type
Post
status
Published
summary
Apache Hive 是一个用于大数据处理的开源数据仓库工具,最初由Facebook开发并于2010年贡献给Apache软件基金会。它设计的主要目的是使数据分析人员能够通过类SQL语言(即HiveQL)在Hadoop分布式文件系统 (HDFS) 上执行大规模数据查询和分析。Hive 是一个构建在 Hadoop 之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类 SQL 查询功能,用于查询的 SQL 语句会被转化为 MapReduce 作业,然后提交到 Hadoop 上运行。
slug
bigdata-hive
date
Jul 16, 2024
tags
大数据
Hive
category
大数据
password
icon
URL
Property
Jul 16, 2024 07:09 AM
Hive 概述
Apache Hive 是一个用于大数据处理的开源数据仓库工具,最初由Facebook开发并于2010年贡献给Apache软件基金会。它设计的主要目的是使数据分析人员能够通过类SQL语言(即HiveQL)在Hadoop分布式文件系统 (HDFS) 上执行大规模数据查询和分析。Hive 是一个构建在 Hadoop 之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类 SQL 查询功能,用于查询的 SQL 语句会被转化为 MapReduce 作业,然后提交到 Hadoop 上运行。
特点:
- 简单、容易上手 (提供了类似 sql 的查询语言 hql),使得精通 sql 但是不了解 Java 编程的人也能很好地进行大数据分析;
- 灵活性高,可以自定义用户函数 (UDF) 和存储格式;
- 为超大的数据集设计的计算和存储能力,集群扩展容易;
- 统一的元数据管理,可与 presto/impala/sparksql 等共享数据;
- 执行延迟高,不适合做数据的实时处理,但适合做海量数据的离线处理。
- 不支持行级更新:Hive更适合读密集型操作,不支持高效的行级更新。
Hive 基础架构
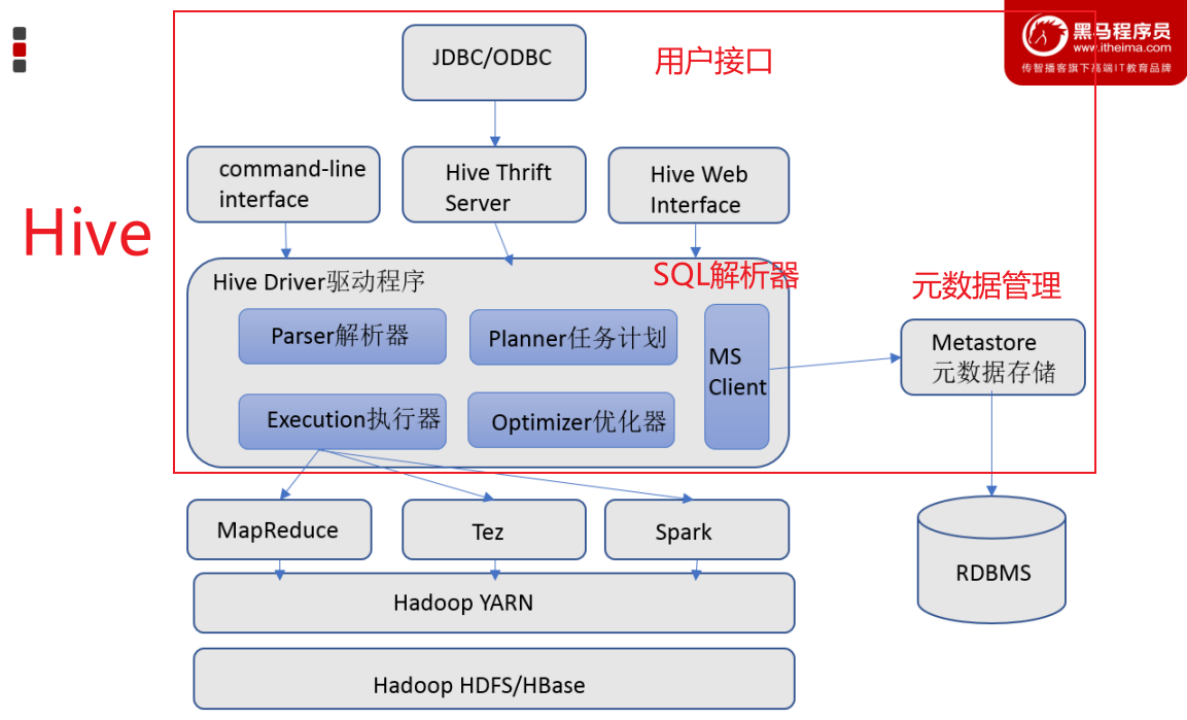
- 元数据存储:Hive提供了 Metastore 服务进程提供元数据管理功能
- 在 Hive 中,表名、表结构、字段名、字段类型、表的分隔符、表分区、表属性、表的数据所在目录等统一被称为元数据。
- 通常是存储在关系数据库如 mysql/derby中。
- Driver驱动程序,包括语法解析器、计划编译器、优化器、执行器
- 完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有执行引擎调用执行。这部分内容不是具体的服务进程,而是封装在Hive所依赖的Jar文件即Java代码中。
- 用户接口:可以用 command-line shell 和 thrift/jdbc 两种方式来操作数据。
- 包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。
Hive 在执行一条 HQL 的时候,会经过以下步骤:
- 解析 (Parsing)
- 词法分析 (Lexical Analysis):将查询字符串分割成单词和符号(标记)。
- 语法分析 (Syntax Analysis):将标记组织成结构化的语法树。
Hive 解析器首先将 HQL 查询转换为抽象语法树 (AST)。这个过程包括词法分析和语法分析,以确保查询语法正确。
- 语义分析 (Semantic Analysis)
在这个阶段,Hive 验证查询的语义,检查表和列是否存在,并确保查询是合法的。语义分析器遍历 AST 并进行语义检查。
- 优化 (Optimization)
- 选择投影和过滤推入 (Predicate Pushdown):尽可能早地在数据流中应用过滤条件。
- 连接优化 (Join Optimization):选择最有效的连接顺序和方法。
- 子查询优化 (Subquery Optimization):优化嵌套查询。
Hive 优化器通过重写查询来优化查询计划,以提高查询性能。优化器执行的步骤包括:
- 物理计划生成 (Physical Plan Generation)
优化后的查询计划被转换为一个 DAG(有向无环图),表示 MapReduce、Tez 或 Spark 任务。这个 DAG 是物理执行计划,它描述了如何在底层分布式计算框架上执行查询。
- 执行 (Execution)
- 任务生成 (Task Generation):将物理计划分解为一个或多个任务,每个任务对应一个 MapReduce、Tez 或 Spark 作业。
- 任务提交 (Task Submission):将任务提交给 Hadoop YARN(Yet Another Resource Negotiator)集群进行调度和执行。
- 任务执行 (Task Execution):实际执行 MapReduce、Tez 或 Spark 作业。每个作业处理数据块并产生中间结果。
Hive 通过底层执行引擎(如 MapReduce、Tez 或 Spark)来执行物理计划。执行过程包括以下步骤:
- 合并结果 (Result Merging)
如果查询产生多个任务的中间结果,Hive 将合并这些结果以生成最终的输出。例如,在连接操作中,多个任务可能会产生部分结果,最后一步将合并这些部分结果以生成最终输出。
- 返回结果 (Result Return)
最终的查询结果被返回给用户或存储在指定的目标表或文件中。
Hive 部署
Hive是单机工具,只需要部署在一台服务器即可。Hive虽然是单机的,但是它可以提交分布式运行的MapReduce程序运行。
安装 MySQL8.0
- 如果已经安装过MySQL5.7版本,需要卸载仓库信息
# 卸载MySQL5.7版本 apt remove -y mysql-client=5.7* mysql-community-server=5.7* # 卸载5.7的仓库信息 dpkg -l | grep mysql | awk '{print $2}' | xargs dpkg -P
- 更新apt仓库信息
apt update
- 安装mysql
apt install -y mysql-server
- 启动MySQL
/etc/init.d/mysql start # 启动 /etc/init.d/mysql stop # 停止 /etc/init.d/mysql status # 查看状态 systemctl start mysql.service # 启动 systemctl status mysql.service # 查看状态 systemctl stop mysql.service # 停止
- 首次登陆MySQL设置密码
# 直接执行:mysql mysql
- 设置密码
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password';
- 退出MySQL控制台
exit
- 对MySQL进行初始化
- 输入密码:
- 是否开启密码验证插件,如果需要增强密码安全性,输入
y并回车,不需要直接回车(课程中选择直接回车) - 是否更改root密码,需要输入
y回车,不需要直接回车(课程不更改) - 是否移除匿名用户,移除输入
y回车,不移除直接回车(课程选择移除) - 是否进制root用户远程登录,禁止输入
y回车,不禁止直接回车(课程选择不禁止) - 是否移除自带的测试数据库,移除输入
y回车,不移除直接回车(课程选择不移除) - 是否刷新权限,刷新输入
y回车,不刷新直接回车(课程选择刷新)
# 执行如下命令,此命令是MySQL安装后自带的配置程序 mysql_secure_installation # 可以通过which命令查看到这个自带程序所在的位置 which mysql_secure_installation # /usr/bin/mysql_secure_installation
- 重新登陆MySQL(用更改后的密码)
mysql -u root -p
安装Hive
前置工作
Hive的运行依赖于Hadoop(HDFS、MapReduce、YARN都依赖),同时涉及到HDFS文件系统的访问,所以需要配置Hadoop的代理用户,即设置hadoop用户允许代理(模拟)其它用户
配置如下内容在Hadoop的core-site.xml中,并分发到其它节点,且重启HDFS集群
<property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property>
下载安装
- 切换到hadoop用户:
su - hadoop
- 解压到node1服务器的:/export/server/内:
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /export/server/
- 设置软连接:
ln -s /export/server/apache-hive-3.1.3-bin /export/server/hive
- 下载MySQL驱动包:
- 将下载好的驱动jar包,放入:Hive安装文件夹的lib目录内
配置修改
- 在Hive的conf目录内,将模板重命名:
mv hive-env.sh.template hive-env.sh
- 在hive-env.sh文件内填入以下环境变量内容:
export HADOOP_HOME=/export/server/hadoop export HIVE_CONF_DIR=/export/server/hive/conf export HIVE_AUX_JARS_PATH=/export/server/hive/lib
- 新建hive-site.xml文件:vim hive-site.xml,填入内容:
<configuration> <!-- 配置项名称:javax.jdo.option.ConnectionURL 含义:指定连接到元存储的JDBC URL。元存储用于存储Hive的元数据。 参数: - jdbc:mysql://anjhon:3306/hive:MySQL数据库的连接URL。 - createDatabaseIfNotExist=true:如果数据库不存在,自动创建数据库。 - useSSL=false:禁用SSL连接。 - useUnicode=true:启用Unicode支持。 - characterEncoding=UTF-8:设置字符编码为UTF-8。 - allowPublicKeyRetrieval=true:允许检索公钥,以便支持SHA-2密码插件。 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://anjhon:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true</value> </property> <!-- 配置项名称:javax.jdo.option.ConnectionDriverName 含义:指定用于连接元存储的JDBC驱动程序。 参数:com.mysql.cj.jdbc.Driver(MySQL JDBC驱动程序类) --> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> </property> <!-- 配置项名称:javax.jdo.option.ConnectionUserName 含义:连接元存储时使用的用户名。 参数:root(数据库用户) --> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <!-- 配置项名称:javax.jdo.option.ConnectionPassword 含义:连接元存储时使用的密码。 参数:32924ayd(数据库用户密码) --> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>32924ayd</value> </property> <!-- 配置项名称:hive.server2.thrift.bind.host 含义:指定HiveServer2绑定的主机名。 参数:anjhon(绑定主机名) --> <property> <name>hive.server2.thrift.bind.host</name> <value>anjhon</value> </property> <!-- 配置项名称:hive.metastore.uris 含义:指定Metastore的Thrift服务URI。 参数:thrift://anjhon:9083(Thrift服务的URI) --> <property> <name>hive.metastore.uris</name> <value>thrift://anjhon:9083</value> </property> <!-- 配置项名称:hive.metastore.event.db.notification.api.auth 含义:是否启用事件数据库通知API的身份验证。 参数:false(禁用身份验证) --> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> <!-- 配置项名称:hive.server2.enable.doAs 含义:是否启用用户代理功能。 参数:true(启用用户代理功能) --> <property> <name>hive.server2.enable.doAs</name> <value>true</value> </property> <!-- 配置项名称:hive.server2.proxy.user 含义:指定用于代理的用户。 参数:hadoop(代理用户) --> <property> <name>hive.server2.proxy.user</name> <value>hadoop</value> </property> <!-- 配置项名称:hive.server2.thrift.port 含义:指定HiveServer2的Thrift服务端口。 参数:10000(Thrift服务端口) --> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> </configuration>
初始化原数据
Hive的配置已经完成,现在在启动Hive前,需要先初始化Hive所需的元数据库。
在MySQL中新建数据库:CREATE DATABASE hive CHARSET UTF8;
执行元数据库初始化命令:
cd /export/server/hive
bin/schematool -initSchema -dbType mysql -verbos
初始化成功后,会在MySQL的hive库中新建74张元数据管理的表。
遇到问题
- 问题一:
- 执行:
./schematool -initSchema -dbType mysql -verbos - 提示:Cannot find hadoop installation: $HADOOP_HOME or $HADOOP_PREFIX must be set or hadoop must be in the path
- 解决:/export/server/hive/conf/hive-env.sh 文件中的 HADOOP_HOME 路径写错了
- 问题二:
- 执行:
./schematool -initSchema -dbType mysql -verbos - 提示:
SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/export/server/apache-hive-3.1.3-bin/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/export/server/hadoop-3.3.6/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] Metastore connection URL: jdbc:mysql://anjhon:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8 Metastore Connection Driver : com.mysql.jdbc.Driver Metastore connection User: root org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version. Underlying cause: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException : Communications link failure The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server. SQL Error code: 0 Use --verbose for detailed stacktrace. *** schemaTool failed ***
- mysql 的配置文件中被设置只允许本地连接
解决:
vim /etc/mysql/mysql.conf.d/mysqld.cnf,修改如下bind-address = 127.0.0.1 mysqlx-bind-address = 127.0.0.1 修改为: bind-address = 0.0.0.0 mysqlx-bind-address = 0.0.0.0
解决:下载新的驱动程序,将其放在 Hive 的
lib 目录下,替换掉以前的(因为我的 MySQL 是 8.0 版本的,而驱动是 5.1 版本的);注意:只需要压缩包中的mysql-connector-java-8.0.26.jar文件,放入 hive 的 lib 目录中,删除以前的即可。wget https://dev.mysql.com/get/Downloads/Connector-J/mysql-connector-java-8.0.26.tar.gz tar -zxvf mysql-connector-java-8.0.26.tar.gz cp mysql-connector-java-8.0.26/mysql-connector-java-8.0.26.jar /path/to/apache-hive/lib/
- 问题三:正常启动元数据管理服务器,但是服务器会自动结束进程; hiveserver2 可以正常启动,但是通过:
netstat -anp | grep 10000查看服务没有服务在监听 10000 端口; - 原因:从日志中可以看出,导致问题的原因是与MySQL数据库的连接问题,具体错误是“Public Key Retrieval is not allowed”(不允许检索公钥)。这是由于MySQL 8.0中的默认身份验证插件(Caching SHA-2)导致的。HikariCP连接池无法初始化,因为MySQL服务器不允许公钥检索。
- 解决:
日志:日志主要看MetaException和Caused by: ,在大量的日志中,有提示:Caused by: com.mysql.cj.exceptions.UnableToConnectException: Public Key Retrieval is not allowed
nohup: ignoring input SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/export/server/apache-hive-3.1.3-bin/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/export/server/hadoop-3.3.6/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] 2024-07-17 14:06:15: Starting Hive Metastore Server SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/export/server/apache-hive-3.1.3-bin/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/export/server/hadoop-3.3.6/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory] MetaException(message:Error creating transactional connection factory) at org.apache.hadoop.hive.metastore.RetryingHMSHandler.<init>(RetryingHMSHandler.java:84) at org.apache.hadoop.hive.metastore.RetryingHMSHandler.getProxy(RetryingHMSHandler.java:93) at org.apache.hadoop.hive.metastore.HiveMetaStore.newRetryingHMSHandler(HiveMetaStore.java:8672) at org.apache.hadoop.hive.metastore.HiveMetaStore.newRetryingHMSHandler(HiveMetaStore.java:8667) at org.apache.hadoop.hive.metastore.HiveMetaStore.startMetaStore(HiveMetaStore.java:8937) at org.apache.hadoop.hive.metastore.HiveMetaStore.main(HiveMetaStore.java:8854) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.RunJar.run(RunJar.java:328) at org.apache.hadoop.util.RunJar.main(RunJar.java:241) Caused by: MetaException(message:Error creating transactional connection factory) at org.apache.hadoop.hive.metastore.RetryingHMSHandler.invokeInternal(RetryingHMSHandler.java:208) at org.apache.hadoop.hive.metastore.RetryingHMSHandler.invoke(RetryingHMSHandler.java:108) at org.apache.hadoop.hive.metastore.RetryingHMSHandler.<init>(RetryingHMSHandler.java:80) ... 11 more at org.datanucleus.api.jdo.NucleusJDOHelper.getJDOExceptionForNucleusException(NucleusJDOHelper.java:671) at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.freezeConfiguration(JDOPersistenceManagerFactory.java:830) at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.createPersistenceManagerFactory(JDOPersistenceManagerFactory.java:334) at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.getPersistenceManagerFactory(JDOPersistenceManagerFactory.java:213) at sun.reflect.GeneratedMethodAccessor3.invoke(Unknown Source) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at javax.jdo.JDOHelper$16.run(JDOHelper.java:1965) at java.security.AccessController.doPrivileged(Native Method) at javax.jdo.JDOHelper.invoke(JDOHelper.java:1960) at javax.jdo.JDOHelper.invokeGetPersistenceManagerFactoryOnImplementation(JDOHelper.java:1166) at javax.jdo.JDOHelper.getPersistenceManagerFactory(JDOHelper.java:808) at javax.jdo.JDOHelper.getPersistenceManagerFactory(JDOHelper.java:701) at org.apache.hadoop.hive.metastore.ObjectStore.getPMF(ObjectStore.java:651) at org.apache.hadoop.hive.metastore.ObjectStore.getPersistenceManager(ObjectStore.java:694) at org.apache.hadoop.hive.metastore.ObjectStore.initializeHelper(ObjectStore.java:484) at org.apache.hadoop.hive.metastore.ObjectStore.initialize(ObjectStore.java:421) at org.apache.hadoop.hive.metastore.ObjectStore.setConf(ObjectStore.java:376) at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:79) at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:140) at org.apache.hadoop.hive.metastore.RawStoreProxy.<init>(RawStoreProxy.java:59) at org.apache.hadoop.hive.metastore.RawStoreProxy.getProxy(RawStoreProxy.java:67) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.newRawStoreForConf(HiveMetaStore.java:720) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.getMSForConf(HiveMetaStore.java:698) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.getMS(HiveMetaStore.java:692) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.createDefaultDB(HiveMetaStore.java:775) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.init(HiveMetaStore.java:540) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.hive.metastore.RetryingHMSHandler.invokeInternal(RetryingHMSHandler.java:147) ... 13 more Caused by: java.lang.reflect.InvocationTargetException at sun.reflect.GeneratedConstructorAccessor75.newInstance(Unknown Source) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.datanucleus.plugin.NonManagedPluginRegistry.createExecutableExtension(NonManagedPluginRegistry.java:606) at org.datanucleus.plugin.PluginManager.createExecutableExtension(PluginManager.java:330) at org.datanucleus.store.AbstractStoreManager.registerConnectionFactory(AbstractStoreManager.java:203) at org.datanucleus.store.AbstractStoreManager.<init>(AbstractStoreManager.java:162) at org.datanucleus.store.rdbms.RDBMSStoreManager.<init>(RDBMSStoreManager.java:285) at sun.reflect.GeneratedConstructorAccessor74.newInstance(Unknown Source) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.datanucleus.plugin.NonManagedPluginRegistry.createExecutableExtension(NonManagedPluginRegistry.java:606) at org.datanucleus.plugin.PluginManager.createExecutableExtension(PluginManager.java:301) at org.datanucleus.NucleusContextHelper.createStoreManagerForProperties(NucleusContextHelper.java:133) at org.datanucleus.PersistenceNucleusContextImpl.initialise(PersistenceNucleusContextImpl.java:422) at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.freezeConfiguration(JDOPersistenceManagerFactory.java:817) ... 43 more Caused by: org.datanucleus.exceptions.NucleusException: Attempt to invoke the "HikariCP" plugin to create a ConnectionPool gave an error : Failed to initialize pool: Public Key Retrieval is not allowed at org.datanucleus.store.rdbms.ConnectionFactoryImpl.generateDataSources(ConnectionFactoryImpl.java:232) at org.datanucleus.store.rdbms.ConnectionFactoryImpl.initialiseDataSources(ConnectionFactoryImpl.java:117) at org.datanucleus.store.rdbms.ConnectionFactoryImpl.<init>(ConnectionFactoryImpl.java:82) ... 59 more Caused by: com.zaxxer.hikari.pool.HikariPool$PoolInitializationException: Failed to initialize pool: Public Key Retrieval is not allowed at com.zaxxer.hikari.pool.HikariPool.throwPoolInitializationException(HikariPool.java:544) at com.zaxxer.hikari.pool.HikariPool.checkFailFast(HikariPool.java:536) at com.zaxxer.hikari.pool.HikariPool.<init>(HikariPool.java:112) at com.zaxxer.hikari.HikariDataSource.<init>(HikariDataSource.java:72) at org.datanucleus.store.rdbms.connectionpool.HikariCPConnectionPoolFactory.createConnectionPool(HikariCPConnectionPoolFactory.java:176) at org.datanucleus.store.rdbms.ConnectionFactoryImpl.generateDataSources(ConnectionFactoryImpl.java:213) ... 61 more at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122) at com.mysql.cj.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:828) at com.mysql.cj.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:448) at com.mysql.cj.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:241) at com.mysql.cj.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:198) at com.zaxxer.hikari.util.DriverDataSource.getConnection(DriverDataSource.java:95) at com.zaxxer.hikari.util.DriverDataSource.getConnection(DriverDataSource.java:101) at com.zaxxer.hikari.pool.PoolBase.newConnection(PoolBase.java:356) at com.zaxxer.hikari.pool.PoolBase.newPoolEntry(PoolBase.java:199) at com.zaxxer.hikari.pool.HikariPool.createPoolEntry(HikariPool.java:444) at com.zaxxer.hikari.pool.HikariPool.checkFailFast(HikariPool.java:515) ... 65 more Caused by: com.mysql.cj.exceptions.UnableToConnectException: Public Key Retrieval is not allowed at sun.reflect.GeneratedConstructorAccessor79.newInstance(Unknown Source) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at com.mysql.cj.exceptions.ExceptionFactory.createException(ExceptionFactory.java:61) at com.mysql.cj.exceptions.ExceptionFactory.createException(ExceptionFactory.java:85) at com.mysql.cj.protocol.a.authentication.CachingSha2PasswordPlugin.nextAuthenticationStep(CachingSha2PasswordPlugin.java:130) at com.mysql.cj.protocol.a.authentication.CachingSha2PasswordPlugin.nextAuthenticationStep(CachingSha2PasswordPlugin.java:49) at com.mysql.cj.protocol.a.NativeAuthenticationProvider.proceedHandshakeWithPluggableAuthentication(NativeAuthenticationProvider.java:434) at com.mysql.cj.protocol.a.NativeAuthenticationProvider.connect(NativeAuthenticationProvider.java:209) at com.mysql.cj.protocol.a.NativeProtocol.connect(NativeProtocol.java:1352) at com.mysql.cj.NativeSession.connect(NativeSession.java:132) at com.mysql.cj.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:948) at com.mysql.cj.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:818) ... 74 more NestedThrowables: java.lang.reflect.InvocationTargetException at org.datanucleus.api.jdo.NucleusJDOHelper.getJDOExceptionForNucleusException(NucleusJDOHelper.java:671) at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.freezeConfiguration(JDOPersistenceManagerFactory.java:830) at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.createPersistenceManagerFactory(JDOPersistenceManagerFactory.java:334) at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.getPersistenceManagerFactory(JDOPersistenceManagerFactory.java:213) at sun.reflect.GeneratedMethodAccessor3.invoke(Unknown Source) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at javax.jdo.JDOHelper$16.run(JDOHelper.java:1965) at java.security.AccessController.doPrivileged(Native Method) at javax.jdo.JDOHelper.invoke(JDOHelper.java:1960) at javax.jdo.JDOHelper.invokeGetPersistenceManagerFactoryOnImplementation(JDOHelper.java:1166) at javax.jdo.JDOHelper.getPersistenceManagerFactory(JDOHelper.java:808) at javax.jdo.JDOHelper.getPersistenceManagerFactory(JDOHelper.java:701) at org.apache.hadoop.hive.metastore.ObjectStore.getPMF(ObjectStore.java:651) at org.apache.hadoop.hive.metastore.ObjectStore.getPersistenceManager(ObjectStore.java:694) at org.apache.hadoop.hive.metastore.ObjectStore.initializeHelper(ObjectStore.java:484) at org.apache.hadoop.hive.metastore.ObjectStore.initialize(ObjectStore.java:421) at org.apache.hadoop.hive.metastore.ObjectStore.setConf(ObjectStore.java:376) at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:79) at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:140) at org.apache.hadoop.hive.metastore.RawStoreProxy.<init>(RawStoreProxy.java:59) at org.apache.hadoop.hive.metastore.RawStoreProxy.getProxy(RawStoreProxy.java:67) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.newRawStoreForConf(HiveMetaStore.java:720) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.getMSForConf(HiveMetaStore.java:698) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.getMS(HiveMetaStore.java:692) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.createDefaultDB(HiveMetaStore.java:775) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.init(HiveMetaStore.java:540) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.hive.metastore.RetryingHMSHandler.invokeInternal(RetryingHMSHandler.java:147) ... 13 more at org.datanucleus.plugin.NonManagedPluginRegistry.createExecutableExtension(NonManagedPluginRegistry.java:606) at org.datanucleus.plugin.PluginManager.createExecutableExtension(PluginManager.java:301) at org.datanucleus.NucleusContextHelper.createStoreManagerForProperties(NucleusContextHelper.java:133) at org.datanucleus.PersistenceNucleusContextImpl.initialise(PersistenceNucleusContextImpl.java:422) at org.datanucleus.api.jdo.JDOPersistenceManagerFactory.freezeConfiguration(JDOPersistenceManagerFactory.java:817) ... 43 more Caused by: org.datanucleus.exceptions.NucleusException: Attempt to invoke the "HikariCP" plugin to create a ConnectionPool gave an error : Failed to initialize pool: Public Key Retrieval is not allowed at org.datanucleus.store.rdbms.ConnectionFactoryImpl.generateDataSources(ConnectionFactoryImpl.java:232) at org.datanucleus.store.rdbms.ConnectionFactoryImpl.initialiseDataSources(ConnectionFactoryImpl.java:117) at org.datanucleus.store.rdbms.ConnectionFactoryImpl.<init>(ConnectionFactoryImpl.java:82) ... 59 more Caused by: com.zaxxer.hikari.pool.HikariPool$PoolInitializationException: Failed to initialize pool: Public Key Retrieval is not allowed at com.zaxxer.hikari.pool.HikariPool.throwPoolInitializationException(HikariPool.java:544) at com.zaxxer.hikari.pool.HikariPool.checkFailFast(HikariPool.java:536) at com.zaxxer.hikari.pool.HikariPool.<init>(HikariPool.java:112) at com.zaxxer.hikari.HikariDataSource.<init>(HikariDataSource.java:72) at org.datanucleus.store.rdbms.connectionpool.HikariCPConnectionPoolFactory.createConnectionPool(HikariCPConnectionPoolFactory.java:176) at org.datanucleus.store.rdbms.ConnectionFactoryImpl.generateDataSources(ConnectionFactoryImpl.java:213) ... 61 more Caused by: java.sql.SQLNonTransientConnectionException: Public Key Retrieval is not allowed at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:110) at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122) at com.mysql.cj.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:828) at com.mysql.cj.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:448) at com.mysql.cj.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:241) at com.mysql.cj.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:198) at com.zaxxer.hikari.util.DriverDataSource.getConnection(DriverDataSource.java:95) at com.zaxxer.hikari.util.DriverDataSource.getConnection(DriverDataSource.java:101) at com.zaxxer.hikari.pool.PoolBase.newConnection(PoolBase.java:356) at com.zaxxer.hikari.pool.PoolBase.newPoolEntry(PoolBase.java:199) at com.zaxxer.hikari.pool.HikariPool.createPoolEntry(HikariPool.java:444) at com.zaxxer.hikari.pool.HikariPool.checkFailFast(HikariPool.java:515) ... 65 more Caused by: com.mysql.cj.exceptions.UnableToConnectException: Public Key Retrieval is not allowed at sun.reflect.GeneratedConstructorAccessor79.newInstance(Unknown Source) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at com.mysql.cj.exceptions.ExceptionFactory.createException(ExceptionFactory.java:61) at com.mysql.cj.exceptions.ExceptionFactory.createException(ExceptionFactory.java:85) at com.mysql.cj.protocol.a.authentication.CachingSha2PasswordPlugin.nextAuthenticationStep(CachingSha2PasswordPlugin.java:130) at com.mysql.cj.protocol.a.authentication.CachingSha2PasswordPlugin.nextAuthenticationStep(CachingSha2PasswordPlugin.java:49) at com.mysql.cj.protocol.a.NativeAuthenticationProvider.proceedHandshakeWithPluggableAuthentication(NativeAuthenticationProvider.java:434) at com.mysql.cj.protocol.a.NativeAuthenticationProvider.connect(NativeAuthenticationProvider.java:209) at com.mysql.cj.protocol.a.NativeProtocol.connect(NativeProtocol.java:1352) at com.mysql.cj.NativeSession.connect(NativeSession.java:132) at com.mysql.cj.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:948) at com.mysql.cj.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:818) ... 74 more
在MySQL JDBC URL中添加允许检索公钥的参数:在
hive-site.xml 文件中的 javax.jdo.option.ConnectionURL 中添加参数 allowPublicKeyRetrieval=true。<property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://anjhon:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=true</value> </property>
启动Hive
- 先更改文件所有者为 hadoop:
chown -R hadoop:hadoop apache-hive-3.1.3-bin hive
- 创建一个hive的日志文件夹:
mkdir /export/server/hive/logs
- 启动元数据管理服务(必须启动,否则无法工作)(在 hive 文件夹中执行)
- 前台启动:
bin/hive --service metastore - 后台启动(推荐):
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 & - 如果想停止该服务,直接 kill 进程即可:
kill -9 <PID>
- 启动客户端,二选一(当前先选择Hive Shell方式)(在 hive 文件夹中执行)
- Hive Shell方式(可以直接写SQL):
bin/hive;退出直接 control + d - Hive ThriftServer方式(不可直接写SQL,需要外部客户端链接使用):
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
Hive 运用
Hive 体验
首先,确保启动了Metastore服务。可以执行:
bin/hive,进入到Hive Shell环境中,可以直接执行SQL语句。# 创建表 CREATE TABLE test(id INT, name STRING, gender STRING); # 插入数据 INSERT INTO test VALUES(1, ‘王力红’, ‘男’), (2, ‘周杰轮’, ‘男’), (3, ‘林志灵’, ‘女’); # 查询数据 SELECT gender, COUNT(*) AS cnt FROM test GROUP BY gender;
验证Hive的数据存储;Hive的数据存储在HDFS的:
/user/hive/warehouse中;hive 的一个数据在 hdfs 中是一个以.db 结尾的文件夹;验证SQL语句启动的MapReduce程序;打开YARN的WEB UI页面查看任务情况:http://anjhon:8088
Hive 客户端
HiveServer2服务
HiveServer2是Hive内置的一个ThriftServer服务,提供Thrift端口供其它客户端链接
HiveServer2启动命令:
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &通过 jps 命令查看服务,其中 RunJar 代表
metastore 和 hiveserver2 服务,会有两个RunJar,可以通过netstat -anp | grep 10000来判断,监听这个端口的就是hiveserver2服务进程;如果需要停止服务,那么直接 kill 进程就行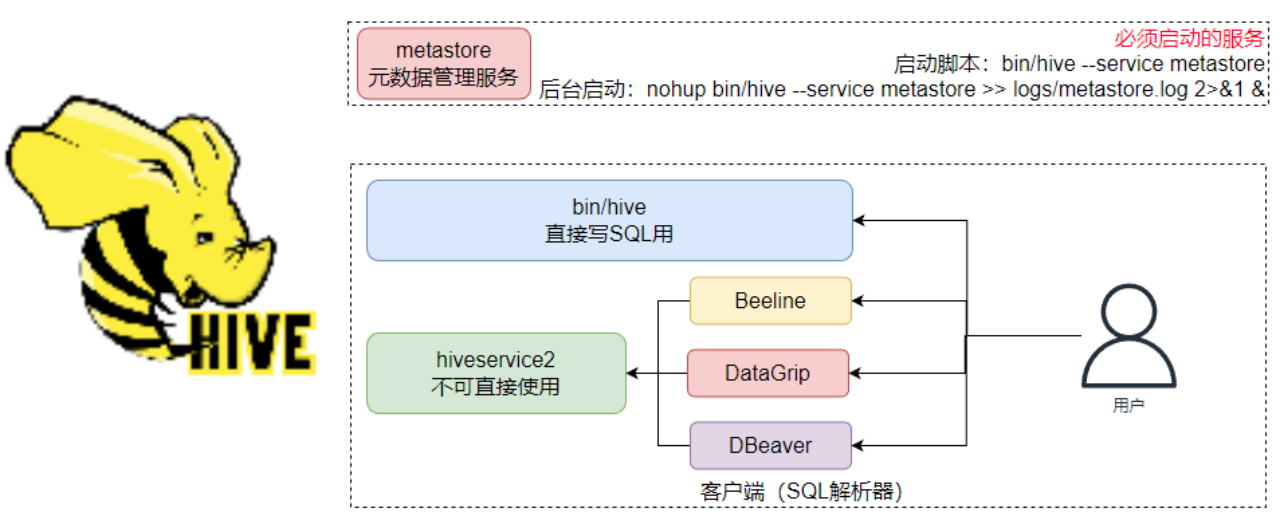
可以连接ThriftServer的客户端有:
- Hive内置的 beeline客户端工具(命令行工具)
- 第三方的图形化SQL工具,如DataGrip、DBeaver、Navicat等
beeline 客户端
- 启动:
bin/beeline
- 连接:
! connect jdbc:hive2://anjhon:10000 - 分析:错误信息
User: hadoop is not allowed to impersonate hadoop,说明用户hadoop仍然没有被允许进行代理操作。 - 解决:
- 检查 Hadoop 配置,确保Hadoop 的
core-site.xml中的代理用户配置正确 - 重启相关服务!!!
用户名 hadoop(其他的也可以,因为在 Hadoop 的配置文件中配置的是 *);密码不用输入(没有设置)
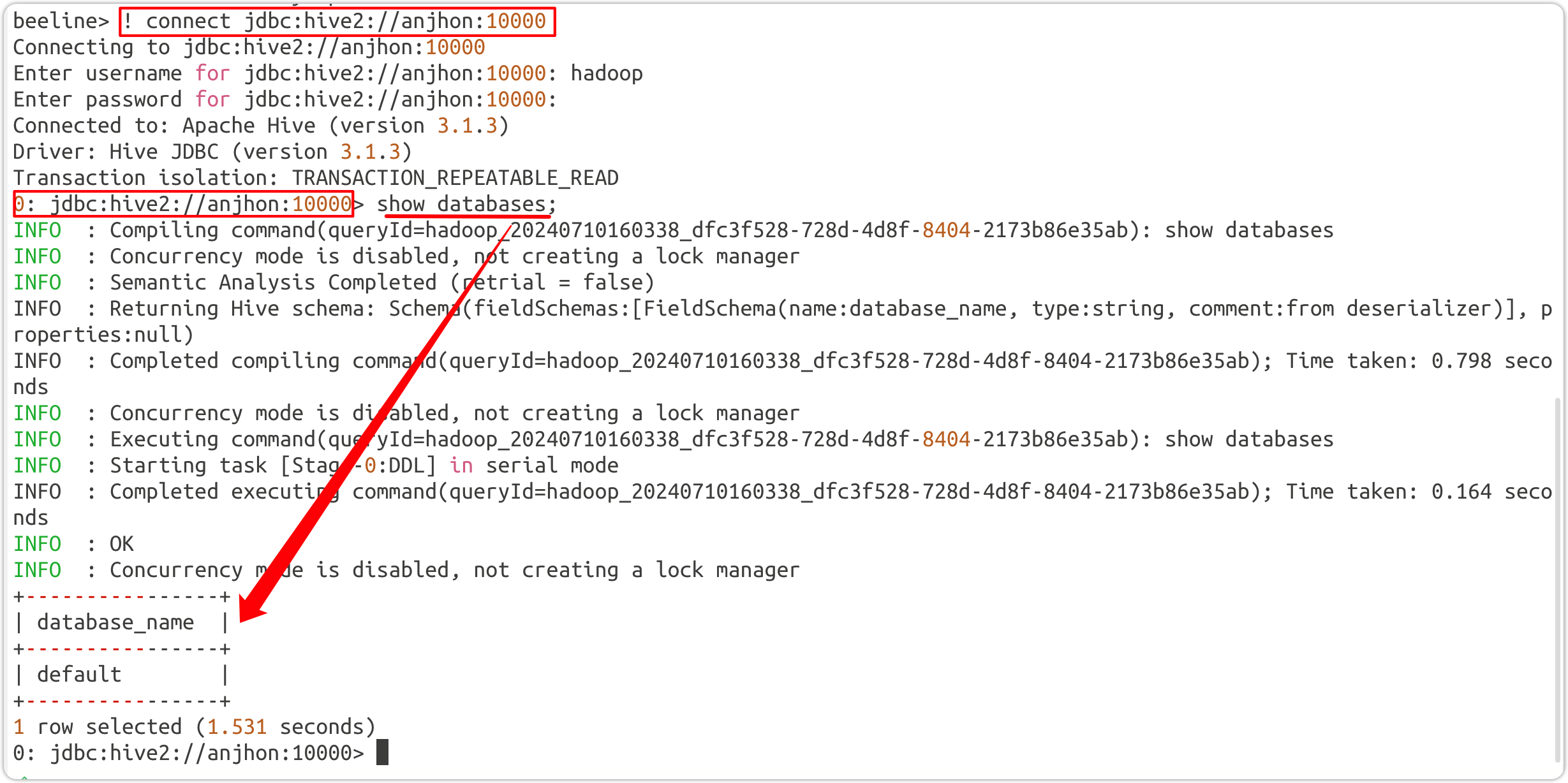
连接时遇到问题:
Error: Could not open client transport with JDBC Uri: jdbc:hive2://anjhon:10000: Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: hadoop is not allowed to impersonate hadoop (state=08S01,code=0)
<property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property>
DataGrip 客户端
略
Dbeaver 客户端
Hive 概念
内部表
内部表:内部表又称管理表,内部表数据存储的位置由hive.metastore.warehouse.dir参数决定(默认:/user/hive/warehouse),删除内部表会直接删除元数据(metadata)及存储数据,因此内部表不适合和其他工具共享数据。
- 优点:便于管理,适合临时或中间计算结果。
- 缺点:删除表时会删除数据,不适合需要长期保存的数据。
-- 正常建表 CREATE database if not exists myhive; use myhive; CREATE table if not exists myhive.stu(id int, name string); INSERT INTO stu values (1,'张三'),(2,'李四'); INSERT INTO stu values (3,'张三'),(4,'李四'); INSERT INTO stu values (5,'张三'),(6,'李四'); INSERT INTO stu values (7,'张三'),(8,'李四'); SELECT * from myhive.stu; -- 自定义分隔符 CREATE table if not exists myhive.stu2(id int, name string) row format delimited fields terminated by '\t'; INSERT INTO myhive.stu2 values (1,'zhangsan'),(2,'lisi'); INSERT INTO myhive.stu2 values (3,'wang'),(4,'liu'); INSERT INTO myhive.stu2 values (5,'zhangsn'),(6,'lsi'); SELECT * FROM myhive.stu2; -- 删除内部表查看元数据是否还在 DROP table if exists myhive.stu; DROP table if exists myhive.stu2;
外部表
外部表:外部表是指表数据可以在任何位置,通过LOCATION关键字指定。 数据存储的不同也代表了这个表在理念是并不是Hive内部管理的,而是可以随意临时链接到外部数据上的。所以,在删除外部表的时候, 仅仅是删除元数据(表的信息),不会删除数据本身。
- 优点:适用于需要长期保存的数据,不会因为误操作而删除数据。
- 缺点:需要手动管理数据的存储位置和生命周期。
-- 1、先创建表,再在 hdfs 中将数据上传到指定文件夹(可行) -- Hive 中的建表语句会自动在 hdfs 中创建location 中的文件夹 CREATE external table if not exists test_ext1(id int, name string) row format delimited fields terminated by '\t' location '/tmp/test_ext1'; SELECT * FROM test_ext1; -- 2、先在 hdfs 中将数据上传到指定文件夹,再创建表(可行) CREATE external table if not exists test_ext2(id int, name string) row format delimited fields terminated by '\t' location '/tmp/test_ext2'; SELECT * FROM test_ext2; -- 3、删除外部表看元数据和数据是否还在 DROP table if exists test_ext1; DROP table if exists test_ext2; -- 内部表和外部表转换 CREATE table if not exists t1 (id int, name string); CREATE external table if not exists t2 (id int, name string) row format delimited fields terminated by '\t' location '/tmp/t2'; desc formatted t1; desc formatted t2; ALTER table t1 set tblproperties ('EXTERNAL'='TRUE'); ALTER table t2 set tblproperties ('EXTERNAL'='FALSE');
分区表
在大数据中,最常用的一种思想就是分治,我们可以把大的文件切割划分成一个个的小的文件,这样每次操作一个小的文件就会很容易了。同样的道理,在hive当中也是支持这种思想的,就是我们可以把大的数据,按照每天,或者每小时进行切分成一个个的小的文件,这样去操作小的文件就会容易得多了。分区通常基于时间、地区等维度。每一个分区,是一个文件夹

- 优点:提高查询性能,适合处理大数据量的表。
- 缺点:分区设计复杂,管理难度较大。
分区表涉及到两个关键字:
PARTITION用于指定具体的分区,如插入、查询、删除、添加时。
PARTITIONED用于在创建表时定义表的分区列。
-- 创建分区表 -- 单级分区 CREATE table if not exists myhive.score (id string, cid string, score int) partitioned by (MONTH string) row format delimited fields terminated by '\t'; SELECT * FROM myhive.score; load data local inpath '/home/hadoop/score.txt' INTO table myhive.score partition(month='202205'); SELECT * FROM myhive.score; -- 多级分区 CREATE table if not exists myhive.score2 (id string, cid string, score int) partitioned by (YEAR string, month string, day string) row format delimited fields terminated by '\t'; SELECT * FROM myhive.score2; load data local inpath '/home/hadoop/score.txt' into table myhive.score2 partition (year='2024', month='05', day='10'); SELECT * FROM myhive.score2;
分桶表
分桶和分区一样,也是一种通过改变表的存储模式,从而完成对表优化的一种调优方式;但和分区不同,分区是将表拆分到不同的子文件夹中进行存储,而分桶是将表拆分到固定数量的不同文件中进行存储。桶表通常和分区表结合使用。每个分区内的数据根据某个列的哈希值分桶。
桶表的数据加载,由于桶表的数据加载通过load data无法执行,只能通过insert select.
如果说分区表的性能提升是:在指定分区列的前提下,减少被操作的数据量,从而提升性能。
分桶表的性能提升就是:基于分桶列的特定操作,如:过滤、JOIN、分组,均可带来性能提升。
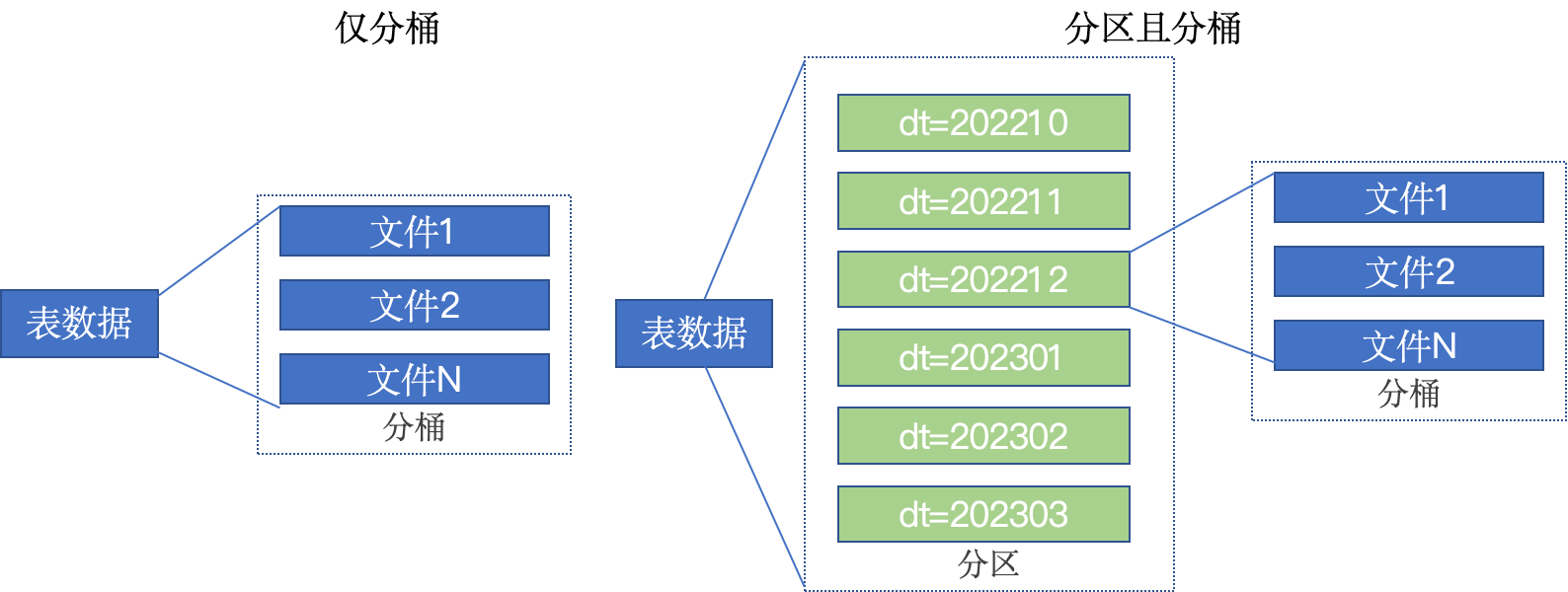
- 优点:可以优化 join 操作,提高查询效率。
- 缺点:设计和管理复杂,需要合理选择分桶列。
# 开启分桶的自动优化(自动匹配reduce task数量和桶数量一致) set hive.enforce.bucketing=true; ## 创建分桶表 CREATE table if not exists myhive.course (c_id string, c_name string, t_id string) clustered by (c_id) into 3 buckets row format delimited fields terminated by '\t'; SELECT * from myhive.course; ## 向分桶表加载数据 -- 1、创建中转表 CREATE table if not exists course_common (c_id string, c_name string, t_id string) row format delimited fields terminated by '\t'; SELECT * from myhive.course_common; -- 2、将数据加载到中转表 load data local inpath '/home/hadoop/course.txt' into table course_common; SELECT * from myhive.course_common; -- 3、将数据从中转表转入分桶表 INSERT overwrite table course select * FROM course_common cluster by (c_id); SELECT * from myhive.course;
桶表需要设置cluster by参数的原因
- 优化查询性能
通过将数据分桶,特别是将某个或某些列的数据哈希值相同的行存储在同一个桶中,可以显著提高查询性能。尤其是在执行基于桶列的
JOIN 操作或 GROUP BY 操作时,分桶后的数据可以减少数据扫描和分区操作,提高查询效率。- 数据均匀分布
- 哈希函数的均匀性
- 取模操作的均匀性
- 数据样本的独立性和随机性
CLUSTERED BY 参数会指定一个或多个列,这些列的数据将被哈希并分配到不同的桶中。这样可以确保数据均匀分布在所有桶中,避免数据倾斜,从而提高数据存储和查询的性能。如果没有分桶设置,插入(加载)数据只是简单的将数据放入到:表的数据存储文件夹中(没有分区)或者表指定分区的文件夹中(带有分区);一旦有了分桶设置,比如分桶数量为3,那么,表内文件或分区内数据文件的数量就限定为3;当数据插入的时候,需要一分为3,进入三个桶文件内。问题就在于:如何将数据分成三份,划分的规则是什么?
数据均匀分布的原理和方法:
在创建分桶表的时候会指定桶的数量和分桶列,在导入数据的时候,会对分桶列的数据进行哈希编码,然后对编码后的哈希值对桶的数量进行取模,如果桶的数量为 3,那取模后的值只会在 [0,1,2,]之间,这几个值也可以看作是桶的标签,此时就可以将数据插入到对应的桶中。由于哈希函数的均匀性,是的数据能大致均匀的分布在 3 个桶中。
同时,由于同样的值被Hash加密后的结果是一致的(哈希函数的性质),所以如果多条数据的分同列的值是一样的,那么这些数据会被分到同一个桶中。这样的好处就是,在查询时如果涉及到过滤查询,连表查询,分组查询,能很容易排除大部分的桶,提升查询效率。
另外,由于load data语句不会触发MapReduce,也就无法进行哈希取模运算,所以不能用于分桶表的数据导入;而insert select语句可以触发MapReduce,因此可以用于分桶表的数据导入方法。
哈希取模的方法为什么能保证数据均匀分布到多个桶中?
哈希函数的设计目标是将输入数据均匀地分布到哈希空间中。对于一个好的哈希函数,不同输入值会生成相对均匀分布的哈希值。这种均匀性确保了输入数据不会聚集在少数几个哈希值上,而是分散到整个哈希空间。
在哈希值基础上进行取模操作,将哈希空间均匀地映射到桶的数量上。例如,如果有 4 个桶,哈希值在取模 4 后的结果会是 0、1、2、3 这四个值中的一个。由于哈希函数的均匀性,这些值在理想情况下会均匀分布在 0 到 3 之间。
假设数据样本的值是独立且随机的,那么输入到哈希函数的数据也将表现出相似的独立和随机特性。这种独立性和随机性进一步增强了哈希取模结果的均匀分布特性。
- 优化 MapReduce 任务
在 Hadoop 的 MapReduce 任务中,桶表可以减少数据的分区和排序步骤。例如,在两个桶表进行
JOIN 操作时,如果两个表是按照相同的列进行分桶的,Hive 可以直接利用这些桶来进行 JOIN 操作,而不需要额外的分区和排序,从而提高任务的执行效率。- 实现高效的采样
分桶表的一个重要应用场景是数据采样。在数据量非常大的情况下,可以通过桶表来实现高效的数据采样。Hive 提供了
TABLESAMPLE 子句,可以基于桶来进行数据采样,从而快速获取样本数据进行分析。- 兼容 ACID 操作
在 Hive 支持的 ACID(原子性、一致性、隔离性、持久性)操作中,桶表也是非常重要的。对于支持 ACID 的表,分桶可以帮助提高事务操作的效率,因为数据的分布和管理变得更加系统化和高效。
临时表
临时表的生命周期仅限于当前会话,不能被其他会话访问。临时表不会存储在 HDFS 上。
- 优点:适用于临时数据处理,不需要清理数据。
- 缺点:只能在当前会话中使用,不能持久化。
视图
视图是基于一个或多个基础表的查询结果的虚拟表,视图本身不存储数据。
- 优点:简化复杂查询,增强数据抽象层次。
- 缺点:视图的性能依赖于底层表的性能。
Hive 语法
笔记语法说明
CREATE DATABASE [IF NOT EXISTS] db_name [LOCATION] 'path'; SELECT expr, ... FROM tbl ORDER BY col_name [ASC | DESC] (A | B | C)
如上语法,在语法描述中出现:
[],表示可选,如上[LOCATION]表示可写、可不写
|,表示或,如上ASC | DESC,表示二选一
- ...,表示序列,即未完结,如上
SELECT expr, ...表示在SELECT后可以跟多个expr(查询表达式),以逗号隔开
(),表示必填,如上(A | B | C)表示此处必填,填入内容在A、B、C中三选一
一些遇到的坑
- 等号两边最好加空格,否则一些解析器无法识别;
- from 前的最后一个字段后不能写逗号;
- group by 后面接分号会报错(在 DBeaver 中),执行时不选择分号。
DDL操作
数据库操作
SHOW DATABASE; # 显示所有数据库 SHOW DATABASES like 'hive*'; # 显示所有 hive 开头的数据库 -- SHOW 语句当中的 LIKE 子句只支持 *(通配符)和 |(条件或)两个符号。 USE myhive; # 切换数据库 SELECT current_database(); # 查询当前USE的数据库 DESC DATABASE myhive; # 查看数据库信息 DESC DATABASE EXTENDED myhive; # EXTENDED 表示是否显示额外属性 ### 创建数据库 # 语法 CREATE DATABASE [IF NOT EXISTS] db_name [LOCATION position] [COMMENT database_comment] [WITH DBPROPERTIES (property_name=property_value, ...)]; -- [IF NOT EXISTS]:则只有在该数据库或模式不存在的情况下才会创建,否则不会执行创建操作。 -- [COMMENT database_comment]:添加一个注释来描述这个数据库或模式,注释内容为 database_comment。 -- [LOCATION hdfs_path]:指定数据库或模式在 Hadoop 分布式文件系统(HDFS)上的存储位置,路径为 hdfs_path。 -- [WITH DBPROPERTIES (property_name=property_value, ...)]:为数据库或模式指定一些额外的属性,这些属性以键值对的形式列出,比如 property_name=property_value。 # 示例: CREATE DATABASE IF NOT EXISTS myhive; # 如果数据库不存在则创建 CREATE DATABASE myhive2 LOCATION '/user/hive/myhive2'; # 创建时指定数据库位置 CREATE DATABASE IF NOT EXISTS my_database COMMENT 'This is my database' LOCATION 'hdfs://namenode:8020/user/hive/warehouse/my_database' WITH DBPROPERTIES ('creator'='user', 'created_date'='2024-07-11'); ### 删除数据库 # 语法 DROP DATABASE [IF EXISTS] database_name [RESTRICT|CASCADE]; -- 默认行为是 RESTRICT,如果数据库中存在表则删除失败。要想删除库及其中的表,可以使用 CASCADE 级联删除。 DROP DATABASE myhive; DROP DATABASE myhive2 CASCADE; # 如果数据库中有表,则需要加cascade参数强制删除
数据表操作
SHOW TABLES; # 显示数据表列表 SHOW TABLES IN default; # 显示default数据库中数据表列表 SHOW PARTITIONS table_name; # 显示表的分区列表 SHOW CREATE TABLE ([db_name.]table_name|view_name); # 显示建表/建视图的语句 DESC table_name; DESC EXTENDED table_name; # EXTENDED 表示是否显示额外属性 DESC FORMATTED table_name; # 显示表的详细信息,通过 Table Type能看出是外部表还是内部表,内部表显示 MANAGED_TABLE,外部表显示 EXTERNAL_TABLE
常用的数据类型
分类 | 数据类型 | 描述 | 示例 | 使用频率 |
基本数据类型 | STRING | 可变长的字符串 | 'Hello, World!' | 非常高 |
ㅤ | INT | 32位整数 | 123 | 非常高 |
ㅤ | BIGINT | 64位整数 | 123456789012345 | 高 |
ㅤ | FLOAT | 单精度浮点数 | 3.14 | 中等 |
ㅤ | DOUBLE | 双精度浮点数 | 3.141592653589793 | 高 |
ㅤ | BOOLEAN | 布尔类型 | TRUE | 中等 |
ㅤ | TINYINT | 8位整数 | 127 | 低 |
ㅤ | SMALLINT | 16位整数 | 32767 | 低 |
ㅤ | TIMESTAMP | 时间戳 | '2024-07-15 12:34:56' | 高 |
ㅤ | DATE | 日期类型 | '2024-07-15' | 中等 |
集合数据类型 | ARRAY | 一组有序的元素 | ARRAY[1, 2, 3] | 中等 |
ㅤ | MAP | 键值对集合 | MAP('key1', 'value1', 'key2', 'value2') | 中等 |
ㅤ | STRUCT | 结构体,可以在一个列中存入多个子列,每个子列允许设置类型和名称 | STRUCT('name', 'John', 'age', 30) | 中等 |
复杂数据类型 | UNIONTYPE | 包含多种类型的字段 | UNIONTYPE<INT, STRING> | 较低 |
数据类型建表示例
CREATE TABLE example_table ( id INT, name STRING, salary DOUBLE, hire_date DATE, is_active BOOLEAN, department STRUCT<dept_name: STRING, dept_id: INT>, skills ARRAY<[STRING | int | data | ... ]>, properties MAP<STRING, STRING> ) row format delimited fields terminated by '\t'; # 表示列分隔符是\t -- ARRAY 类型 CREATE table if not exists test_array (cid string, work_place array<string>) row format delimited fields terminated by '\t' collection items terminated by ','; # 表示集合(array)元素的分隔符是逗号 load data local inpath '/home/hadoop/data_for_array_type.txt' into table test_array; SELECT * FROM test_array as ta ; SELECT cid, work_place[0] from test_array; # 查询 array 数组中的第一个值 SELECT cid, work_place[2] from test_array; SELECT cid, SIZE(work_place) from test_array; # 查询 array 数组的长度 SELECT * FROM test_array as ta WHERE ARRAY_CONTAINS(work_place, 'tianjin') ; # 查询 array 数组中是否包含某个值 -- MAP 类型 CREATE table if not exists test_map (id int, name string, members map<string,string>, age int) row format delimited fields terminated by ',' collection items terminated by '#' map keys terminated by ':'; load data local inpath '/home/hadoop/data_for_map_type.txt' into table test_map; SELECT * FROM test_map ; SELECT id,name,members['father'] FROM test_map as tm ; SELECT id,name,members['mother'] FROM test_map as tm ; SELECT map_keys(members) from test_map as tm ; # 取出全部 key ,返回 array 类型 SELECT map_values(members) from test_map as tm ; # 取出全部 value ,返回 array 类型 SELECT id,name,size(members) from test_map; # 获取键值对个数 SELECT * FROM test_map as tm WHERE ARRAY_CONTAINS(map_keys(members), 'sister'); # 查看谁有 sister 键 SELECT * FROM test_map as tm WHERE ARRAY_CONTAINS(map_values(members), '王林'); # 查看谁有 王林 值 -- STRUCT 类型 CREATE table if not exists test_struct (id string, info struct<name:string, age:int>) row format delimited fields terminated by '#' collection items terminated by ':'; load data local inpath '/home/hadoop/data_for_struct_type.txt' into table test_struct; SELECT * FROM test_struct as ts ; SELECT id, info.name from test_struct as ts ; # 查看二级列的 name SELECT id, info.age from test_struct as ts ; # 查看二级列的 age
创建数据表
## 语法 CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [SKEWED BY (col_name, ...) ON ([(col_value, ...), ...|COLUMN_NAME), ...])] [ROW FORMAT DELIMITED FIELDS TERMINATED BY ''] [STORED AS file_format | STORED BY 'storage_handler_class' [WITH SERDEPROPERTIES (...)]] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value, ...)] [AS select_statement] -- [TEMPORARY]:创建临时表 -- [EXTERNAL]:创建的是外部表; -- [IF NOT EXISTS]:表示如果表已经存在则不会重新创建。 -- [db_name.]:指定数据库 -- [COMMENT table_comment]:为表添加注释。 -- [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]:定义分区列。 -- [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]:定义分桶列,并指定排序方式和桶的数量。 -- [SKEWED BY (col_name, ...) ON ([(col_value, ...), ...|COLUMN_NAME), ...])]:定义倾斜列及其值。 -- [ROW FORMAT DELIMITED FIELDS TERMINATED BY '']:定义行的存储格式(指定分隔符)。 -- [STORED AS file_format | STORED BY 'storage_handler_class' [WITH SERDEPROPERTIES (...)]:定义存储格式或存储处理程序及其属性。 -- [LOCATION hdfs_path]:指定表的存储位置。 -- [TBLPROPERTIES (property_name=property_value, ...)]:为表指定额外的属性。 -- [AS select_statement]:通过一个查询结果来创建表。 ## 示例 # 创建内部表 CREATE TABLE emp(empno INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t"; # 创建外部表(表名尽量和文件路径一致) CREATE EXTERNAL TABLE test_ext(id int) COMMENT 'external table' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION 'hdfs://node1:8020/tmp/test_ext'; -- 1、先创建表,再在 hdfs 中将数据上传到指定文件夹(可行) -- Hive 中的建表语句会自动在 hdfs 中创建location 中的文件夹 CREATE external table if not exists test_ext1(id int, name string) row format delimited fields terminated by '\t' location '/tmp/test_ext1'; SELECT * FROM test_ext1; -- 2、先在 hdfs 中将数据上传到指定文件夹,再创建表(可行) CREATE external table if not exists test_ext2(id int, name string) row format delimited fields terminated by '\t' location '/tmp/test_ext2'; SELECT * FROM test_ext2; # 创建分区表 CREATE TABLE test_ext(id int) COMMENT 'partitioned table' PARTITIONED BY(year string, month string, day string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; # 创建分桶表 CREATE TABLE course (c_id string,c_name string,t_id string) CLUSTERED BY(c_id) INTO 3 BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; # 从查询结果中建表 CREATE TABLE emp_copy AS SELECT * FROM emp WHERE deptno='20'; # 复制表结构 CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name --创建表表名 LIKE existing_table_or_view_name --被复制表的表名 [LOCATION hdfs_path]; --存储位置 CREATE TABLE tbl_name LIKE other_tbl;
删除/清空数据表
TRUNCATE TABLE table_name [PARTITION (partition_column = partition_col_value, ...)]; -- [PARTITION partition_spec]:可选。指定要清空的分区。 TRUNCATE TABLE employee; TRUNCATE TABLE sales PARTITION (year=2023, month=7); -- TRUNCATE TABLE 操作通常比 DELETE 语句更高效,因为它不会产生日志记录。 -- TRUNCATE TABLE 语句通常不能用于外部表。这是因为外部表的数据由外部系统管理,Hive 对其数据的管理权限有限。外部表执行时会抛出异常 Cannot truncate non-managed table XXXX。 DROP TABLE [IF EXISTS] table_name [PURGE]; -- [PURGE]:可选。如果指定,表的数据会被立即永久删除,而不会移动到回收站。 -- 内部表:不仅会删除表的元数据,同时会删除 HDFS 上的数据; -- 外部表:只会删除表的元数据,不会删除 HDFS 上的数据; -- 删除视图引用的表时,不会给出警告(但视图已经无效了,必须由用户删除或重新创建)。
修改数据表
### 修改表的列 ## 添加列 ALTER TABLE table_name ADD COLUMNS (col_name data_type [COMMENT col_comment], ...); ALTER TABLE employee ADD COLUMNS (email STRING COMMENT 'Employee email'); ## 替换列 ALTER TABLE table_name REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...); ALTER TABLE employee REPLACE COLUMNS (id INT, name STRING, age INT, salary FLOAT, email STRING); ## 修改列名和类型 ALTER TABLE table_name CHANGE COLUMN old_col_name new_col_name data_type [COMMENT col_comment]; ALTER TABLE employee CHANGE COLUMN name full_name STRING COMMENT 'Employee full name'; ALTER TABLE emp_temp CHANGE COLUMN sal sal_new DECIMAL(7,2) AFTER ename; -- 修改字段 sal 的名称 并将其放置到 ename 字段后 ALTER TABLE emp_temp CHANGE COLUMN mgr mgr_new INT COMMENT 'this is column mgr'; -- 为字段增加注释 ALTER TABLE emp_temp CHANGE COLUMN empno empno_new INT; ALTER TABLE table_name CHANGE COLUMN col_name col_name new_data_type [COMMENT col_comment]; ALTER TABLE employee CHANGE COLUMN salary salary DOUBLE COMMENT 'Employee salary'; ### 修改表的属性 ## 重命名表 ALTER TABLE old_table_name RENAME TO new_table_name; ALTER TABLE employee RENAME TO employee_details; ## 添加/更新表属性 ALTER TABLE table_name SET TBLPROPERTIES (property_name=property_value, ...); ALTER TABLE employee SET TBLPROPERTIES ('last_updated'='2024-07-11'); ALTER TABLE employee SET TBLPROPERTIES ('EXTERNAL'='TRUE'); # 将表转换为外部表 ALTER TABLE employee SET TBLPROPERTIES ('EXTERNAL'='FALSE'); # 将表转换为内部表 ALTER TABLE employee SET TBLPROPERTIES ('comment'='new_comment'); -- 其他属性参见:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-listTableProperties ### 修改表的存储位置 ## 修改表的数据存储位置 ALTER TABLE table_name SET LOCATION 'hdfs_path'; ALTER TABLE employee SET LOCATION 'hdfs://namenode:8020/user/hive/warehouse/employee_new'; ## 修改分区的数据存储位置 ALTER TABLE table_name PARTITION (partition_spec) SET LOCATION 'hdfs_path'; ALTER TABLE sales PARTITION (year=2023, month=7) SET LOCATION 'hdfs://namenode:8020/user/hive/warehouse/sales_2023_07'; ### 修改表的分区(不建议修改分区) ## 添加分区 ALTER TABLE table_name ADD PARTITION (partition_spec) [LOCATION 'hdfs_path']; ALTER TABLE sales ADD PARTITION (year=2024, month=1) LOCATION 'hdfs://namenode:8020/user/hive/warehouse/sales_2024_01'; ## 删除分区 ALTER TABLE table_name DROP PARTITION (partition_spec); ALTER TABLE sales DROP PARTITION (year=2023, month=7); ### 修改表的格式 ## 修改行格式 ALTER TABLE table_name SET ROW FORMAT row_format; ALTER TABLE employee SET ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; ## 修改存储格式 ALTER TABLE table_name [PARTITION (partition_spec)] SET FILEFORMAT file_format; ALTER TABLE employee SET FILEFORMAT ORC;
DML操作
加载数据

### 语法: LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]; -- LOCAL 表示从本地文件系统中加载数据,如果省略则表示从HDFS中加载数据 -- filepath 为文件路径,可以是本地文件路径或者HDFS路径 -- OVERWRITE 表示覆盖表中的现有数据,如果省略则表示追加数据 -- PARTITION 表示将数据加载到指定的分区中 ### 示例 # 从本地文件系统加载数据到表中 LOAD DATA LOCAL INPATH '/home/user/data/employee_data.txt' INTO TABLE employee; LOAD DATA LOCAL INPATH '/home/user/data/employee_data.txt' OVERWRITE INTO TABLE employee; # 从HDFS加载数据到表中 LOAD DATA INPATH '/user/hive/warehouse/employee_data.txt' INTO TABLE employee; LOAD DATA INPATH '/user/hive/warehouse/employee_data.txt' OVERWRITE INTO TABLE employee; # 从本地文件系统加载数据到指定分区中 LOAD DATA LOCAL INPATH '/home/user/data/sales_data.txt' INTO TABLE sales_data PARTITION (year=2024, month=7); LOAD DATA LOCAL INPATH '/home/user/data/sales_data.txt' OVERWRITE INTO TABLE sales_data PARTITION (year=2024, month=7); # 从HDFS加载数据到指定分区中 LOAD DATA INPATH '/user/hive/warehouse/sales_data.txt' INTO TABLE sales_data PARTITION (year=2024, month=7); LOAD DATA INPATH '/user/hive/warehouse/sales_data.txt' OVERWRITE INTO TABLE sales_data PARTITION (year=2024, month=7);
-- 加载数据 load data local inpath '/home/hadoop/search_log.txt' into table myhive.test_load; SELECT * FROM myhive.test_load as tl ; load data inpath '/tmp/search_log.txt' into table myhive.test_load; SELECT * FROM myhive.test_load as tl ; # 注意,基于HDFS进行load加载数据,源数据文件会消失(本质是被移动到表所在的目录中) load data local inpath '/home/hadoop/search_log.txt' overwrite into table myhive.test_load; SELECT * FROM myhive.test_load as tl ;
插入数据
INSERT语句会调用 mapreduce,,小数据集插入数据会较慢
### 语法: INSERT [OVERWRITE | INTO] TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) ([(column1, column2, ...)] VALUES (value1, value2, ...) | select_statement); -- OVERWRITE 覆盖 -- INTO 追加 -- PARTITION 分区 -- VALUES 可以直接插入值, -- select_statement 也可以插入从其他表查询出来的内容 ### 示例 # 追加/覆盖插入所有列 INSERT INTO TABLE employee_data VALUES (1, 'Alice', 'Engineering'), (2, 'Bob', 'HR'); INSERT OVERWRITE TABLE employee_data VALUES (1, 'Alice', 'Engineering'), (2, 'Bob', 'HR'); # 追加/覆盖插入指定列 INSERT INTO TABLE employee (name, age, department) VALUES ('John Doe', 30, 'Sales'); INSERT OVERWRITE TABLE employee (name, age, department) VALUES ('John Doe', 30, 'Sales'); # 在指定的分区中追加/覆盖插入所有列 INSERT INTO TABLE sales_data PARTITION (year=2024, month=7) VALUES (3, 'ProductC', 200.0), (4, 'ProductD', 250.0); # 静态分区(一次只能插入一个分区的值,分区已被指定:PARTITION (year=2024, month=7)) INSERT OVERWRITE TABLE sales_data PARTITION (year=2024, month=7) VALUES (1, 'ProductA', 100.0), (2, 'ProductB', 150.0); # 静态分区 INSERT INTO sales PARTITION (year, month) VALUES (2024, 7, 101, 10, 99.99); # 动态分区,所有列(能一次插入多个分区的数据,分区字段的值由插入数据决定) INSERT OVERWRITE TABLE sales PARTITION (year, month) VALUES (2024, 7, 101, 10, 99.99); # 动态分区,所有列(能一次插入多个分区的数据,分区字段的值由插入数据决定) # 在指定分区中追加/覆盖插入指定列 INSERT INTO TABLE sales_data PARTITION (year=2024, month=7) (product_id, quantity, price) VALUES (101, 10, 99.99); # 静态分区(一次只能插入一个分区的值,分区已被指定:PARTITION (year=2024, month=7)) INSERT OVERWRITE TABLE sales_data PARTITION (year=2024, month=7) (product_id, quantity, price) VALUES (101, 10, 99.99); # 静态分区 INSERT INTO TABLE sales PARTITION (year, month) (year, month, product_id, quantity, price) VALUES (2024, 7, 101, 10, 99.99); # 动态分区,指定列(能一次插入多个分区的数据,分区字段的值由插入数据决定) INSERT OVERWRITE TABLE sales PARTITION (year, month) (year, month, product_id, quantity, price) VALUES (2024, 7, 101, 10, 99.99); # 动态分区,指定列(能一次插入多个分区的数据,分区字段的值由插入数据决定) # 追加/覆盖插入从其他表查询的数据 INSERT INTO TABLE employee_new (name, age, department) SELECT name, age, department FROM employee WHERE age > 30; INSERT OVERWRITE TABLE employee_new (name, age, department) SELECT name, age, department FROM employee WHERE age > 30; # 在指定分区表中追加/覆盖插入从其他表查询的数据 INSERT INTO TABLE sales_data PARTITION (year=2024, month=7) SELECT id, product_name, sales_amount FROM temp_sales_data WHERE month = 7; INSERT OVERWRITE TABLE sales_data PARTITION (year=2024, month=7) SELECT id, product_name, sales_amount FROM temp_sales_data WHERE month = 7; INSERT INTO TABLE sales_data PARTITION (year, month) SELECT year, month,id, product_name, sales_amount FROM temp_sales_data; INSERT OVERWRITE TABLE sales_data PARTITION (year, month) SELECT year, month,id, product_name, sales_amount FROM temp_sales_data; ## 注意:动态分区插入数据需要设置 SET hive.exec.dynamic.partition = true; # 启用了动态分区。动态分区允许在插入数据时,分区的值可以由插入的数据决定,而不需要在SQL语句中显式地指定分区值。 SET hive.exec.dynamic.partition.mode = nonstrict; # 将动态分区的模式设置为非严格模式(nonstrict)。在非严格模式下,Hive允许分区列不在INSERT语句的PARTITION子句中明确指定,可以通过插入的数据自动确定。相对地,严格模式(strict)要求所有分区列都必须在INSERT语句中明确指定。 ### 数据导出 # 导出数据到hdfs/本地目录 INSERT OVERWRITE DIRECTORY '/user/hive/warehouse/employee_output' SELECT * FROM employee; INSERT OVERWRITE LOCAL DIRECTORY '/home/user/employee_output' SELECT * FROM employee; # 会自动创建文件夹 INSERT OVERWRITE LOCAL DIRECTORY '/home/user/employee_output' row format delimited fields terminated by '\t' SELECT * FROM employee; # 指定分隔符 # 将分区数据导出到hdfs/本地目录 INSERT OVERWRITE DIRECTORY '/user/hive/warehouse/sales_output' SELECT * FROM sales_data WHERE year=2024 AND month=7; INSERT OVERWRITE LOCAL DIRECTORY '/home/user/sales_output' SELECT * FROM sales_data WHERE year=2024 AND month=7;
插入数据报错
执行:INSERT INTO stu2 values (1,'zhangsan'),(2,'lisi'); 报错:org.jkiss.dbeaver.model.sql.DBSQLException: SQL 错误 [1] [08S01]: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.StatsTask
- 背景:在 hive的客户端DBeaver 中,通过建表语句创建好表之后,第一次插入两条数据,可以正常插入没有报错提示,第二次插入两条数据时,会提示
org.jkiss.dbeaver.model.sql.DBSQLException: SQL 错误 [1] [08S01]: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.StatsTask,但是在hdfs 中查看文件时显示有对应的数据文件,并且通过 select 语句查询该表的数据时显示也都能查出第一次和第二次插入的数据。
- 原因:错误出现在执行 StatsTask 时。这个任务通常是在数据加载或插入操作完成后,用来计算表的统计信息。
- 解决:
- 方法一(不推荐):可以通过 set hive.stats.autogather=false; 来暂时禁用自动统计信息收集,然后再尝试插入数据。
- 查询性能:
- 查询计划优化:统计信息对查询计划的优化至关重要。没有统计信息,优化器可能无法生成最优的查询执行计划,导致查询性能下降。
- 索引使用:统计信息有助于优化器决定是否使用索引,没有准确的统计信息可能导致索引使用不当。
- 存储和资源使用:
- 表扫描:缺乏统计信息,查询可能需要扫描更多的数据,从而增加存储和计算资源的使用。
- 内存使用:优化器在缺少统计信息时可能会高估或低估需要的内存,从而影响查询执行的稳定性。
- 维护成本:手动维护:禁用自动统计信息收集后,统计信息需要手动维护,这增加了运维的复杂性和成本。
- 其他方法暂未找到。暂不影响使用。
禁用统计功能的影响:
查询数据
基本语法
SELECT [ALL | DISTINCT]select_expr, select_expr, ... FROM table_reference [WHERE where_condition] [GROUP BYcol_list] [HAVING where_condition] [ORDER BYcol_list] [CLUSTER BYcol_list | [DISTRIBUTE BY col_list] [SORT BY col_list]] [LIMIT number]
建库建表加载数据
CREATE database if not exists itheima; use itheima; CREATE TABLE itheima.orders ( orderId bigint COMMENT '订单id', orderNo string COMMENT '订单编号', shopId bigint COMMENT '门店id', userId bigint COMMENT '用户id', orderStatus tinyint COMMENT '订单状态 -3:用户拒收 -2:未付款的订单 -1:用户取消 0:待发货 1:配送中 2:用户确认收货', goodsMoney double COMMENT '商品金额', deliverMoney double COMMENT '运费', totalMoney double COMMENT '订单金额(包括运费)', realTotalMoney double COMMENT '实际订单金额(折扣后金额)', payType tinyint COMMENT '支付方式,0:未知;1:支付宝,2:微信;3、现金;4、其他', isPay tinyint COMMENT '是否支付 0:未支付 1:已支付', userName string COMMENT '收件人姓名', userAddress string COMMENT '收件人地址', userPhone string COMMENT '收件人电话', createTime timestamp COMMENT '下单时间', payTime timestamp COMMENT '支付时间', totalPayFee int COMMENT '总支付金额' ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; load data local inpath '/home/hadoop/itheima_orders.txt' into table itheima.orders; CREATE TABLE itheima.users ( userId int, loginName string, loginSecret int, loginPwd string, userSex tinyint, userName string, trueName string, brithday date, userPhoto string, userQQ string, userPhone string, userScore int, userTotalScore int, userFrom tinyint, userMoney double, lockMoney double, createTime timestamp, payPwd string, rechargeMoney double ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; load data local inpath '/home/hadoop/itheima_users.txt' into table itheima.users;
基础查询
-- 基础查询 SELECT * FROM orders; SELECT orderid, userid, totalmoney from orders; SELECT count(1) from orders ; SELECT * FROM orders WHERE useraddress LIKE '%广东%'; SELECT * FROM orders WHERE useraddress LIKE '%广东%' order by totalmoney desc limit 1; SELECT ispay, count(1) from orders group by ispay; SELECT userid, username, max(totalmoney) from orders WHERE ispay=1 group by userid,username; SELECT userid, username, avg(totalmoney) from orders group by userid,username; SELECT userid, username, avg(totalmoney) as avg_money from orders group by userid,username HAVING avg_money>10000; SELECT o.orderid, o.userid, u.username, o.totalmoney, o.useraddress, o.paytime FROM itheima.orders o JOIN itheima.users u ON o.userid = u.userid; SELECT o.orderid, o.userid, u.username, o.totalmoney, o.useraddress, o.paytime FROM itheima.orders o LEFT JOIN itheima.users u ON o.userid = u.userid;
RLIKE 语句
-- RLIKE 正则匹配 # 查找广东省的数据 SELECT * FROM orders WHERE useraddress RLIKE '.*广东*.'; # 查找用户地址是:xx省 xx市 xx区的数据 SELECT * FROM orders WHERE useraddress RLIKE '..省 ..市 ..县'; # 查找用户姓为张、王、邓 SELECT * FROM orders WHERE username RLIKE '[张王邓]\\S+'; # 查找手机号符合:188****0*** 规则 SELECT * FROM orders WHERE userphone RLIKE '188\\S{4}0\\d{3}';
UNION 语句
-- UNION 拼接;列的数量和名称必须相同 CREATE TABLE itheima.course(c_id string, c_name string, t_id string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; load data local inpath '/home/hadoop/course.txt' into table itheima.course; SELECT * FROM course; -- union 去重拼接 SELECT * FROM course WHERE t_id='周杰轮' union SELECT * FROM course WHERE t_id='王力鸿'; -- union all 不去重拼接 SELECT * FROM course WHERE t_id='周杰轮' union all SELECT * FROM course WHERE t_id='王力鸿'; -- 字查询嵌套 SELECT t_id, COUNT(*) FROM ( SELECT t_id FROM itheima.course WHERE t_id = '周杰轮' UNION ALL SELECT t_id FROM itheima.course WHERE t_id = '王力鸿' ) AS u GROUP BY t_id; -- insert 中嵌套 UNION ALL CREATE TABLE itheima.course2 LIKE itheima.course; INSERT OVERWRITE TABLE itheima.course2 SELECT * FROM itheima.course UNION ALL SELECT * FROM itheima.course;
SAMPLE快速采样
大数据体系下,表内容一般偏大,小操作也要很久所以如果想要简单看看数据,可以通过抽样快速查看
-- 1、基于随机桶抽样 SELECT username, orderid, totalmoney from orders tablesample(bucket 3 out of 10 on username); # 使用colname(某列的哈希)作为随机依据,则其它条件不变下,每次抽样结果一致 SELECT username, orderid, totalmoney from orders tablesample(bucket 3 out of 10 on rand()); # 使用rand()(整行的哈希)作为随机依据,每次抽样结果都不同 -- 2、基于数据块抽样 —— 不随机,只是按照数据顺序从前向后取。 SELECT username, orderid, totalmoney from orders tablesample(10 rows); # 取前 10 条 SELECT username, orderid, totalmoney from orders tablesample(10 percent); # 取前 10% SELECT username, orderid, totalmoney from orders tablesample(10k); # 取前 10kb SELECT username, orderid, totalmoney from orders tablesample(10m); # 取前 10mb SELECT username, orderid, totalmoney from orders tablesample(10g); # 取前 10gb
虚拟列
虚拟列是Hive内置的可以在查询语句中使用的特殊标记,可以查询数据本身的详细参数。
Hive目前可用3个虚拟列:
- INPUT__FILE__NAME,数据文件的完整路径。
- BLOCK__OFFSET__INSIDE__FILE,数据块在文件中的偏移量,该偏移量从文件的起始位置开始计算,以字节为单位。
- 如果某条记录的 BLOCK__OFFSET__INSIDE__FILE 为 256 MB,则表示该记录位于文件的第 256 MB 处。具体位置可能在第二个块(如果块大小为 128 MB)。
- ROW__OFFSET__INSIDE__BLOCK,数据行在块中的偏移量,该偏移量从块的起始位置开始计算,以字节为单位。此虚拟列需要设置:SET hive.exec.rowoffset=true 才可使用
- 假设记录的 ROW__OFFSET__INSIDE__BLOCK 为 1 KB,这表示该记录在块内的偏移量是 1 KB,从块的起始位置向后移动 1 KB 处。
偏移量:偏移量(Offset)是指数据在某个存储介质(如文件、块或数据结构)中的位置。
SET hive.exec.rowoffset=true; SELECT INPUT__FILE__NAME, BLOCK__OFFSET__INSIDE__FILE, ROW__OFFSET__INSIDE__BLOCK from orders; SELECT INPUT__FILE__NAME, BLOCK__OFFSET__INSIDE__FILE, ROW__OFFSET__INSIDE__BLOCK from orders WHERE BLOCK__OFFSET__INSIDE__FILE>100; SELECT INPUT__FILE__NAME, count(1) from itheima.course group by INPUT__FILE__NAME;
常用内置函数
show functions; # 查看有哪些内置函数 describe function extended abs; # 查看具体函数的具体信息 -- 1、数值函数 SELECT round(3.141592654); # 取整 SELECT round(3.141592654,6); # 保留 6 位小数 SELECT rand(); # 随机数 SELECT rang(3); # 随机数,有随机数种子 SELECT abs(-3); # 求绝对值 SELECT pi(); # 求π -- 2、集合函数 SELECT SIZE(work_place) from test_array; SELECT * from test_array WHERE ARRAY_CONTAINS(work_place,'tianjin') ; # 集合是否包含指定内容 SELECT *,sort_array(work_place) from test_array; # 对集合进行排序 SELECT SIZE(members) from test_map; # 获取键值对的数量 SELECT map_keys(members) from test_map; # 获取所有的键 SELECT map_values(members) from test_map; # 获取所有的值 -- 3、类型转换函数 SELECT BINARY('hadoop'); # 二进制 SELECT CAST('1' as bigint); # 不成功则返回 null -- 4、日期函数 SELECT current_timestamp(); SELECT current_date(); SELECT to_date(current_timestamp()); SELECT year('2024-06-01'); SELECT month('2024-06-01'); SELECT day('2024-06-01'); SELECT quarter('2024-06-01'); SELECT dayofmonth('2024-06-01'); SELECT hour('2024-06-01 10:11:12'); SELECT minute('2024-06-01 10:11:12'); SELECT second('2024-06-01 10:11:12'); SELECT weekofyear('2024-06-01 10:11:12'); SELECT datediff('2024-06-01','2024-06-05'); SELECT date_add('2024-06-01',5); SELECT date_sub('2024-06-01',5); -- 5、条件函数 SELECT if(truename is null, '无名', truename) from itheima.users ; SELECT nvl(truename, '无名') from itheima.users ; # 如果truename这一列的某行为空,则返回默认值,否者返回原值 SELECT isnull(truename) from itheima.users ; SELECT isnotnull(truename) from itheima.users ; SELECT coalesce(truename, brithday) from itheima.users ; # 在每一行的两列中,返回第一个不是空的值 SELECT case username when '周杰轮' then '知名歌星1' when '张鲁依' then '知名歌星2' else '未知' END from itheima.users; SELECT case when username='周杰轮' then '知名歌星1' when username='张鲁依' then '知名歌星2' else '未知' END from itheima.users; SELECT truename, nullif(username, truename) from itheima.users ; # 如果username和truename相等,则返回 null,否则返回username SELECT assert_true (0<1); # 断言,判断条件不为真则直接报错。 -- 6、字符串函数 SELECT CONCAT(loginName,username) from itheima.users; # 拼接两列 SELECT CONCAT(loginName,username,truename) from itheima.users; # 拼接多列 SELECT CONCAT_ws('@',loginName,username) from itheima.users; # 自定义分隔符拼接两列 SELECT CONCAT_ws('@',loginName,username,truename) from itheima.users; # 自定义分隔符拼接多列 SELECT username,LENGTH(username) from itheima.users ; SELECT lower('ABCD'); SELECT upper('abcd'); SELECT trim(' hadoop '); # 去除空格 SELECT split('hadoop, bigdate, hdfs', ','); # 拆分 -- 7、数据脱敏函数 SELECT mask_hash('hadoop'); # 对字符串进行 hash 加密,得到 16 进制 SELECT mask_hash(5); # 如果加密数字,得到 null SELECT hash(5); # hash 加密,得到十进制数字 SELECT hash ('hadoop') # hash 加密,得到十进制数字 -- 8、其他函数 select current_user(); SELECT CURRENT_DATABASE(); SELECT VERSION() ; SELECT md5('hadoop');
实践
-- 建库建表加载数据 CREATE database if not exists db_msg; use db_msg ; create table db_msg.tb_msg_source( msg_time string comment "消息发送时间", sender_name string comment "发送人昵称", sender_account string comment "发送人账号", sender_sex string comment "发送人性别", sender_ip string comment "发送人ip地址", sender_os string comment "发送人操作系统", sender_phonetype string comment "发送人手机型号", sender_network string comment "发送人网络类型", sender_gps string comment "发送人的GPS定位", receiver_name string comment "接收人昵称", receiver_ip string comment "接收人IP", receiver_account string comment "接收人账号", receiver_os string comment "接收人操作系统", receiver_phonetype string comment "接收人手机型号", receiver_network string comment "接收人网络类型", receiver_gps string comment "接收人的GPS定位", receiver_sex string comment "接收人性别", msg_type string comment "消息类型", distance string comment "双方距离", message string comment "消息内容" ); load data local inpath '/home/hadoop/chat_data-5W.csv' into table db_msg.tb_msg_source ; SELECT * FROM tb_msg_source tablesample(10 rows); SELECT count(*) from tb_msg_source ; -- 数据清洗转换到新表中:etl:export transforme load create table db_msg.tb_msg_etl( msg_time string comment "消息发送时间", sender_name string comment "发送人昵称", sender_account string comment "发送人账号", sender_sex string comment "发送人性别", sender_ip string comment "发送人ip地址", sender_os string comment "发送人操作系统", sender_phonetype string comment "发送人手机型号", sender_network string comment "发送人网络类型", sender_gps string comment "发送人的GPS定位", receiver_name string comment "接收人昵称", receiver_ip string comment "接收人IP", receiver_account string comment "接收人账号", receiver_os string comment "接收人操作系统", receiver_phonetype string comment "接收人手机型号", receiver_network string comment "接收人网络类型", receiver_gps string comment "接收人的GPS定位", receiver_sex string comment "接收人性别", msg_type string comment "消息类型", distance string comment "双方距离", message string comment "消息内容", msg_day string comment "消息日", msg_hour string comment "消息小时", sender_lng double comment "经度", sender_lat double comment "纬度" ); SELECT * from db_msg.tb_msg_etl tablesample(10 rows); INSERT overwrite table db_msg.tb_msg_etl SELECT *, date(msg_time) as msg_day, hour(msg_time) as msg_hour, split(sender_gps, ',')[0] as sender_lng, split(sender_gps, ',')[1] as sender_lat FROM db_msg.tb_msg_source WHERE LENGTH(sender_gps) > 0; SELECT * from db_msg.tb_msg_etl tablesample(10 rows); -- 数据统计 -- 1、统计每日消息总量 CREATE table if not exists db_msg.tb_rs_total_msg_cnt comment '每日消息总量' as SELECT msg_day, count(*) as total_msg_cnt from db_msg.tb_msg_etl group by msg_day; -- 2、统计每小时消息量,发送量和接受用户数 CREATE table if not exists db_msg.tb_rs_hour_msg_cnt comment '每小时消息量' as SELECT msg_hour, count(*) as total_msg_cnt, count(DISTINCT sender_name) as sender_usr_cnt, count(DISTINCT receiver_name) as receiver_usr_cnt from db_msg.tb_msg_etl group by msg_hour; -- 3、统计各地区发送消息总量 CREATE table if not exists db_msg.tb_rs_loc_cnt comment '各地区消息总量' as SELECT msg_day, sender_lng, sender_lat, count(*) as total_msg_cnt FROM db_msg.tb_msg_etl group by msg_day, sender_lng, sender_lat; # 在 DBeaver 中,此处加分号会报错,原因未知,执行时不选择分号 SELECT * from db_msg.tb_rs_loc_cnt tablesample(10 rows); -- 4、统计发送消息和接收消息的用户数 CREATE table if not exists db_msg.tb_rs_user_cnt comment '发送消息和接收消息的用户数' as SELECT msg_day, count(DISTINCT sender_name) as sender_usr_cnt, count(DISTINCT receiver_name) as receiver_usr_cnt FROM db_msg.tb_msg_etl group by msg_day; -- 5、统计发送消息最多的 top10 用户 CREATE table if not exists db_msg.tb_rs_sender_top10 comment '发送消息量前十' as SELECT msg_day, sender_name, count(*) as sender_msg_cnt from db_msg.tb_msg_etl group by msg_day, sender_name order by sender_msg_cnt DESC limit 10; -- 6、统计接收消息最多的 top10 用户 CREATE table if not exists db_msg.tb_rs_receiver_top10 comment '接收消息量前十' as SELECT msg_day, receiver_name, count(*) as receiver_msg_cnt from db_msg.tb_msg_etl group by msg_day, receiver_name order by receiver_msg_cnt DESC limit 10; -- 7、统计发送手机型号分布 CREATE table if not exists db_msg.tb_rs_senderphonetype_cnt comment '发送手机型号分布' as SELECT sender_phonetype, count(*) as send_phone_type_cnt FROM db_msg.tb_msg_etl group by sender_phonetype; -- 8、统计接收手机型号分布 CREATE table if not exists db_msg.tb_rs_receiverphonetype_cnt comment '发送手机型号分布' as SELECT receiver_phonetype, count(*) as receiv_phone_type_cnt FROM db_msg.tb_msg_etl group by receiver_phonetype; desc formatted db_msg.tb_rs_senderphonetype_cnt ALTER table db_msg.tb_rs_senderphonetype_cnt set tblproperties('comment'='接收手机型号分布'); -- 9、统计发送人的操作系统分布 CREATE table if not exists db_msg.tb_rs_sender_os_cnt comment '发送人操作系统分布' as SELECT sender_os, count(1) as sender_os_cnt from db_msg.tb_msg_etl group by sender_os
导入导出数据
输出导出
### 语法: EXPORT TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] TO 'export_target_path'; -- TABLE 后跟要导出的表名 -- PARTITION 指定要导出的分区 -- TO 后跟导出数据的目标路径 ### 示例 # 导出表的所有数据到HDFS路径 EXPORT TABLE employee TO '/user/hive/warehouse/export/employee_export'; # 导出表的指定分区数据到HDFS路径 EXPORT TABLE sales_data PARTITION (year=2024, month=7) TO '/user/hive/warehouse/export/sales_data_export_2024_07';
在 hive shell 中导出数据
hive shell 中查询,然后重定向
# 基本语法:(hive -f/-e 执行语句或者脚本 > file) bin/hive -e "select * from myhive.test_load;" > /home/hadoop/export3/export4.txt # -e:执行sql 语句 bin/hive -f export.sql > /home/hadoop/export4/export4.txt # -f:执行sql脚本
数据导入
### 语法: IMPORT [EXTERNAL] TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] FROM 'import_source_path' [LOCATION 'table_location']; -- EXTERNAL 可选,指定为外部表 -- TABLE 后跟要导入的表名 -- PARTITION 指定要导入的分区 -- FROM 后跟导入数据的源路径 -- LOCATION 可选,指定表的存储位置 ### 示例 # 导入表数据从HDFS路径 IMPORT TABLE employee FROM '/user/hive/warehouse/export/employee_export'; # 导入表指定分区数据从HDFS路径 IMPORT TABLE sales_data PARTITION (year=2024, month=7) FROM '/user/hive/warehouse/export/sales_data_export_2024_07'; # 导入为外部表 IMPORT EXTERNAL TABLE employee FROM '/user/hive/warehouse/export/employee_export'; IMPORT EXTERNAL TABLE sales_data PARTITION (year=2024, month=7) FROM '/user/hive/warehouse/export/sales_data_export_2024_07'; # 导入表数据并指定表的存储位置 IMPORT TABLE employee FROM '/user/hive/warehouse/export/employee_export' LOCATION '/user/hive/warehouse/new_employee_location'; # 导入表指定分区数据并指定表的存储位置 IMPORT TABLE sales_data PARTITION (year=2024, month=7) FROM '/user/hive/warehouse/export/sales_data_export_2024_07' LOCATION '/user/hive/warehouse/new_sales_data_location'; # 使用元数据导入表数据 IMPORT TABLE employee FROM '/user/hive/warehouse/export/employee_export' WITH SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' STORED AS TEXTFILE; IMPORT TABLE sales_data PARTITION (year=2024, month=7) FROM '/user/hive/warehouse/export/sales_data_export_2024_07' WITH SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' STORED AS TEXTFILE; ### 注意事项: 1. 如果导入表已经存在,Hive将会返回一个错误。如果需要覆盖表,可以先删除已存在的表。 2. IMPORT语句可以在目标集群上重建导出的表和数据。 3. 如果要导入的表是一个分区表,则需要使用PARTITION子句指定要导入的分区。如果要导入多个分区,可以多次执行IMPORT语句。 4. LOCATION子句可以用来指定表的存储位置,通常在导入外部表时使用。
DCL操作
权限管理
授权
### 语法: GRANT privilege_type [, privilege_type, ...] ON table_or_view_name TO principal_specification [, principal_specification, ...] [WITH GRANT OPTION]; -- privilege_type: 指定授予的权限类型,如SELECT, INSERT, etc. -- table_or_view_name: 指定授予权限的表或视图 -- principal_specification: 指定接收权限的主体,可以是用户或角色 -- WITH GRANT OPTION: 可选,允许接收者将权限授予其他用户或角色 ### 示例 # 授予用户对表的SELECT权限 GRANT SELECT ON TABLE employee TO USER alice; # 授予角色对表的INSERT权限 GRANT INSERT ON TABLE employee TO ROLE data_analyst; # 授予用户对视图的SELECT权限 GRANT SELECT ON VIEW employee_view TO USER bob; # 授予用户对表的多种权限 GRANT SELECT, INSERT ON TABLE employee TO USER charlie; # 授予用户对表的权限,并允许其将权限授予他人 GRANT SELECT ON TABLE employee TO USER david WITH GRANT OPTION; # 授予多个用户对表的权限 GRANT SELECT ON TABLE employee TO USER alice, USER bob; # 授予用户对数据库的所有表的权限 GRANT SELECT ON DATABASE company TO USER alice; # 授予角色对数据库中所有表的权限 GRANT SELECT ON DATABASE company TO ROLE data_analyst; ### 权限类型: -- SELECT: 允许读取表或视图中的数据 -- INSERT: 允许向表中插入数据 -- UPDATE: 允许更新表中的数据 -- DELETE: 允许删除表中的数据 -- CREATE: 允许创建表 -- DROP: 允许删除表 -- ALTER: 允许修改表结构 -- INDEX: 允许在表上创建索引 -- LOCK: 允许对表进行锁定
撤销授权
### 语法: REVOKE privilege_type [, privilege_type, ...] ON table_or_view_name FROM principal_specification [, principal_specification, ...]; -- privilege_type: 指定撤销的权限类型,如SELECT, INSERT, etc. -- table_or_view_name: 指定撤销权限的表或视图 -- principal_specification: 指定被撤销权限的主体,可以是用户或角色 ### 示例 # 撤销用户对表的SELECT权限 REVOKE SELECT ON TABLE employee FROM USER alice; # 撤销角色对表的INSERT权限 REVOKE INSERT ON TABLE employee FROM ROLE data_analyst; # 撤销用户对视图的SELECT权限 REVOKE SELECT ON VIEW employee_view FROM USER bob; # 撤销用户对表的多种权限 REVOKE SELECT, INSERT ON TABLE employee FROM USER charlie; # 撤销多个用户对表的权限 REVOKE SELECT ON TABLE employee FROM USER alice, USER bob; # 撤销用户对数据库的所有表的权限 REVOKE SELECT ON DATABASE company FROM USER alice; # 撤销角色对数据库中所有表的权限 REVOKE SELECT ON DATABASE company FROM ROLE data_analyst; ### 权限类型: -- SELECT: 允许读取表或视图中的数据 -- INSERT: 允许向表中插入数据 -- UPDATE: 允许更新表中的数据 -- DELETE: 允许删除表中的数据 -- CREATE: 允许创建表 -- DROP: 允许删除表 -- ALTER: 允许修改表结构 -- INDEX: 允许在表上创建索引 -- LOCK: 允许对表进行锁定