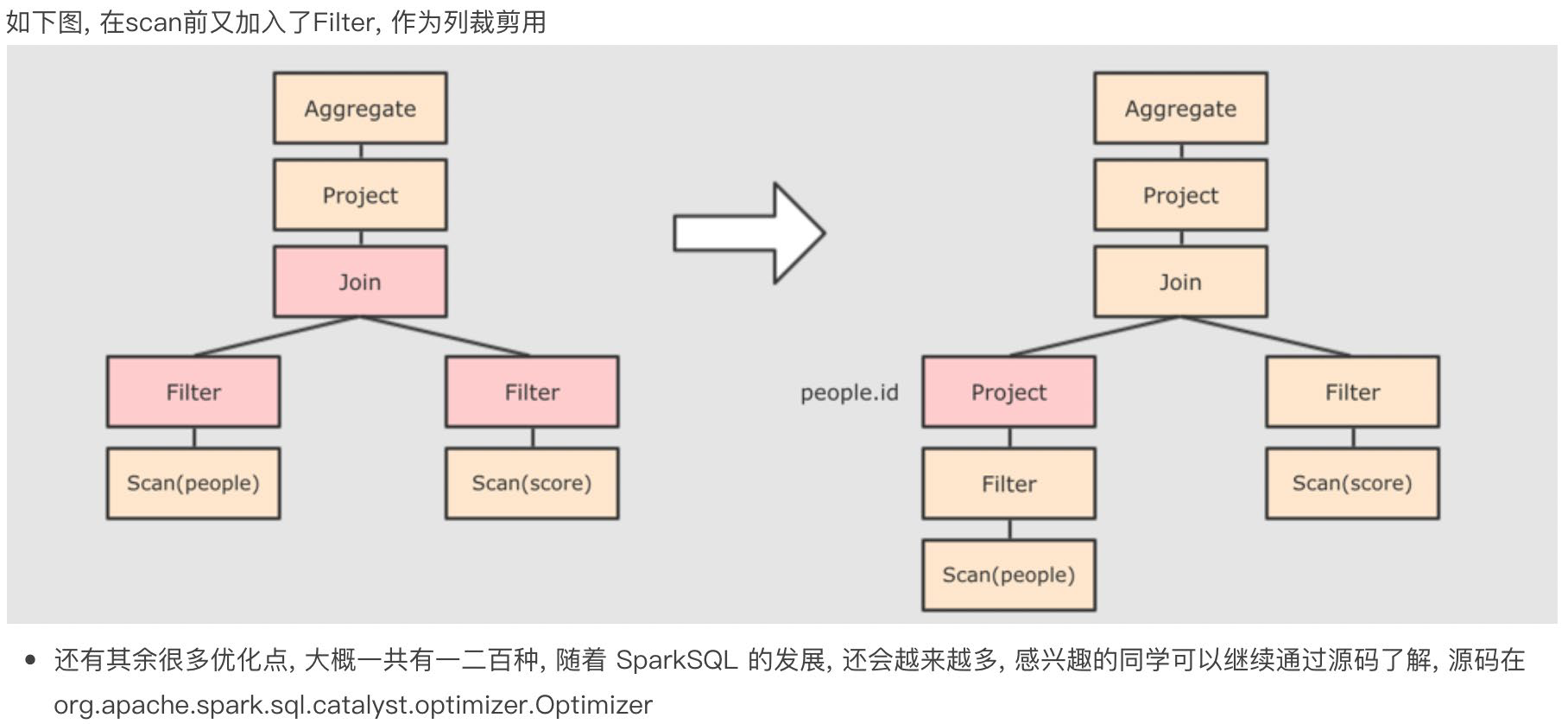

- 提交SparkSQL代码
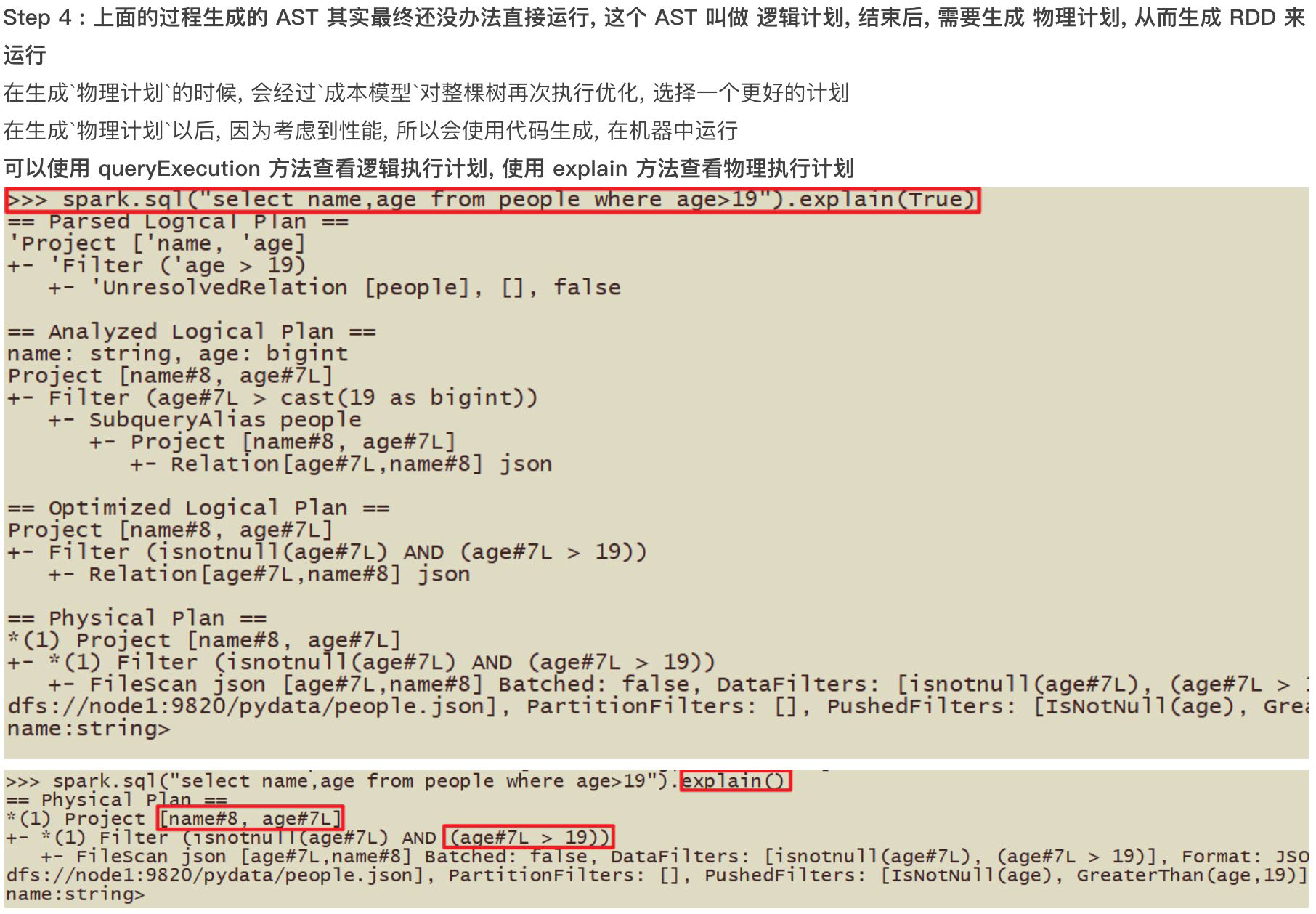
- catalyst优化 a. 生成原始AST语法数 b. 标记AST元数据 c.进行断言下推和列值裁剪 以及其它方面的优化作用在AST上 d. 将最终AST得到,生成执行计划 e. 将执行计划翻译为RDD代码
- Driver执行环境入口构建 (SparkSession)
- DAG 调度器规划逻辑任务
- TASK 调度区分配逻辑任务到具体Executor上工作并监控管理任务
- Worker干活.