type
Post
status
Published
summary
Spark Core 是 Apache Spark 的核心模块,提供了对分布式内存计算和数据处理的基础支持,基于 RDD(Resilient Distributed Dataset)这一基本数据抽象,实现了高效的并行计算和容错机制。通过 SparkContext 与集群交互,DAG Scheduler 和 Task Scheduler 调度任务执行,Block Manager 管理数据块的存储和传输,用户可以通过丰富的 RDD API 构建和执行复杂的数据处理任务。Spark Core 支持批处理、交互式查询、机器学习和图计算等多种应用场景,是 Spark 生态系统的基础。
slug
bigdata-spark-SparkCore
date
Jul 31, 2024
tags
大数据
Spark
SparkCore
category
大数据
password
icon
URL
Property
Jul 31, 2024 01:47 AM
Spark Core 是 Apache Spark 的核心模块,提供了对分布式内存计算和数据处理的基础支持,基于 RDD(Resilient Distributed Dataset)这一基本数据抽象,实现了高效的并行计算和容错机制。通过 SparkContext 与集群交互,DAG Scheduler 和 Task Scheduler 调度任务执行,Block Manager 管理数据块的存储和传输,用户可以通过丰富的 RDD API 构建和执行复杂的数据处理任务。Spark Core 支持批处理、交互式查询、机器学习和图计算等多种应用场景,是 Spark 生态系统的基础。
RDD 概念理解
分布式计算需要:分区控制、Shuffle控制、数据存储\序列化\发送、数据计算API、等一系列功能;这些功能不能简单的通过Python内置的本地集合对象(如 List\ 字典等)去完成. 我们在分布式框架中, 需要有一个统一的数据抽象对象, 来实现上述分布式计算所需功能。这个抽象对象,就是RDD。
RDD 全称为 Resilient Distributed Datasets,弹性分布式数据集。是Spark中最基本的数据抽象,代表一个不可变、可分区、里面的元素可并行计算的集合。
- Resilient:RDD中的数据可以存储在内存中或者磁盘中。
- Distributed:RDD中的数据是分布式存储的,可用于分布式计算。
- Dataset:一个数据集合,用于存放数据的。
RDD 特性
- 一个 RDD 由一个或者多个分区(Partitions)组成。对于 RDD 来说,每个分区会被一个计算任务所处理,用户可以在创建 RDD 时指定其分区个数,如果没有指定,则默认采用程序所分配到的 CPU 的核心数;
- RDD的方法会作用在其所有的分区上
- RDD 会保存彼此间的依赖关系,RDD 的每次转换都会生成一个新的依赖关系,
- 这种 RDD 之间的依赖关系就像流水线一样。在部分分区数据丢失后,可以通过这种依赖关系重新计算丢失的分区数据,而不是对 RDD 的所有分区进行重新计算;
- Key-Value 型的 RDD 还拥有 Partitioner(分区器),
- 用于决定数据被存储在哪个分区中,目前 Spark 中支持 HashPartitioner(按照哈希分区) 和 RangeParationer(按照范围进行分区);
- RDD的分区规划,会尽量靠近数据所在的服务器
- 一个优先位置列表 (可选),用于存储每个分区的优先位置 (prefered location)。对于一个 HDFS 文件来说,这个列表保存的就是每个分区所在的块的位置,按照“移动数据不如移动计算“的理念,Spark 在进行任务调度的时候,会尽可能的将计算任务分配到其所要处理数据块的存储位置。
- 在初始RDD(读取数据的时候)规划的时候,分区会尽量规划到 存储数据所在的服务器上。因为这样可以走 本地读取,避免 网络读取;本都读取 性能>>>网络读取的 本地读取:Executor所在的服务器,同样是一个DataNode,同时这个DataNode上有它要读的数据,所以可以直接读取机器硬盘即可 无需走网络传输 网络读取:读取数据,需要经过网络的传输才能读取到, Spark会在确保并行计 算能力的前提下,尽量确保本地读取;这里是尽量确保,而不是100%确保;所以这个特性也是:可能的
RDD 的创建
Spark RDD 编程的程序入口对象是SparkContext对象(不论何种编程语言) ,只有构建出SparkContext, 基于它才能执行后续的API调用和计算 本质上, SparkContext对编程来说, 主要功能就是创建第一个RDD出来。
- 通过并行化集合创建 ( 本地对象转分布式RDD )
from pyspark import SparkConf, SparkContext if __name__ == "__main__": # create a SparkContext object conf = SparkConf().setMaster("local").setAppName("RDD_create") # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: # rdd = sc.parallelize([1, 2, 3]) # 使用默认分区数 rdd = sc.parallelize([1, 2, 3], 3) # 使用指定分区数 print('默认分区数:', rdd.getNumPartitions()) print('rdd的内容:', rdd.collect()) # collect方法是将rdd中每个分区的数据都发送到driver端,然后合并成一个list finally: sc.stop()
- 读取外部数据源 ( 读取文件 )
textFile
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setMaster("local[*]").setAppName("RDD_create") # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd1 = sc.textFile("file:///root/words.txt") print('默认分区数:', rdd1.getNumPartitions()) # print('rdd 的内容:', rdd1.collect()) rdd2 = sc.textFile("file:///root/words.txt", 3) # 设置最小分区数据 print('设置分区数:', rdd2.getNumPartitions()) rdd3 = sc.textFile("file:///root/words.txt", 100) # 设置最小分区数据,如果最小分区数超过 Spark 的范围则无效 print('设置分区数:', rdd3.getNumPartitions()) rdd4 = sc.textFile("hdfs://anjhon:8020/input/words.txt", 3) # 读取 hdfs 文件 print('hdfs文件内容:', rdd4.collect()) finally: sc.stop()
wholeTextFiles(小文件批量优化)
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setMaster("local[*]").setAppName("RDD_create") # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.wholeTextFiles("file:///root/pyspark_project/data/tiny_files/") # wholeTextFiles方法更适合处理小文件集合,用于读取一组文件,将每个文件的内容作为一个元素加载到 RDD 中。 print('hdfs文件内容:', rdd.collect()) print(rdd.map(lambda x: x[1]).collect()) finally: sc.stop()
RDD 算子
方法\函数:本地对象的APl,叫做方法\函数;算子:分布式对象(RDD)的APl,叫做算子
RDD 的算子有两类:
- Transformation:转换算子
定义:RDD的算子,返回值仍旧是一个RDD的,称之为转换算子。
特性:这类算子是 Lazy 懒加载 的。如果没有action算子,Transformation算子是不工作的。
- Action:动作(行动)算子
定义:返回值不是rdd 的就是action算子。
类型 | 算子 | 功能 | 备注 |
Transformation | ㅤ | ㅤ | ㅤ |
ㅤ | map(func) | 将RDD的数据一条条处理(处理的逻辑 基于map算子中接收的处理函数),返回新的RDD | ㅤ |
ㅤ | flatMap(func) | 对rdd执行map操作,然后进行 解除嵌套操作. | ㅤ |
ㅤ | mapValues(func) | 针对 二元元组 RDD,对其内部的二元元組的 Value执行 map 操作 | 适用于 KV 型 RDD |
ㅤ | mapPartitions(func) | 与 map 算子相比,mappartition一次被传递的是一整个分区的数据,而 map 算子一次传递的是一单条数据。减少了文件传输的次数,提升 IO 性能 | ㅤ |
ㅤ | filter(func) | 过滤想要的数据进行保留 | ㅤ |
ㅤ | union(otherDataset) | 2个rdd合并成1个rdd返回;不会去重,可以合并不同类型的 rdd | ㅤ |
ㅤ | intersection(otherDataset) | 求2个rdd的交集,返回一个新rdd | ㅤ |
ㅤ | distinct([numTasks])) | 对RDD数据进行去重,返回新RDD | ㅤ |
ㅤ | glom() | 将RDD的数据,加上嵌套,这个嵌套按照分区 来进行;比如RDD数据[1,2,3,4,5] 有2个分区那么,被glom后,数据变成:[ [1,2,3],[4,5]] | ㅤ |
ㅤ | join(otherDataset, [numTasks]) | 对两个RDD执行JOIN操作(可实现SQL的内\ 外连接)join算子只能用于二元元组,关联时按照 key 关联(元组的第一个值) | 适用于 KV 型 RDD |
ㅤ | leftOuterJoin() | 对两个RDD执行JOIN操作(左外) | 适用于 KV 型 RDD |
ㅤ | rightOuterJoin() | 对两个RDD执行JOIN操作(右外) | 适用于 KV 型 RDD |
ㅤ | groupBy() | 将rdd的数据进行分组 | ㅤ |
ㅤ | groupByKey([numTasks]) | 针对KV型 RDD, 自动按照key分组。只保留 value,而 groupby 会保留 key 和 value | 适用于 KV 型 RDD,IO性能低,在分区内不会聚合 |
ㅤ | reduceByKey(func, [numTasks]) | 针对KV型 RDD,自动按照key分组,然后根据提供的聚合逻辑,完成组内数据(value)的聚合操作 | 适用于 KV 型 RDD, 在分区内先,IO 性能比 groupbyke 要高很多 |
ㅤ | sortBy(func,ascending,numPartition) | 对RDD数据进行排序,基于你指定的排序依据. | ㅤ |
ㅤ | sortByKey([ascending], [numTasks]) | 针对 KV型RDD,按照key 进行排序 | 适用于 KV 型 RDD |
ㅤ | cogroup(otherDataset, [numTasks]) | ㅤ | ㅤ |
ㅤ | cartesian(otherDataset) | ㅤ | ㅤ |
ㅤ | coalesce(numPartitions) | 对分区进行数量增减 | ㅤ |
ㅤ | partition() | ㅤ | ㅤ |
ㅤ | partitionBy() | 对RDD进行自定义分区操作 | ㅤ |
ㅤ | repartition(numPartitions) | 对RDD的分区执行重新分区(仅数量) | ㅤ |
ㅤ | repartitionAndSortWithinPartitions(partitioner) | ㅤ | ㅤ |
Action | ㅤ | ㅤ | ㅤ |
ㅤ | reduce(func) | 对RDD数据集按照你传入的逻辑进行聚合 | ㅤ |
ㅤ | flod() | 和reduce一样,接受传入逻辑进行聚合,聚合是带有初始值的 | ㅤ |
ㅤ | collect() | 将RDD各个分区内的数据,統一收集到Driver中,形成一个List对象 | ㅤ |
ㅤ | count() | 计算RDD有多少条数据,返回值是一个数字 | ㅤ |
ㅤ | first() | 取出RDD的第一个元素 | ㅤ |
ㅤ | take(n) | 取RDD的前N个元素,組合成list返回 | ㅤ |
ㅤ | top() | 对RDD数据集进行降序排序,取前N个组成 list 返回 | ㅤ |
ㅤ | takeSample(withReplacement, num, [seed]) | 随机抽样RDD的数据
參数1:True表示运行取同一个数据,False表示不允许取同一个数据.和数据内容无关,是否重复表示的是同一个位置的数据
参数2:抽样要几个
参数3:随机数种子,这个参数传入一个数字即可,随意给 | ㅤ |
ㅤ | takeOrdered(n, [ordering]) | 对RDD进行排序取前N个
参数1:要取的数据个数
参数2:对排序的数据进行更改(不会更改数据本身,只是在排序的时候换个样子)
这个方法使用按照元素自然顺序升序排序,如果想倒叙,需要用参数?来对排序的数据进行处理 | ㅤ |
ㅤ | saveAsTextFile(path) | 将RDD的数据写入文本文件中;文件数量与分区数量一致; | 直接在 excuter 中执行,不会将数据汇总到 driver |
ㅤ | saveAsSequenceFile(path) | ㅤ | ㅤ |
ㅤ | saveAsObjectFile(path) | ㅤ | ㅤ |
ㅤ | countByKey() | 统计key出现的次数(一般适用于KV型RDD) | 适用于 KV 型 RDD |
ㅤ | foreach(func) | 对RDD的每一个元素,执行提供的逻辑的操作(和map一个意思),但是这个方法没有返回值。 | 直接在 excuter 中执行,不会将数据汇总到 driver |
常用的转换算子
- map 算子
功能:将RDD的数据一条条处理(处理的逻辑 基于map算子中接收的处理函数),返回新的RDD
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('map_operate').setMaster('local[*]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize(range(10)) rdd_map = rdd.map(lambda x: x*10) print(rdd_map.collect()) finally: sc.stop()
- flatMap 算子
功能:对rdd执行map操作,然后进行 解除嵌套操作.
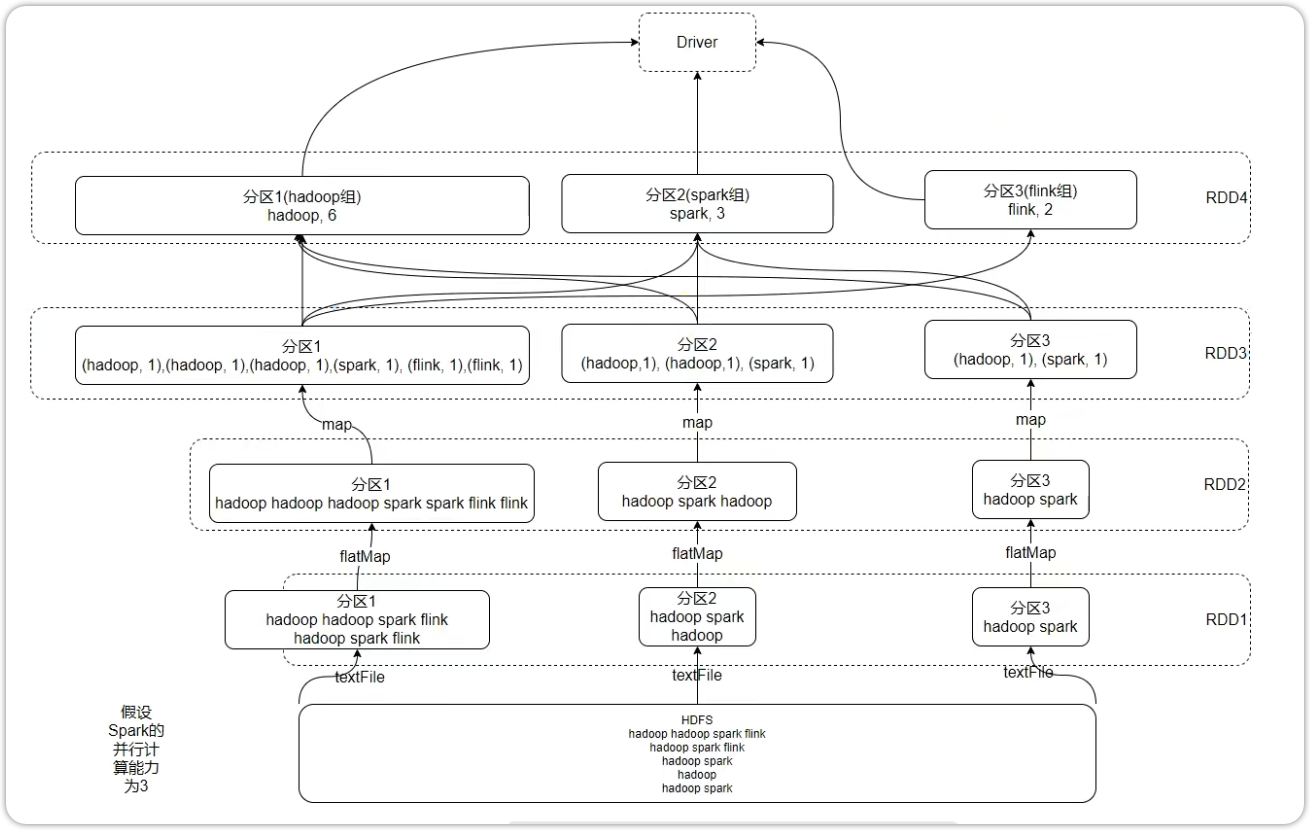
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('map_operate').setMaster('local[*]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize(['hadoop hive spark', 'spark hadoop hive']) rdd_map = rdd.map(lambda x: x.split(' ')) print(rdd_map.collect()) # [['hadoop', 'hive', 'spark'], ['spark', 'hadoop', 'hive']] rdd_flatmap = rdd.flatMap(lambda x: x.split(' ')) print(rdd_flatmap.collect()) # ['hadoop', 'hive', 'spark', 'spark', 'hadoop', 'hive'] finally: sc.stop()
- reduceByKey 算子
功能:针对KV型 RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(value)的聚合操作
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('map_operate').setMaster('local[*]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize(['hadoop hive spark', 'spark hadoop hive']) rdd_flatmap = rdd.flatMap(lambda x: x.split(' ')) print(rdd_flatmap.collect()) # ['hadoop', 'hive', 'spark', 'spark', 'hadoop', 'hive'] rdd_map = rdd_flatmap.map(lambda x: (x, 1)) print(rdd_map.collect()) rdd_reducebykey = rdd_map.reduceByKey(lambda x, y: x + y) print(rdd_reducebykey.collect()) # [('spark', 2), ('hadoop', 2), ('hive', 2)] finally: sc.stop()
reduceByKey 是对每一组 key 的 value 做计算,假如有一个 key 有 value 为 [1,2,3,4,5],则给它定义一个函数
lambda a, b: a + b 的计算逻辑如下: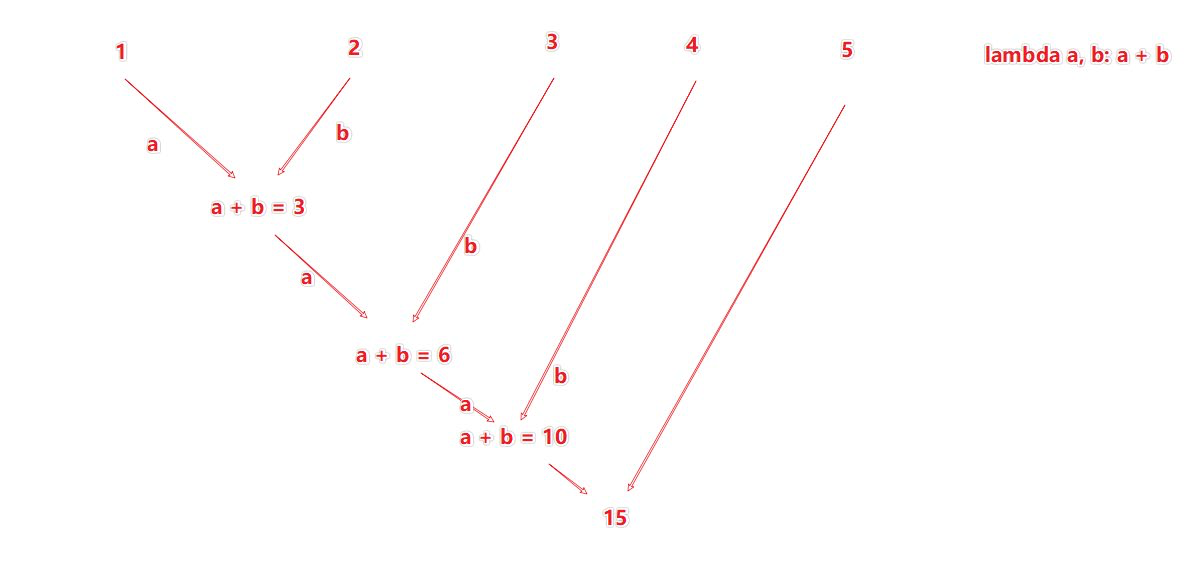
- mapValues 算子
功能:针对 二元元组 RDD,对其内部的二元元組的 Value执行 map 操作
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('map_operate').setMaster('local[*]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([('a',1), ('b',2), ('c',3)]) rdd_map = rdd.map(lambda x: (x[0], x[1]*10)) print(rdd_map.collect()) # [('a', 10), ('b', 20), ('c', 30)] rdd_mapvalues = rdd.mapValues(lambda x: x*10) print(rdd_mapvalues.collect()) # [('a', 10), ('b', 20), ('c', 30)] finally: sc.stop()
- groupBy 算子
功能:将rdd的数据进行分组
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('map_operate').setMaster('local[*]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([('a',1), ('b',2), ('a',3),( 'a',4), ('b',5)]) group_key_rdd = rdd.groupBy(lambda x: x[0]) # 按照二元组的key分组 print(group_key_rdd.collect()) # [('b', <pyspark.resultiterable.ResultIterable object at 0xffffa4144820>), ('a', <pyspark.resultiterable.ResultIterable object at 0xffffa4144910>)] group_key__list_rdd = group_key_rdd.map(lambda x: (x[0], list(x[1]))) # 将分组后的value值,变成list print(group_key__list_rdd.collect()) # [('b', [('b', 2), ('b', 5)]), ('a', [('a', 1), ('a', 3), ('a', 4)])] finally: sc.stop()
- filter 算子
功能:过滤想要的数据进行保留
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('map_operate').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([i for i in range(10)]) filter_rdd = rdd.filter(lambda x: x % 2 == 0) # 保留偶数 print(filter_rdd.collect()) # [0, 2, 4, 6, 8] finally: sc.stop()
- distinct 算子
功能:对RDD数据进行去重,返回新RDD
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('map_operate').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([1,1,1,3,3,3,5,5,5,7,7,9]) distinct_rdd = rdd.distinct() print(distinct_rdd.collect()) # [1, 3, 5, 7, 9] rdd2 = sc.parallelize([('a',1),('a',1), ('b',2),('c',3)]) distinct_rdd2 = rdd2.distinct() print(distinct_rdd2.collect()) # [('a', 1), ('b', 2), ('c', 3)] finally: sc.stop()
- union 算子
- union 算子不会去重
- union 算子可以合并不同类型的 rdd
功能:2个rdd合并成1个rdd返回
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('map_operate').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([2,4,6]) rdd2 = sc.parallelize([2,'a','a']) rdd3 = rdd.union(rdd2) # 合并两个RDD print(rdd3.collect()) # [2, 4, 6, 2, 'a', 'a'] finally: sc.stop()
- join 算子
功能:对两个RDD执行JOIN操作(可实现SQL的内\ 外连接)
注意:join算子只能用于二元元组,关联时按照 key 关联(元组的第一个值)
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('map_operate').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd1 = sc.parallelize([(1001,'张三'),(1002,'lisi'),(1003,'wangwu'),(1004,'zhaoliu')]) rdd2 = sc.parallelize([(1001,'销售部'),(1002,'科技部'),(1003,'财务部')]) rdd_join = rdd1.join(rdd2) # 连接两个RDD print(rdd_join.collect()) # [(1002, ('lisi', '科技部')), (1003, ('wangwu', '财务部')), (1001, ('张三', '销售部'))] rdd_left_join = rdd1.leftOuterJoin(rdd2) # 连接两个RDD,左表全部保留 print(rdd_left_join.collect()) # [(1002, ('lisi', '科技部')), (1003, ('wangwu', '财务部')), (1004, ('zhaoliu', None)), (1001, ('张三', '销售部'))] rdd_right_join = rdd1.rightOuterJoin(rdd2) # 连接两个RDD,右表全部保留 print(rdd_right_join.collect()) # [(1002, ('lisi', '科技部')), (1003, ('wangwu', '财务部')), (1001, ('张三', '销售部'))] finally: sc.stop()
- intersection 算子
功能:求2个rdd的交集,返回一个新rdd
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('map_operate').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd1 = sc.parallelize([(1001,'张三'),(1002,'lisi'),(1003,'wangwu'),(1004,'zhaoliu')]) rdd2 = sc.parallelize([(1001,'销售部'),(1001,'张三')]) rdd_intersection = rdd1.intersection(rdd2) print(rdd_intersection.collect()) # [(1001, '张三')] finally: sc.stop()
- glom 算子
功能:将RDD的数据,加上嵌套,这个嵌套按照分区 来进行;比如RDD数据[1,2,3,4,5] 有2个分区那么,被glom后,数据变成:[ [1,2,3],[4,5]]
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('map_operate').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd1 = sc.parallelize([(1001,'张三'),(1002,'lisi'),(1003,'wangwu'),(1004,'zhaoliu')]) print(rdd1.glom().collect()) # [[(1001, '张三')], [(1002, 'lisi')], [(1003, 'wangwu'), (1004, 'zhaoliu')]] print(rdd1.glom().flatMap(lambda x: x).collect()) # [(1001, '张三'), (1002, 'lisi'), (1003, 'wangwu'), (1004, 'zhaoliu')] finally: sc.stop()
- groupByKey 算子
功能:针对KV型 RDD, 自动按照key分组。只保留 value,而 groupby 会保留 key 和 value
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('map_operate').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([(1001,'张三'),(1001,'张二'),(1002,'lisi'),(1003,'wangwu'),(1003,'zhaoliu')]) rdd_groupbykey = rdd.groupByKey() print(rdd_groupbykey.collect()) # [(1002, <pyspark.resultiterable.ResultIterable object at 0xffff9c0bc310>), (1003, <pyspark.resultiterable.ResultIterable object at 0xffff85f6b7f0>), (1001, <pyspark.resultiterable.ResultIterable object at 0xffff85f6b8b0>)] print(rdd_groupbykey.mapValues(lambda x: list(x)).collect()) # [(1003, ['wangwu', 'zhaoliu']), (1002, ['lisi']), (1001, ['张三', '张二'])] finally: sc.stop()
- sortBy 算子
功能:对RDD数据进行排序,基于你指定的排序依据.
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('map_operate').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([('e', 2), ('r', 4), ('o', 6), ('a', 1), ('b', 3), ('c', 5)]) rdd_sortby_value = rdd.sortBy(lambda x: x[1], ascending=True, numPartitions=3) # 参数一:指定排序的列 # 参数二:是否升序 # 参数三:用来计算排序的分区数 print(rdd_sortby_value.collect()) # [('a', 1), ('e', 2), ('b', 3), ('r', 4), ('c', 5), ('o', 6)] rdd_sortby_key = rdd.sortBy(lambda x: x[0], ascending=False, numPartitions=3) print(rdd_sortby_key.collect()) # [('r', 4), ('o', 6), ('e', 2), ('c', 5), ('b', 3), ('a', 1)] finally: sc.stop()
- sortByKey 算子
功能:针对 KV型RDD,按照key 进行排序
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('map_operate').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([('e', 2), ('r', 4), ('D', 6), ('A', 1), ('b', 3), ('c', 5)]) rdd_sortByKey = rdd.sortByKey(ascending=True, numPartitions=3) # 参数一:是否升序 # 参数二:用来计算排序的分区数 # 参数三:计算前的处理函数 print(rdd_sortByKey.collect()) # [('A', 1), ('D', 6), ('b', 3), ('c', 5), ('e', 2), ('r', 4)] rdd_sortByKey_kfun = rdd.sortByKey(ascending=True, numPartitions=3, keyfunc=lambda x: x[0].lower()) # 排序按照处理后的小写排序 print(rdd_sortByKey_kfun.collect()) # [('A', 1), ('b', 3), ('c', 5), ('D', 6), ('e', 2), ('r', 4)] finally: sc.stop()
- mapPartitions 算子
与 map 算子相比,mappartition一次被传递的是一整个分区的数据,而 map 算子一次传递的是一单条数据。减少了文件传输的次数,提升 IO 性能
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9]) rdd_mapP = rdd.mapPartitions(lambda iters: [i*10 for i in iters]) print(rdd_mapP.collect()) # [10, 20, 30, 40, 50, 60, 70, 80, 90] finally: sc.stop()
- partitionBy 算子
对RDD进行自定义分区操作
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 def func_partition(k): if k == 'hadoop' or k == 'hdfs': return 0 elif k == 'hive': return 1 else: return 2 try: rdd = sc.parallelize([('hadoop', 1),('hive', 1),('spark', 1),('hdfs', 1)]) rdd_partionby = rdd.partitionBy(3, func_partition) # 分区数量和分区规则 print(rdd_partionby.glom().collect()) # [[('hadoop', 1), ('hdfs', 1)], [('hive', 1)], [('spark', 1)]] finally: sc.stop()
- repartiton 算子
对RDD的分区执行重新分区(仅数量)
注意:对分区的数量进行操作,一定要慎重,一般情况下,我们写Spark代码除了要求全局排序设置为1个分区外;多数时候,所有API中关于分区相关的代码我们都不太理会,因为,如果改分区了会影响并行计算(内存迭代的井行管道数量),如果增加,极大可能 导致 shuf fle
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([1,2,3,4,5], 3) print(rdd.repartition(1).getNumPartitions()) # 1 print(rdd.repartition(5).getNumPartitions()) # 5 finally: sc.stop()
- coalesce 算子
对分区进行数量增减
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([1,2,3,4,5], 3) print(rdd.coalesce(1).getNumPartitions()) print(rdd.coalesce(5, shuffle=True).getNumPartitions()) # 增加分区时需要shuffle=True才能生效 finally: sc.stop()
- demo 运行方式
- 直接在远程解释器中右键,运行代码
- 原因:YARN 使用层次队列系统,
root队列是顶级队列,不能直接提交任务。 - 解决:
- 切换hadoop来执行 pyspqrk 代码,在 VScode 中直接新增一个相同主机的用户,添加好之后重新加载 VScode
- 切换到 hadoop 之后,hadoop 没有 miniconda 的使用权限,无法使用虚拟环境
- 在终端中切换到 root 用户,在
/etc/profile文件中添加 conda 的环境变量到最后,保存退出 - 执行
source /etc/profiles - 执行
conda init bash - 重新打开终端
- 将 root 用户目录下的项目文件拷贝到 hadoop 用户的目录下:
cp -r ./pyspark_project /home/hadoop/ - 如果涉及到一些三方包,需要在其他集群节点都安装相应的包,如 jieba。然后按照上面的方法重新初始化其他节点的 conda 环境
- 通过 Spark-submit 提交到集群运行
运行 demo 有两种方法:
如果依赖了其他文件,那么 conf 需要额外设置一个参数(spark.submit.pyFiles)来将依赖文件同步上传到集群,可以是单个文件也可以是一个压缩包
from pyspark import SparkConf, SparkContext from functions import city_and_category import json import os # 设置环境变量 os.environ['HADOOP_CONF_DIR'] = '/export/server/hadoop/etc/hadoop' if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn1').setMaster('yarn') conf.set('spark.submit.pyFiles', '/home/hadoop/pyspark_project/01_RDD/functions.py') # 将依赖的 function.py 文件一起上传到集群 # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd_file = sc.textFile('hdfs://anjhon:8020/input/order.text') # print(rdd_file.collect()) rdd_jsons = rdd_file.flatMap(lambda line: line.split('|')) # print(rdd_jsons.collect()) rdd_dict = rdd_jsons.map(lambda x: json.loads(x)) # print(rdd_dict.collect()) rdd_beijing = rdd_dict.filter(lambda d: d['areaName']=='北京') # print(rdd_beijing.collect()) rdd_category = rdd_beijing.map(city_and_category) print(rdd_category.collect()) rdd_result = rdd_category.distinct() print(rdd_result.collect()) # ['北京_平板电脑', '北京_家具', '北京_书籍', '北京_食品', '北京_服饰', '北京_手机', '北京_家电', '北京_电脑'] finally: sc.stop()
遇到问题:
org.apache.hadoop.yarn.exceptions.YarnException: Failed to submit application_1721726386847_0002 to YARN : root is not a leaf queue
解决:
export PATH="/export/server/miniconda3/bin:$PATH"
提交命令:
(pyspark) hadoop@anjhon:/export/server/spark$ ./bin/spark-submit --master yarn --py-files /home/hadoop/pyspark_project/01_RDD/functions.py /home/hadoop/pyspark_project/01_RDD/20.2-RDD_operators_run_yarn_submit.py 命令中也需要通过
--py-files 参数指定依赖文件from pyspark import SparkConf, SparkContext from functions import city_and_category import json if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux') conf.set('spark.submit.pyFiles', '/home/hadoop/pyspark_project/01_RDD/functions.py') # 将依赖的 functions.py 文件一起上传到集群 # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd_file = sc.textFile('hdfs://anjhon:8020/input/order.text') # print(rdd_file.collect()) rdd_jsons = rdd_file.flatMap(lambda line: line.split('|')) # print(rdd_jsons.collect()) rdd_dict = rdd_jsons.map(lambda x: json.loads(x)) # print(rdd_dict.collect()) rdd_beijing = rdd_dict.filter(lambda d: d['areaName']=='北京') # print(rdd_beijing.collect()) rdd_category = rdd_beijing.map(city_and_category) # print(rdd_category.collect()) rdd_result = rdd_category.distinct() print(rdd_result.collect()) # ['北京_平板电脑', '北京_家具', '北京_书籍', '北京_食品', '北京_服饰', '北京_手机', '北京_家电', '北京_电脑'] finally: sc.stop()
常用的行动算子
- countByKey 算子
功能:统计key出现的次数(一般适用于KV型RDD)
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.textFile('file:///home/hadoop/pyspark_project/data/words.txt') rdd_flatmap = rdd.flatMap(lambda line: line.split(' ')).map(lambda x: (x,1)) rdd_countbykey = rdd_flatmap.countByKey() print(rdd_countbykey) # defaultdict(<class 'int'>, {'hello': 3, 'spark': 1, 'hadoop': 1, 'flink': 1}) print(type(rdd_countbykey)) # <class 'collections.defaultdict'> finally: sc.stop()
- collect 算子
功能:将RDD各个分区内的数据,統一收集到Driver中,形成一个List对象
注意:RDD是分布式对象,其数据量可以很大,所以用这个算子之前要心知肚明的了解结果数据集不会太大。不然,会把Driver内存撑爆
- reduce 算子
功能:对RDD数据集按照你传入的逻辑进行聚合
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([1,2,3,4,5]) print(rdd.reduce(lambda a,b: a+b)) # 15 finally: sc.stop()
- flod 算子
- 分区内聚合
- 分区问聚合
功能:和reduce一样,接受传入逻辑进行聚合,聚合是带有初始值的
这个初始值聚合,会作用在:
比如:[[1, 2,3],[4,5, 6],[7, 8, 9]] 数据分布在3个分区
分区1123 聚合的时候带上10作为初始值得到16
分区2456 聚合的时候带上10作为初始值得到25
分区3789 聚合的时候带上10作为初始值得到34
3个分区的结果做聚合也带上初始值10,所以结果是:10+16+25 + 34 = 85
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9],3) print(rdd.glom().collect()) # [[1, 2, 3], [4, 5, 6], [7, 8, 9]] print(rdd.fold(10, lambda a,b: a+b)) # 85 finally: sc.stop()
- first、take、top、count 算子
# first:取出RDD的第一个元素 sc.parallelize([1,2,3]).first() # 1 # take:取RDD的前N个元素,組合成list返回 sc.parallelize([1,2,3,4,5,6,7,8,9]).take(5) # [1, 2, 3, 4, 5] # top:对RDD数据集进行降序排序,取前N个 sc.parallelize([i for i in range(10)]).top(3) # [9, 8, 7] # count:计算RDD有多少条数据,返回值是一个数字 sc.parallelize([i for i in range(10)]).count() # 10
- takeSample 算子
功能:取出RDD的第一个元素
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9]) print(rdd.takeSample(True, 11, 10)) # [4, 8, 8, 5, 9, 8, 5, 9, 2, 3, 4] print(rdd.takeSample(False, 11, 10)) # [6, 3, 8, 2, 9, 5, 4, 7, 1] 如果取数的数量大于数组的数据量,则取出全部 print(rdd.takeSample(False, 5, 10)) # [6, 3, 8, 2, 9] # 參数1:True表示运行取同一个数据,False表示不允许取同一个数据.和数据内容无关,是否重复表示的是同一个位置的数据 # 参数2:抽样要几个 # 参数3:随机数种子,这个参数传入一个数字即可,随意给 finally: sc.stop()
- takeOrdered 算子
功能:对RDD进行排序取前N个
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9]) print(rdd.takeOrdered(5)) # [1, 2, 3, 4, 5] print(rdd.takeOrdered(5, lambda x: -x)) # [9, 8, 7, 6, 5] finally: sc.stop()
- foreach 算子
功能:对RDD的每一个元素,执行你提供的逻辑的操作(和map一个意思),但是这个方法没有返回值。直接在 excuter 中执行,不会将数据汇总到 driver
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9]) rdd.foreach(lambda x: print(x)) finally: sc.stop()
- saveAsTextFile 算子
功能:将RDD的数据写入文本文件中;文件数量与分区数量一致;直接在 excuter 中执行,不会将数据汇总到 driver
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9]) rdd.saveAsTextFile('file:///home/hadoop/pyspark_project/data/output/out1') rdd.saveAsTextFile('hdfs://anjhon:8020/input/output/out1') finally: sc.stop()
- foreachPartition 算子
和普通foreach一致,一次处理的是一整个分区数据
from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9]) rdd.foreachPartition(lambda x: [print(i*2) for i in x]) finally: sc.stop()
RDD 持久化
RDD 缓存
RDD之间进行相互迭代计算(Transformation的转换),当执行开启后,新RDD的生成,代表老RDD的消失,
RDD的数据是过程数据,只在处理的过程中存在,一旦处理完成,就不见了。如果某个中间 RDD在其他链条上再次被调用,那么该 RDD 需要从链条的开头重新执行。
RDD的缓存技术:Spark提供了缓存APl,可以让我们通过调用API,将指定的RDD数据保留在内存或者硬盘上缓存的API
缓存方法
# RDD3 被2次使用,可以加入缓存进行优化 rdd3.cache() # 缓存到内存中, rdd3.persist(StorageLeveL.MEMORY_ONLY) # 仅内存缓存 rdd3.persist(StorageLeveL.MEMORY_ONLY_2) # 仅内存緩存,2个副本 rdd3.persist(StorageLeveL.DISK_ONLY) # 仅缓存硬盘上 rdd3.persist(StorageLeveL.DISK_ONLY_2) # 仅缓存硬盘上,2个副本 rdd3.persist(StorageLeveL.DISK_ONLY_3) # 仅缓存硬盘上,3个副本 rdd3.persist(StorageLeveL.MEMORY_AND_DISK) # 先放内存,不够放硬盘 ruds.persist(StorageLeVeL.MEMORY_AND_DISK_2) # 先放内存,不够放硬盘,2个副本 rdd3.persist(StorageLeveL.OFF_HEAP) # 堆外内存(系统内存) # 如上API,自行选择使用即可 # 一般般建议使用rdd3.persist(storageLeveL.MEMORY_AND_DISK) # 如果内存比较小的集群,建议使用rdd3.persist(storageLeveL.DISK_ONLY)或者就别用缓存了用checkPoint # 主动清理缓存的API rdd.unpersist()
缓存示例
import time from pyspark import SparkConf, SparkContext from pyspark.storagelevel import StorageLevel if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: rdd = sc.textFile('file:///home/hadoop/pyspark_project/data/words.txt') rdd1 = rdd.flatMap(lambda x: x.split(" ")) rdd2 = rdd1.map(lambda x: (x,1)) rdd2.cache() # 对 rdd 进行缓存 # rdd2.persist(StorageLevel.MEMORY_AND_DISK_2) rdd3 = rdd2.reduceByKey(lambda a,b: a+b) print(rdd3.collect()) rdd4 = rdd2.groupByKey() rdd5 = rdd4.mapValues(lambda x: sum(x)) print(rdd5.collect()) # rdd2.unpersist() # 释放缓存 time.sleep(100000000) finally: sc.stop()
缓存原理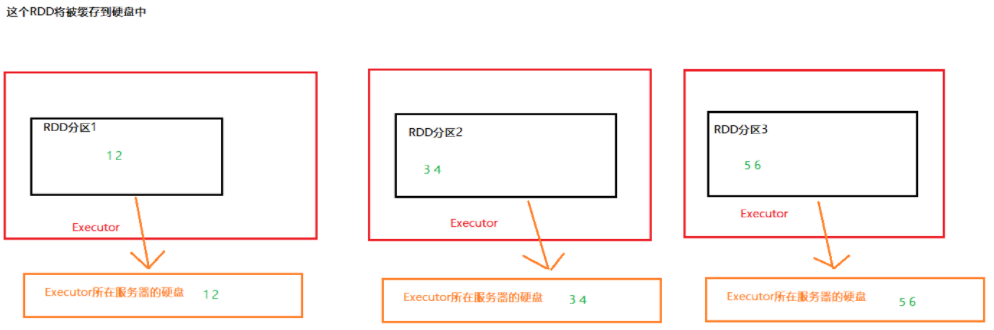
- 缓存是分散存储
- 缓存会保留 RDD 的血缘关系,当缓存丢失后,可以根据 RDD 的血缘关系重新计算 RDD
RDD CheckPoint
CheckPoint 示例
import time from pyspark import SparkConf, SparkContext from pyspark.storagelevel import StorageLevel if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: sc.setCheckpointDir('hdfs://anjhon:8020/output/ckp') # 开启并设置持久化保存路径 rdd = sc.textFile('file:///home/hadoop/pyspark_project/data/words.txt') rdd1 = rdd.flatMap(lambda x: x.split(" ")) rdd2 = rdd1.map(lambda x: (x,1)) rdd2.checkpoint() # 调用 API 保存 rdd3 = rdd2.reduceByKey(lambda a,b: a+b) print(rdd3.collect()) rdd4 = rdd2.groupByKey() rdd5 = rdd4.mapValues(lambda x: sum(x)) print(rdd5.collect()) time.sleep(100000000) finally: sc.stop()
CheckPoint 原理
- CheckPoint仅支持硬盘存储
- 不保留血缘关系
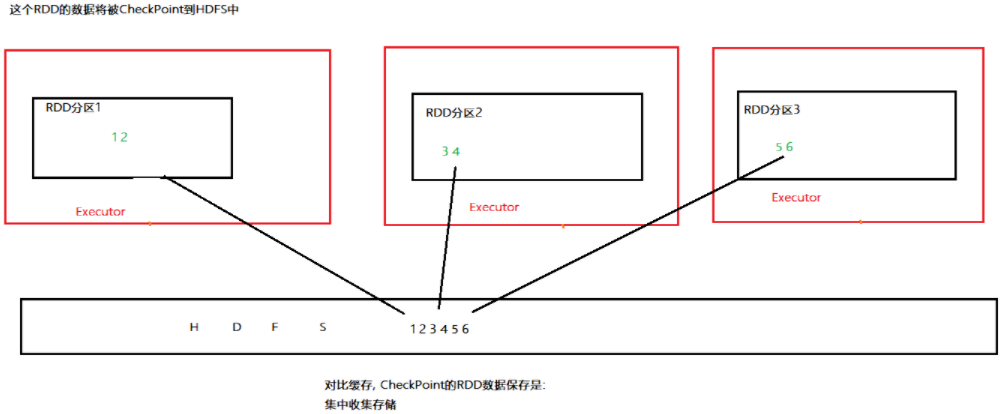
缓存和CheckPoint对比
- CheckPoint不管分区数量多少,风险是一样的,缓存分区越多,风险越高
- CheckPoint支持写入HDFS,缓存不行,HDFS是高可靠存储,CheckPoint被认为是安全的
- CheckPoint不支持内存,缓存可以,缓存如果写内存 性能比CheckPoint要好一些
- CheckPoint因为设计认为是安全的,所以不保留血缘关系,而缓存因为设计上认为不安全,所以保留
RDD实操练习
数据
搜狗实验室提供【用户查询日志(SogouQ)】数据,数据列分别是:搜索时间、搜索用户 id、搜索关键词、URL 返回排名、用户点击顺序、用户点击 URL
00:00:00 2982199073774412 传智播客 8 3 http://www.itcast.cn 00:00:00 07594220010824798 黑马程序员 1 1 http://www.itcast.cn 00:00:00 5228056822071097 传智播客 14 5 http://www.itcast.cn 00:00:00 6140463203615646 博学谷 62 36 http://www.itcast.cn 00:00:00 8561366108033201 IDEA 3 2 http://www.itcast.cn 00:00:00 23908140386148713 传智专修学院 1 2 http://www.itcast.cn
需求
- 对搜索关键词进行分词统计分析
- 用户和关键词组合分析
- 热门搜索时间段分析
代码
main.pyfrom pyspark import SparkConf, SparkContext from pyspark.storagelevel import StorageLevel from tools import jieba_cut_partition, user_content_process # 引入自定义的分词函数 from operator import add if __name__ == "__main__": # 创建Spark配置对象并设置应用名称和运行模式 # conf = SparkConf().setAppName('projiect2').setMaster('local[3]') # 本地模式 conf = SparkConf().setAppName('projiect2') # submit提交到集群,yarn模式 # 设置Python文件在集群中分发 conf.set('spark.submit.pyFiles', '/home/hadoop/pyspark_project/01_RDD/example/tools.py') sc = SparkContext(conf=conf) # 初始化SparkContext # file_rdd = sc.textFile('file:///home/hadoop/pyspark_project/data/SogouQ.txt') # 读取linux 本地文件到RDD中,每行作为一个元素 file_rdd = sc.textFile('hdfs://anjhon:8020/input/SogouQ.txt') # 读取hdfs文件到RDD中,每行作为一个元素 split_rdd = file_rdd.map(lambda line: line.split('\t')) # 将每行文本按制表符分割成一个列表 split_rdd.persist(StorageLevel.DISK_ONLY) # 将分割后的RDD持久化到磁盘 # 需求一:统计搜索词出现的次数 context_rdd = split_rdd.map(lambda x: x[2]) # 提取第三列,即搜索上下文内容 words_rdd = context_rdd.flatMap(jieba_cut_partition) # 对每行内容进行分词 tuple_rdd = words_rdd.map(lambda x: (x, 1)) # 将每个单词转换为键值对,值为1 reduce_rdd = tuple_rdd.reduceByKey(lambda x, y: x + y) # 按键(单词)进行reduce,统计每个单词出现的次数 sort_rdd = reduce_rdd.sortBy(lambda x: x[1], ascending=False, numPartitions=1) # 按值(单词出现的次数)进行排序,降序排列,并将结果保存在一个分区中 print(sort_rdd.take(5)) # [('scala', 2310), ('hadoop', 2268), ('博学谷', 2002), ('传智汇', 1918), ('itheima', 1680)] # 需求二:用户和关键词组合分析 user_content_rdd = split_rdd.map(lambda x: (x[1], x[2])) # 提取第一列和第三列,即用户ID和搜索上下文内容 user_keyWord_rdd = user_content_rdd.flatMap(user_content_process) # 对每行内容进行分词 user_word_reduce_rdd = user_keyWord_rdd.reduceByKey(lambda x, y: x + y) user_word_sort_rdd = user_word_reduce_rdd.sortBy(lambda x: x[1], ascending=False, numPartitions=1) print(user_word_sort_rdd.take(5)) # [('6185822016522959_scala', 2016), ('41641664258866384_博学谷', 1372), ('44801909258572364_hadoop', 1260), ('15984948747597305_传智汇', 1120), ('7044693659960919_数据仓库', 1120)] # 需求三:热门搜索时间段分析 time_rdd = split_rdd.map(lambda x: x[0]) # 提取时间 hour_rdd = time_rdd.map(lambda x: (x.split(':')[0], 1)) # 提取小时 hour_reduce_rdd = hour_rdd.reduceByKey(add) hour_sort_rdd = hour_reduce_rdd.sortBy(lambda x: x[1], ascending=False, numPartitions=1) print(hour_sort_rdd.collect()) # [('20', 3479), ('23', 3087), ('21', 2989), ('22', 2499), ('01', 1365), ('10', 973), ('11', 875), ('05', 798), ('02', 756), ('19', 735), ('12', 644), ('14', 637), ('00', 504), ('16', 497), ('08', 476), ('04', 476), ('03', 385), ('09', 371), ('15', 350), ('06', 294), ('13', 217), ('18', 112), ('17', 77), ('07', 70)]
tools.pyimport jieba def initialize_jieba(): # 添加自定义词语 jieba.add_word('传智播客') jieba.add_word('院校帮') jieba.add_word('博学谷') def jieba_cut_partition(context): # 初始化 jieba 词典 initialize_jieba() # !!!需要在在每个工作节点上重新初始化 jieba 词典以确保正确分词。 return jieba.cut(context) def user_content_process(user_content): user_id = user_content[0] content = user_content[1] words = jieba_cut_partition(content) return [('_'.join([user_id, word]), 1) for word in words]
运行模式
本地模式:直接在编辑器中运行,代码中已经设置好了 Master 为 local
yarn 模式:
spark-submit --py-files tools.py main.py yarn 压榨模式:
- 查看机器的资源:
- cat /proc/cpuinfo 查看 CPU 核心
- free -g 查看内存
- 资源分配
- 先确定 excutor 的数量
- 根据 excutor 的数量来确定内存和核心
- 压榨性能:
spark-submit --py-files tools.py --excutor-memory 2g --excutor-cores 1 --num-excutors 3 main.py
共享变量
在 Spark 中,提供了两种类型的共享变量:累加器 (accumulator) 与广播变量 (broadcast variable):
- 累加器:用来对信息进行聚合,主要用于累计计数等场景;
- 广播变量:主要用于在节点间高效分发大对象。
广播变量
广播变量 (Broadcast Variables) 是一种用于将一个只读变量高效地传递到集群中所有节点的机制。广播变量可以显著提高在分布式计算环境中的数据共享效率,特别是当需要在多个任务中多次使用相同的数据时。
- 减少数据传输:广播变量允许将数据只传输一次,并在每个节点上缓存,从而减少了网络通信的开销。
- 提高性能:在需要多次访问相同数据的情况下,广播变量可以避免重复的数据传输,提高任务的执行效率。
广播变量的原理
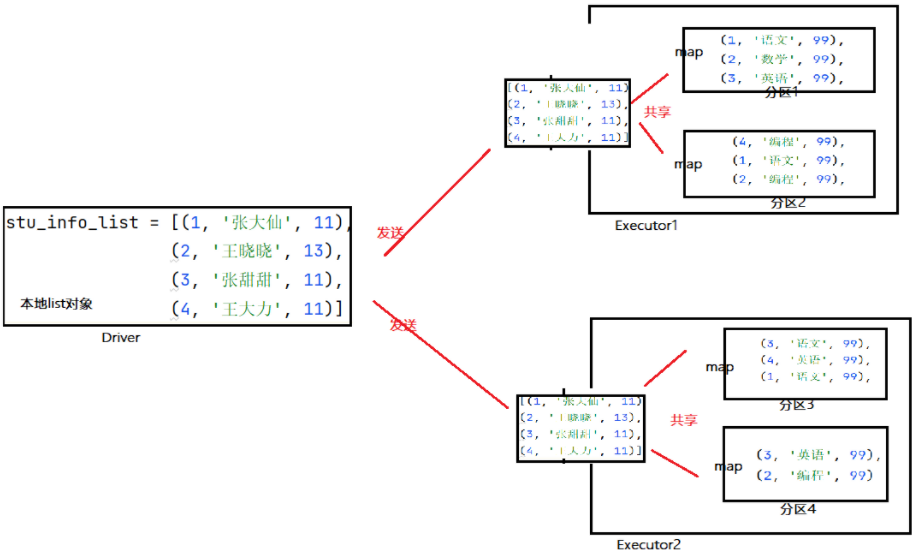
import time from pyspark import SparkConf, SparkContext from pyspark.storagelevel import StorageLevel if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 try: sut_info_list = [(1, 'zhangsan', 13),(2, 'lisi', 14),(3, 'wangwu', 32),(4, 'chenliu', 22),] broadcast = sc.broadcast(sut_info_list) # 将变量封装成广播变量 rdd = sc.parallelize([(1, '语文', 89),(1, '数学', 99),(2, '语文', 89),(3, '数学', 99),(3, '语文', 89),(4, '数学', 99),(4, '语文', 89),(4, '英语', 99),(5, '英语', 99)]) sut_info_list_b = broadcast.value # 从广播变量获取值 map_rdd = rdd.map(lambda x: [(i[1],x[1],x[2]) for i in sut_info_list_b if i[0] == x[0]]) print(map_rdd.collect()) finally: sc.stop()
累加器
累加器(Accumulators) 是一种用于在工作节点上进行累加操作,并将结果传递回驱动程序的一种共享变量。累加器通常用于计数和求和操作,是一种对所有任务执行结果进行聚合的机制。
累加器可以在所有工作节点上执行累加操作,并且只允许添加操作,不允许读取。这避免了在分布式计算环境中可能出现的并发问题。累加器最常见的用途包括:
- 计数操作:例如统计处理了多少条数据。
- 求和操作:例如计算处理的数据的总和。
import time from pyspark import SparkConf, SparkContext from pyspark.storagelevel import StorageLevel if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 count = sc.accumulator(0) def func(x): global count count += 1 print(count) try: rdd = sc.parallelize([1,2,3,4,5,6,7,8,9],2) map_rdd = rdd.map(func) print(map_rdd.collect()) print(count) finally: sc.stop()
注意事项:如果在 rdd 失效之后,再重新构建相关 rdd 的执行链条,则累加器的数值会比预计的多;要在行动算子之前就添加缓存操作。
练习测试
对文件中的数据进行统计
- 正常的单词进行单词计数
- 特殊字符统计出现有多少个
import re from pyspark import SparkConf, SparkContext from pyspark.storagelevel import StorageLevel if __name__ == '__main__': conf = SparkConf().setAppName('test_yarn_submit_from_linux').setMaster('local[3]') # sc = SparkContext(conf=conf) # 直接创建实例 sc = SparkContext.getOrCreate(conf=conf) # 创建或获取现有的实例 chars = ['.', '!', ',', '#','$','%'] broadcast = sc.broadcast(chars) acucmu = sc.accumulator(0) def filter_func(data): global acucmu abnormal_chars = broadcast.value if data in abnormal_chars: acucmu += 1 return False else: return True try: rdd = sc.textFile('file:///home/hadoop/pyspark_project/data/accumulator_broadcast_data.txt') lines_rdd = rdd.filter(lambda line: line.strip()) map_rdd = lines_rdd.map(lambda line: line.strip()) words_rdd = map_rdd.flatMap(lambda x: re.split("\s+", x)) normal_words_rdd = words_rdd.filter(filter_func) result_rdd = normal_words_rdd.map(lambda x: (x, 1)).reduceByKey(lambda a, b: a + b) print(result_rdd.collect()) print(acucmu) finally: sc.stop()
内核调度
DAG
DAG(Directed Acyclic Graph,直接有向无环图)是任务调度和执行的核心概念之一。DAG 描述了 Spark 作业(job)的各个阶段以及各个阶段之间的依赖关系,是 Spark 进行任务调度、优化和执行的基础。
Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度。Spark 的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage, 将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,可以合理规划资源利用,做到尽可能用最少的 资源高效地完成任务计算。
一个 action算子 会产生一个 job,每一个 job 都回产生自己的 DAG 图。
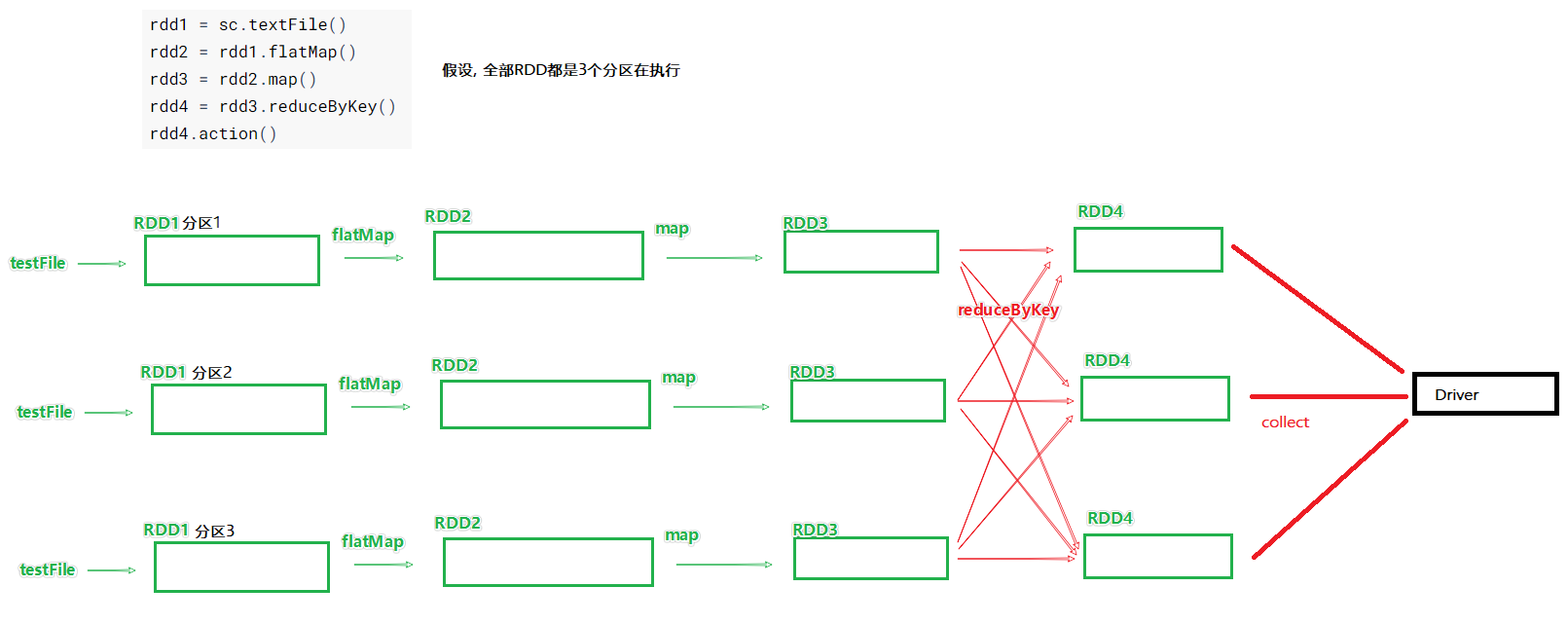
宽窄依赖
在SparkRDD前后之间的关系,分为:
- 窄依赖:父RDD的一个分区,全部 将数据发给子RDD的一个分区
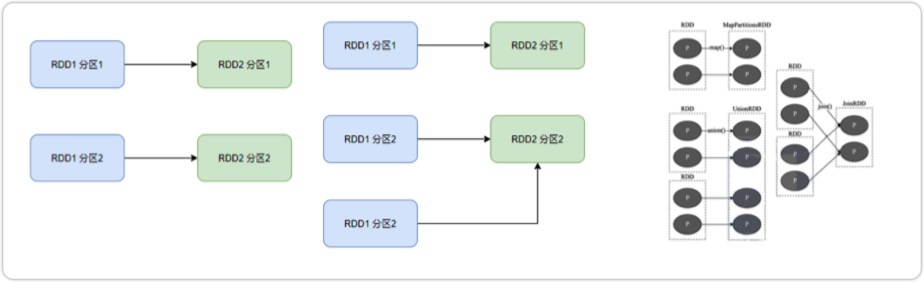
- 宽依赖:父RDD的一个分区,将数据发给子RDD的多个分区 宽依赖还有一个别名:shuffle
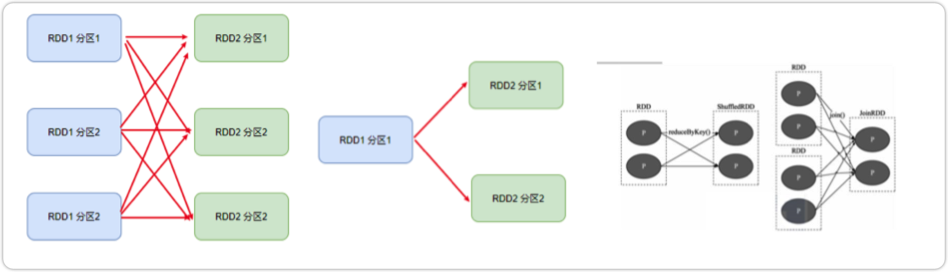
对于Spark来说,会根据宽依赖,划分不同的DAG阶段;划分依据:从后向前,遇到 宽依赖 就划分出一个阶段,称之为stage;所以在stage的内部,一定都是窄依赖
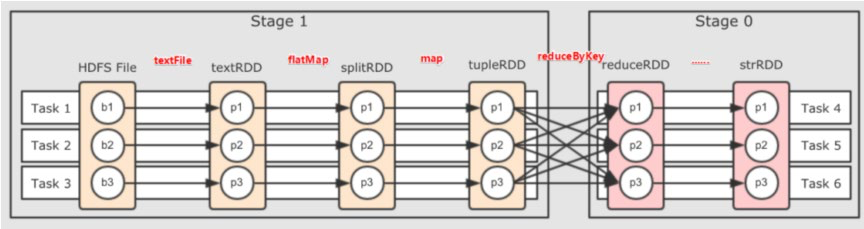
内存迭代计算
窄依赖操作可以在内存中高效并行执行,因为每个任务只需访问一个父分区的数据。这种操作不需要进行 shuffle,因此能充分利用内存的优势,减少 I/O 开销和网络传输。
宽依赖操作需要 shuffle 数据,这通常涉及到大量的数据重新分区和网络传输。这种操作虽然也可以在内存中执行,但由于需要等待所有分区的数据,这些操作的性能往往受限于网络带宽和 shuffle 的开销。
所以在同一个阶段内的的不同分区是并行计算的,只有在遭遇宽依赖时,会产生 I/O 开销和网络传输。因此一般不建议去修改已经确定好的 rdd 分区数(有修改分区数的算子),这样会增加遭遇宽依赖的次数
面试题1:Spark是怎么做内存计算的?DAG的作用?Stage阶段划分的作用?
Spark会产生DAG图
DAG图会基于分区和宽窄依赖关系划分阶段
一个阶段的内部都是 窄依赖,窄依赖内,如果形成前后1:1的分区对应关系,就可以产生许多内存迭代计算的管道
这些内存迭代计算的管道,就是一个个具体的执行Task
—个Task是一个具体的线程,任务跑在一个线程内,就是走内存计算了.
面试题2:Spark为什么比MapReduce快
Spark的算子丰富,MapReduce算子匮三(Map和Reduce), MapReduce这个编程模型,很难在一套MR中处理复杂的任务;很多的复杂任务,是需要写多个MapReduce进行串联.多个MR串联通过磁盘交互数据
Spark可以执行内存迭代,算子之间形成DAG 基于依赖划分阶段后,在阶段内形成内存迭代管道.但是MapReduce的Map和Reduce之间的交互依旧是通过硬盘来交互的.
总结:
编程模型上Spark占优(算子够多)
算子交互上,和计算上可以尽量多的内存计算而非磁盘迭代
Spark 并行度
Spark的并行:在同一时间内,有多少个task在同时运行(先有了并行度才创建出了对等数量的分区)
- 全局并行度(优先级从高到低)
- 代码中
conf = SaprkConf() conf.set("spark.default.parallelism", "100")
spark-submit --conf "spark.default.parallelism=100"
conf/spark-defaults.conf)spark.default.parallelism 100
- RDD 并行度(不推荐)
- repartition算子
- coalesce算子
- partitionBy算子
并行度的合适区间:设置为CPU总核心的2~10倍;比如集群可用cPU核心是100个,我们建议并行度是200~1000;excuter 建议和节点数量一致(一个节点内就一个 excutor)
为什么要设置最少2倍?
CPU的一个核心同一时间只能干一件事情.
所以,在100个核心的情况下,设置100个并行,就能让CPU 100%出力.
这种设置下,如果task的压力不均衡,某个task先执行完了,就导致某个CPU核心、空闲
所以,我们将Task(并行)分配的数量变多,比如800个并行,同一时间只有100个在运行,700个在等待.
但是可以确保,某个task运行完了.后续有task补上,不让cpu闲下来,最大程度利用集群的资源.
Spark Shuffle
Spark在DAG调度阶段会将一个Job划分为多个Stage,上游Stage做map工作,下游Stage做reduce工作,其本质上 还是MapReduce计算框架。Shuffle是连接map和reduce之间的桥梁,它将map的输出对应到reduce输入中,涉及 到序列化反序列化、跨节点网络IO以及磁盘读写IO等。Spark的Shuffle分为Write和Read两个阶段,分属于两个不同的Stage,前者是Parent Stage的最后一步,后者是 Child Stage的第一步。
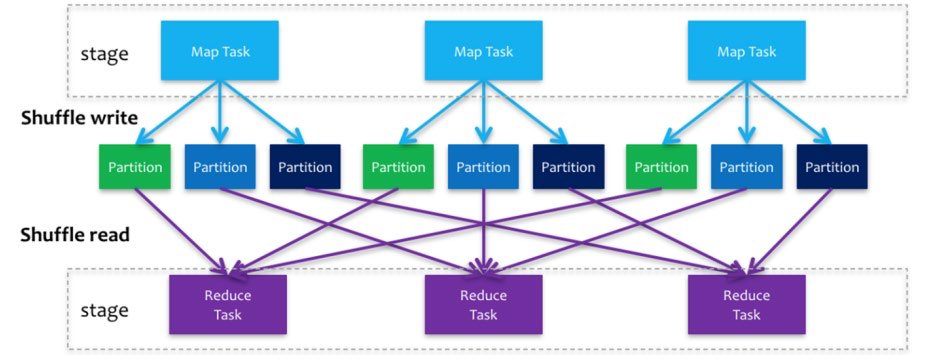
Shuffle阶段划分: shuffle write:mapper阶段,上一个stage得到最后的结果写出 shuffle read :reduce阶段,下一个stage拉取上一个stage进行合并
Spark任务调度
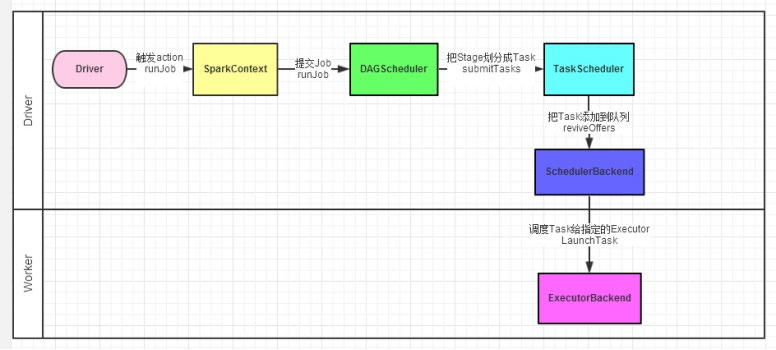
如图,Spark程序的调度流程如图:
- Driver被构建出来
- 构建SparkContext(执行环境入口对象)
- 基于DAG Scheduler(DAG调度器) 构建逻辑Task分配
- 基于TaskScheduler (Task调度器) 将逻辑Task分配到各个Executor上干活,并监控它们.
- Worker(Executor),被TaskScheduler管理监控,听从它们的指令干活,并定期汇报进度.
DAG调度器:将逻辑的DAG图进行处理,最终得到逻辑上的 Task 划分(规划任务)
Task调度器:基于DAG Scheduler的产出,来规划 这些逻辑 的task,应该在哪些物理 的executor上运行,以及监控管理它们的运行
Spark 层级关系

层级关系梳理:
一个Spark环境可以运行多个Application
一个代码运行起来,会成为一个Application
Application 内部可以有多个Job
每个Job由一个Action产生,并且每个Job有自己的DAG执行图
一个Job的DAG图 会基于宽窄依赖划分成不同的阶段
不同阶段 内 基于分区数量,形成多个并行的内存迭代管道
每一个内存迭代管道形成一个Task( DAG 调度器划分将Job内划分出具体的task任务,一个Job被划分出来的task 在逻辑上称之为这个job的 taskset)